
This is the 3rd article in a 3-part series:
- A crash course in memory management
- A cartoon intro to ArrayBuffers and SharedArrayBuffers
- Avoiding race conditions in SharedArrayBuffers with Atomics
In the last article, I talked about how using SharedArrayBuffers could result in race conditions. This makes working with SharedArrayBuffers hard. We don’t expect application developers to use SharedArrayBuffers directly.
But library developers who have experience with multithreaded programming in other languages can use these new low-level APIs to create higher-level tools. Then application developers can use these tools without touching SharedArrayBuffers or Atomics directly.
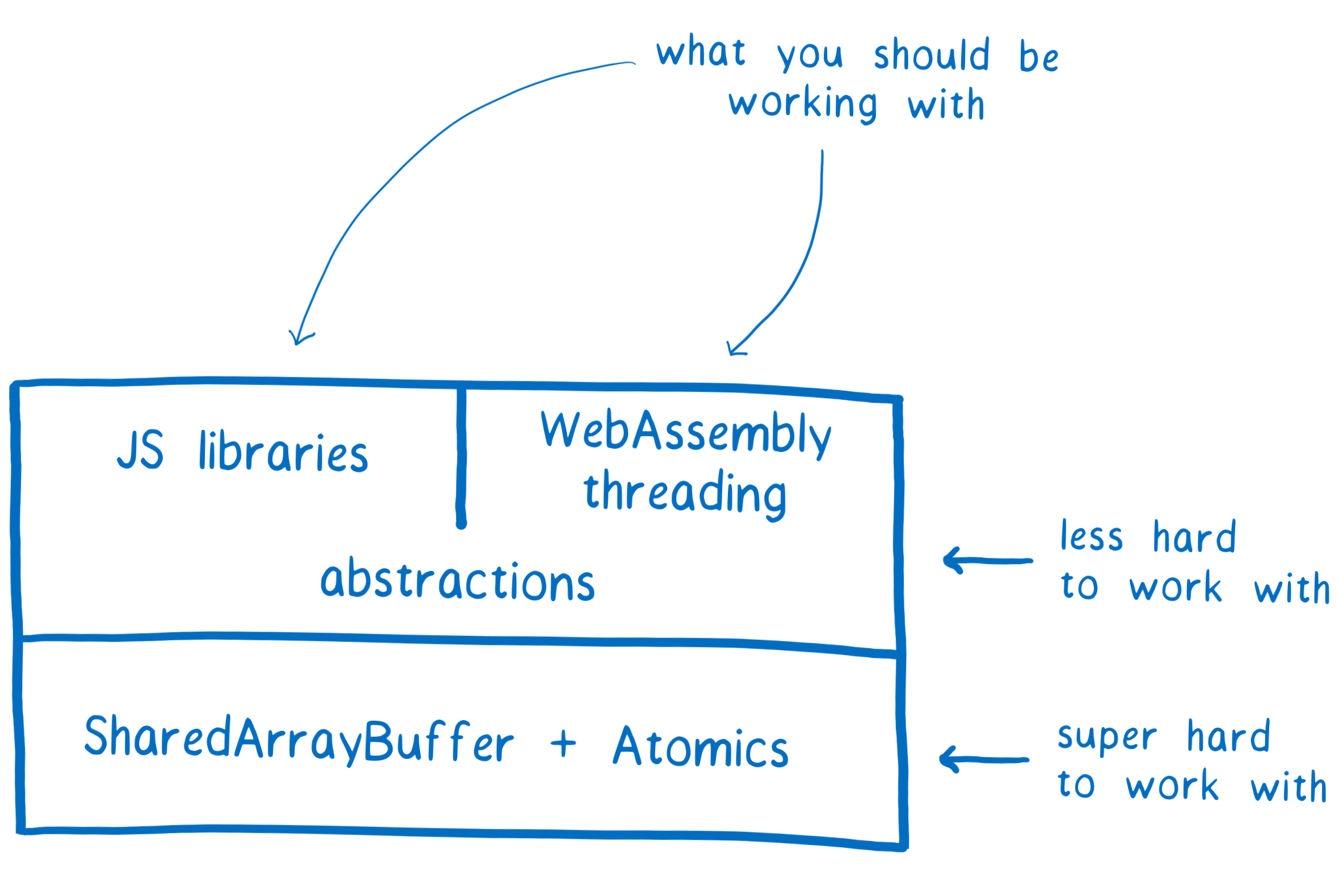
Even though you probably shouldn’t work with SharedArrayBuffers and Atomics directly, I think it’s still interesting to understand how they work. So in this article, I’ll explain what kinds of race conditions concurrency can bring, and how Atomics help libraries avoid them.
But first, what is a race condition?
Race conditions: an example you may have seen before
A pretty straightforward example of a race condition can happen when you have a variable that is shared between two threads. Let’s say one thread wants to load a file and the other thread checks whether it exists. They share a variable, fileExists, to communicate.
Initially, fileExists is set to false.

As long as the code in thread 2 runs first, the file will be loaded.

But if the code in thread 1 runs first, then it will log an error to the user, saying that the file does not exist.

But that’s not the problem. It’s not that the file doesn’t exist. The real problem is the race condition.
Many JavaScript developers have run into this kind of race condition, even in single-threaded code. You don’t have to understand anything about multithreading to see why this is a race.
However, there are some kinds of race conditions which aren’t possible in single-threaded code, but that can happen when you’re programming with multiple threads and those threads share memory.
Different classes of race conditions and how Atomics help
Let’s explore some of the different kinds of race conditions you can have in multithreaded code and how Atomics help prevent them. This doesn’t cover all possible race conditions, but should give you some idea why the API provides the methods that it does.
Before we start, I want to say again: you shouldn’t use Atomics directly. Writing multithreaded code is a known hard problem. Instead, you should use reliable libraries to work with shared memory in your multithreaded code.

With that out of the way…
Race conditions in a single operation
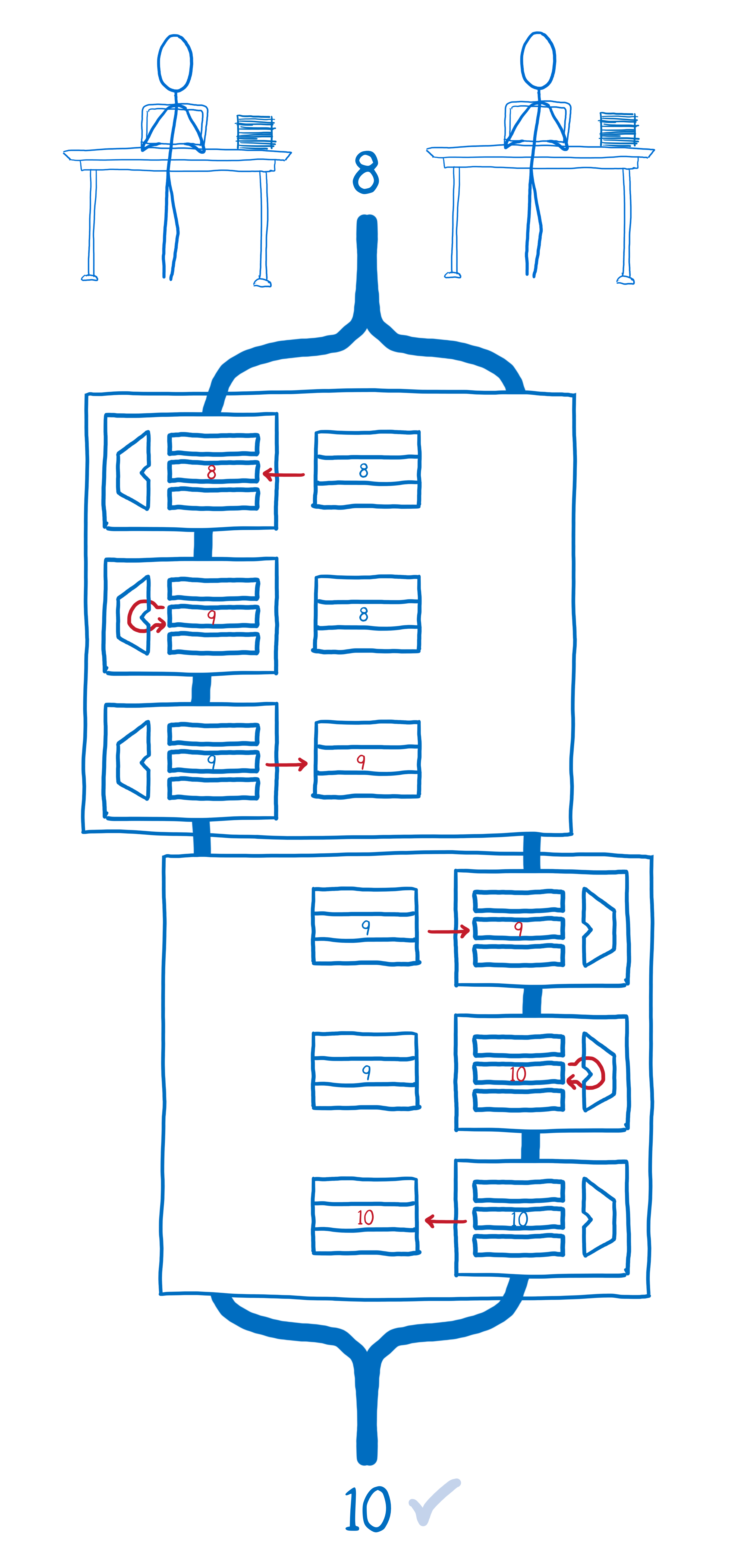
Let’s say you had two threads that were incrementing the same variable. You might think that the end result would be the same regardless of which thread goes first.
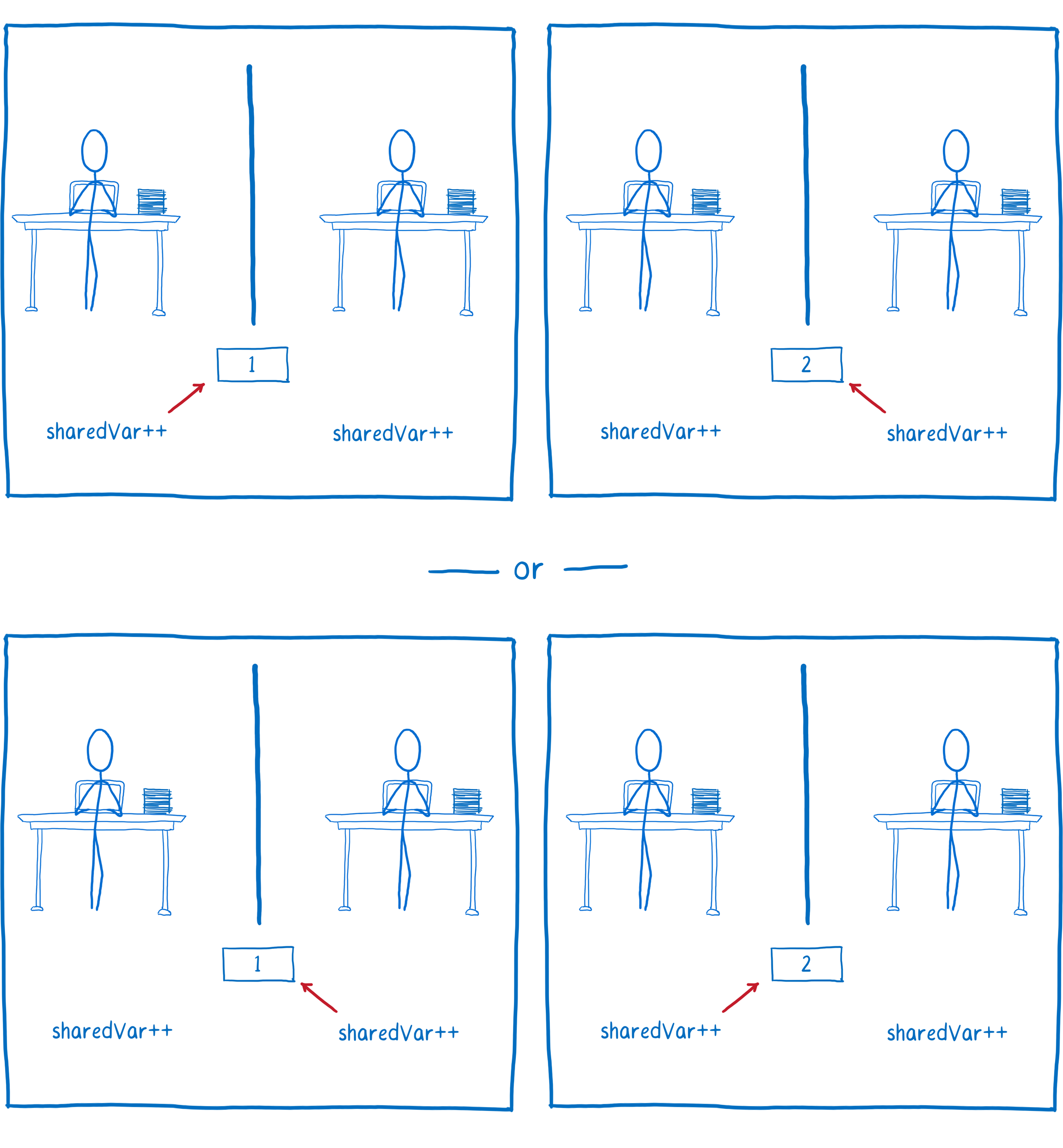
But even though, in the source code, incrementing a variable looks like a single operation, when you look at the compiled code, it is not a single operation.
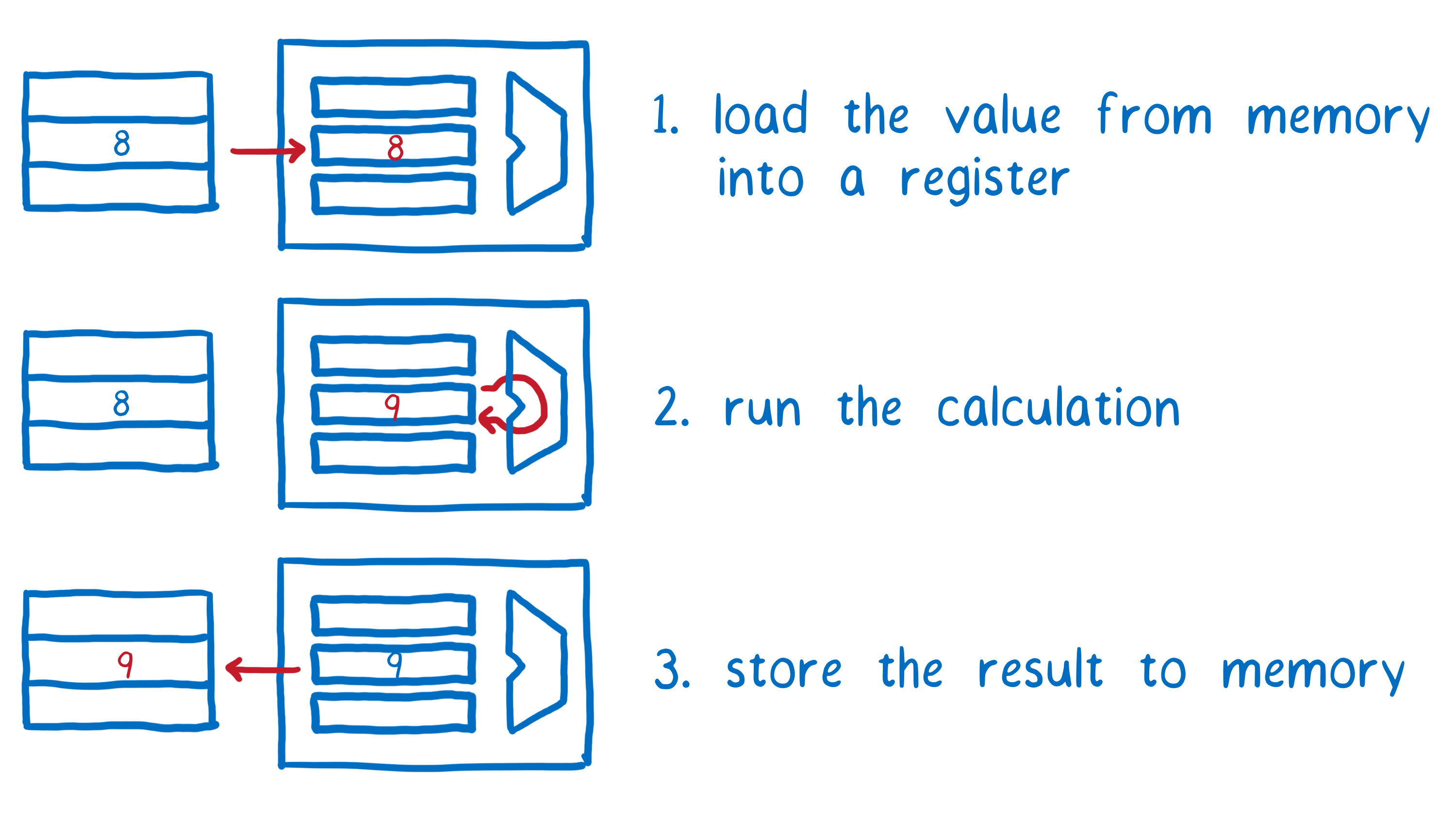
At the CPU level, incrementing a value takes three instructions. That’s because the computer has both long-term memory and short-term memory. (I talk more about how this all works in another article).
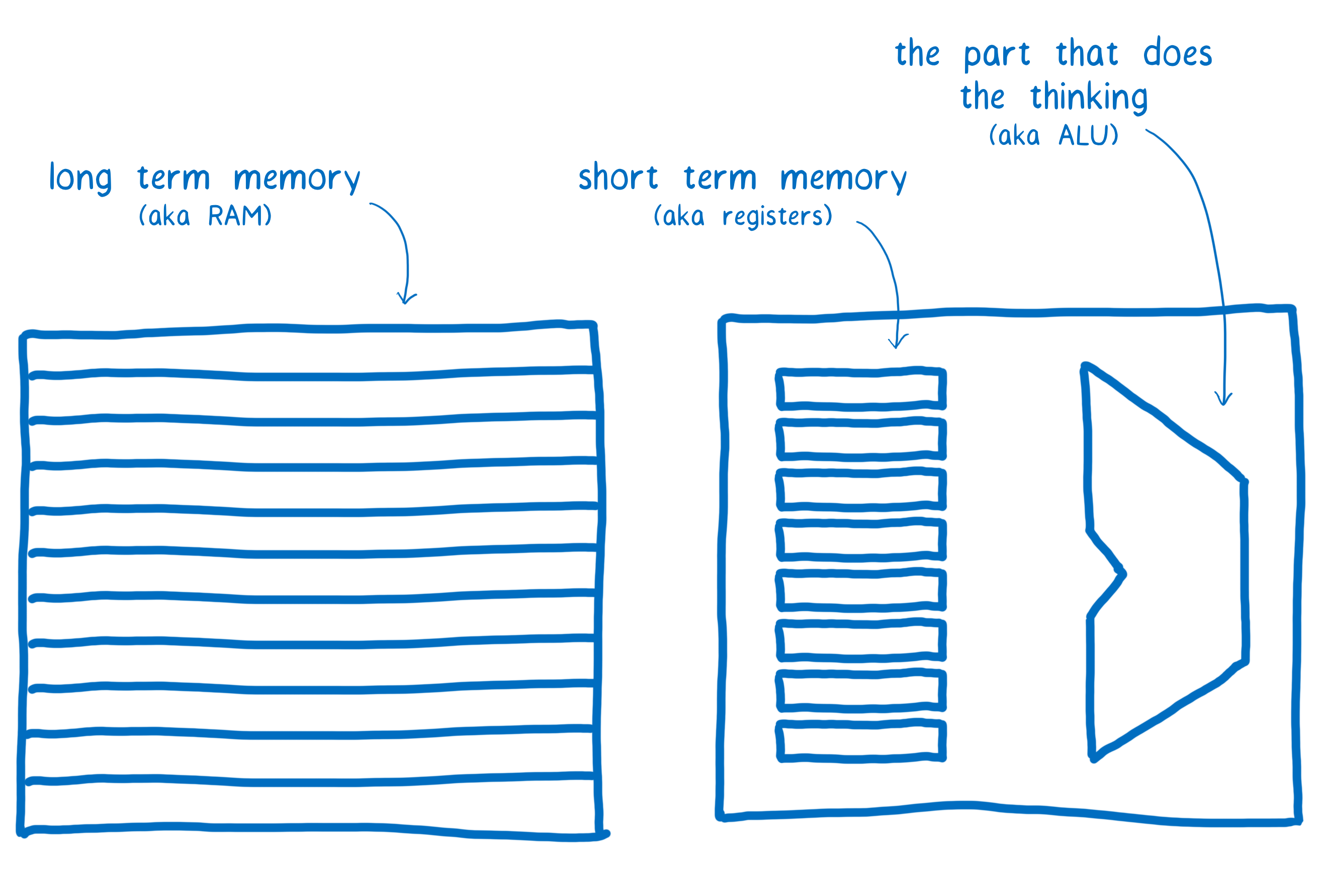
All of the threads share the long-term memory. But the short-term memory—the registers—are not shared between threads.
Each thread needs to pull the value from memory into its short-term memory. After that, it can run the calculation on that value in short-term memory. Then it writes that value back from its short-term memory to the long-term memory.
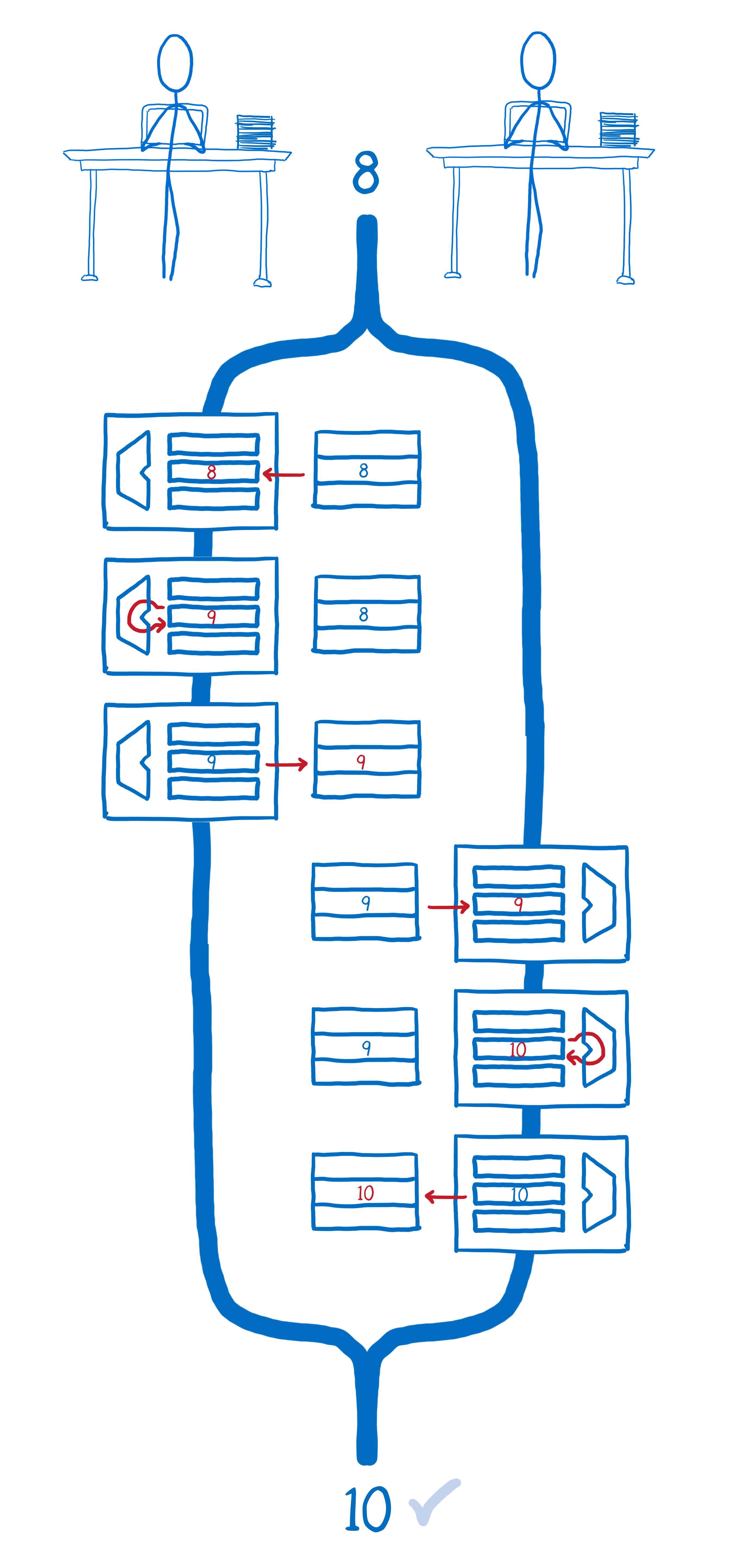
If all of the operations in thread 1 happen first, and then all the operations in thread 2 happen, we will end up with the result that we want.
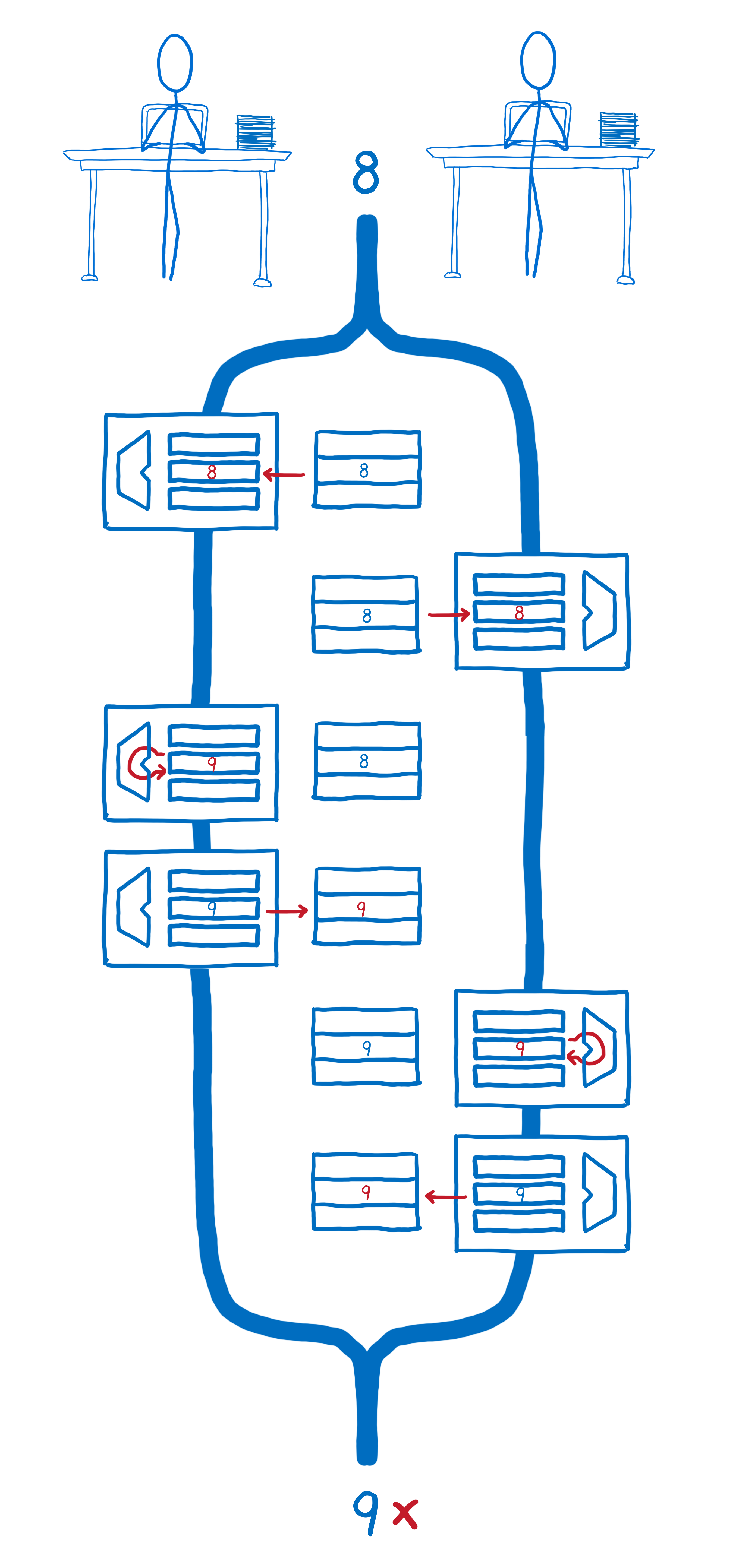
But if they are interleaved in time, the value that thread 2 has pulled into its register gets out of sync with the value in memory. This means that thread 2 doesn’t take thread 1’s calculation into consideration. Instead, it just clobbers the value that thread 1 wrote to memory with its own value.
One thing atomic operations do is take these operations that humans think of as being single operations, but which the computer sees as multiple operations, and makes the computer see them as single operations, too.
This is why they’re called atomic operations. It’s because they take an operation that would normally have multiple instructions—where the instructions could be paused and resumed—and it makes it so that they all happen seemingly instantaneously, as if it were one instruction. It’s like an indivisible atom.
Using atomic operations, the code for incrementing would look a little different.
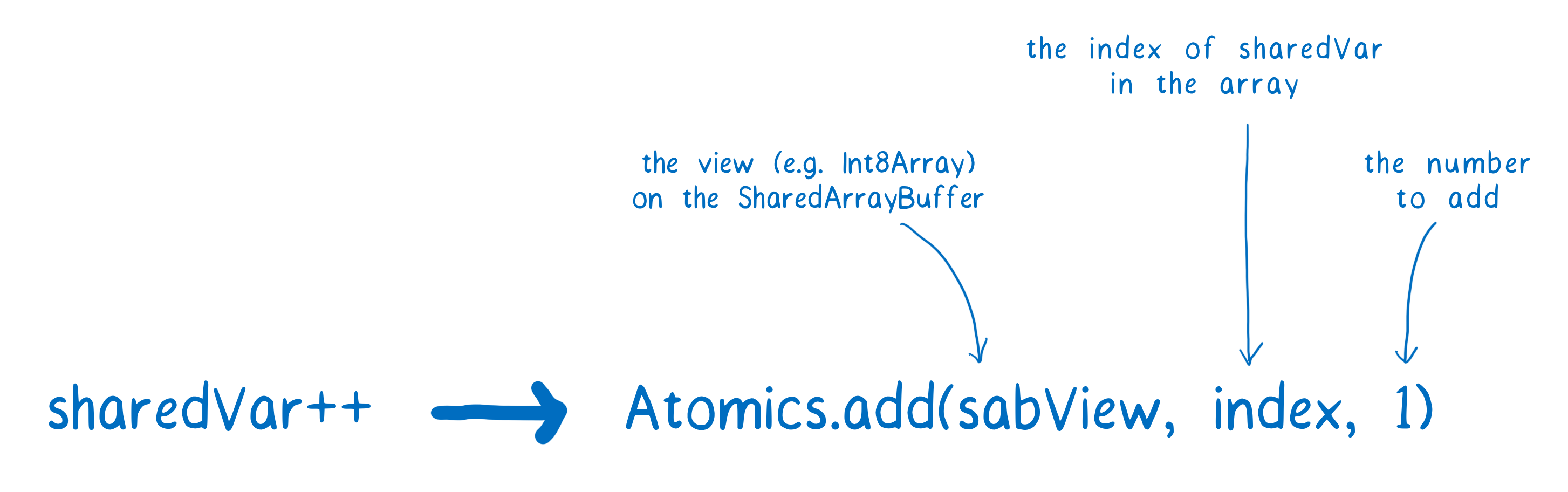
Now that we’re using Atomics.add, the different steps involved in incrementing the variable won’t be mixed up between threads. Instead, one thread will finish its atomic operation and prevent the other one from starting. Then the other will start its own atomic operation.
The Atomics methods that help avoid this kind of race are:
<a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/add">Atomics.add</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/sub">Atomics.sub</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/and">Atomics.and</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/or">Atomics.or</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/xor">Atomics.xor</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/exchange">Atomics.exchange</a>
You’ll notice that this list is fairly limited. It doesn’t even include things like division and multiplication. A library developer could create atomic-like operations for other things, though.
To do that, the developer would use <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/compareExchange">Atomics.compareExchange</a>. With this, you get a value from the SharedArrayBuffer, perform an operation on it, and only write it back to the SharedArrayBuffer if no other thread has updated it since you first checked. If another thread has updated it, then you can get that new value and try again.
Race conditions across multiple operations
So those Atomic operations help avoid race conditions during “single operations”. But sometimes you want to change multiple values on an object (using multiple operations) and make sure no one else is making changes to that object at the same time. Basically, this means that during every pass of changes to an object, that object is on lockdown and inaccessible to other threads.
The Atomics object doesn’t provide any tools to handle this directly. But it does provide tools that library authors can use to handle this. What library authors can create is a lock.

If code wants to use locked data, it has to acquire the lock for the data. Then it can use the lock to lock out the other threads. Only it will be able to access or update the data while the lock is active.
To build a lock, library authors would use <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/wait">Atomics.wait</a> and <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/wake">Atomics.wake</a>, plus other ones such as <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/compareExchange">Atomics.compareExchange</a> and <a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/store">Atomics.store</a>. If you want to see how these would work, take a look at this basic lock implementation.
In this case, thread 2 would acquire the lock for the data and set the value of locked to true. This means thread 1 can’t access the data until thread 2 unlocks.
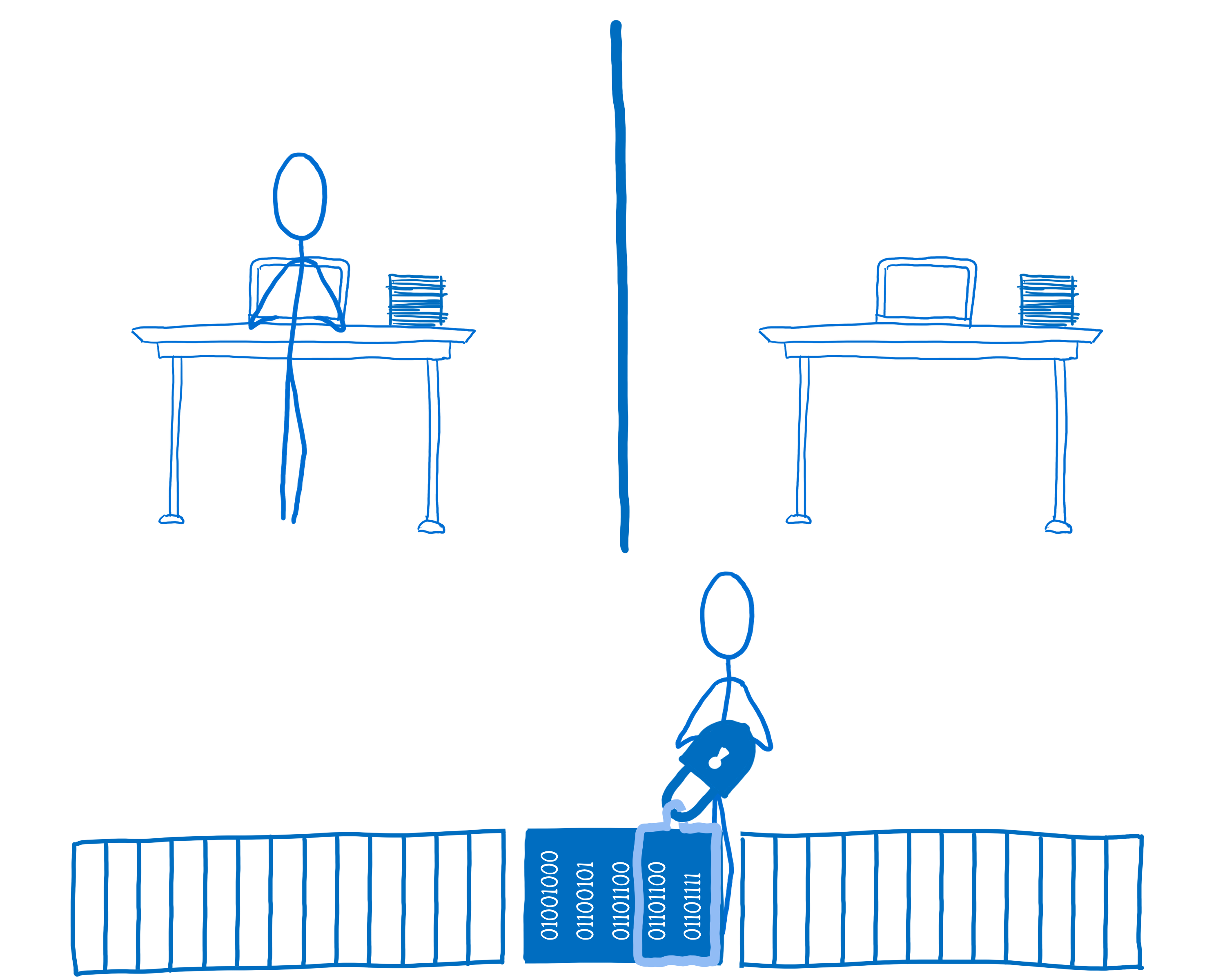
If thread 1 needs to access the data, it will try to acquire the lock. But since the lock is already in use, it can’t. The thread would then wait—so it would be blocked—until the lock is available.
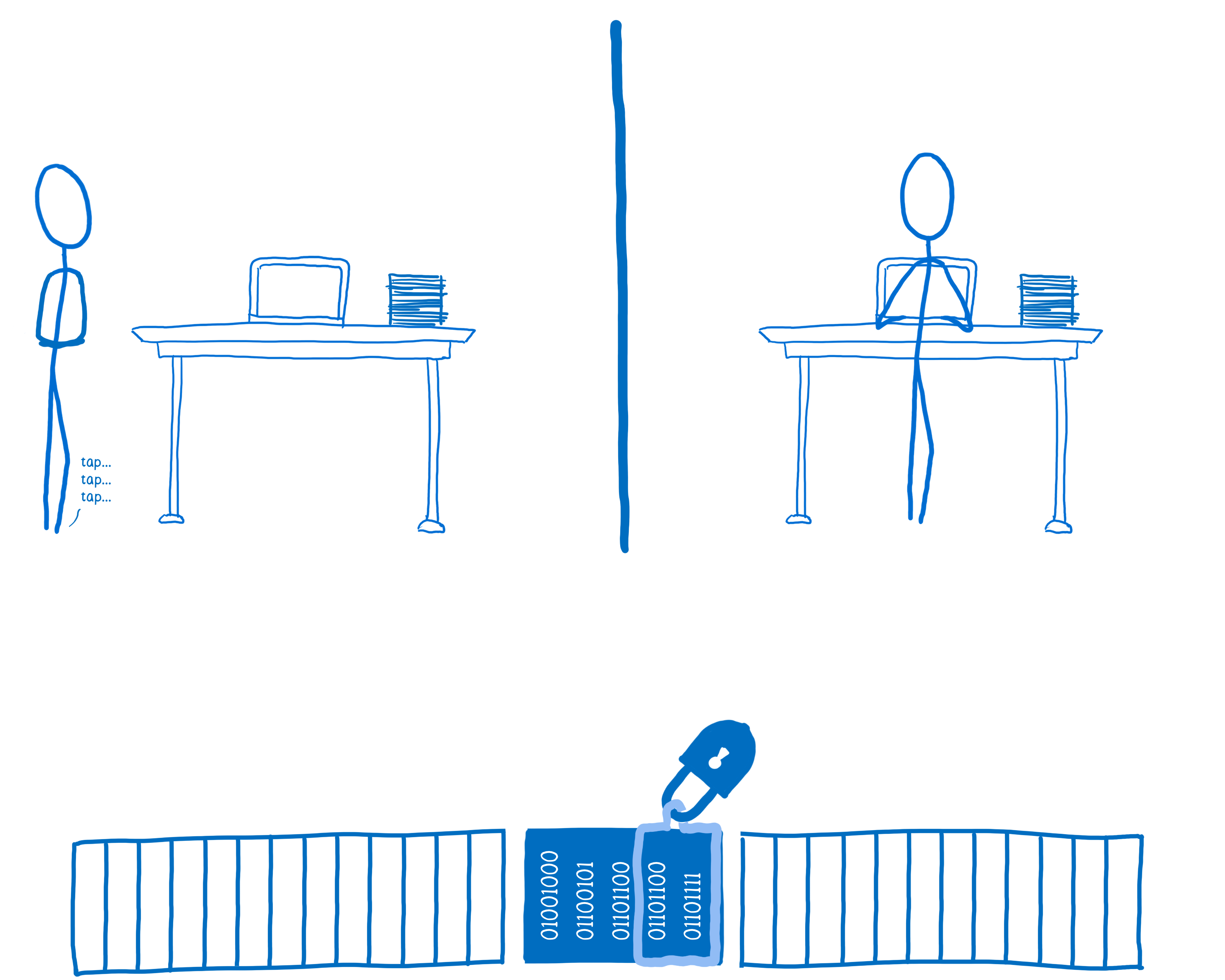
Once thread 2 is done, it would call unlock. The lock would notify one or more of the waiting threads that it’s now available.

That thread could then scoop up the lock and lock up the data for its own use.
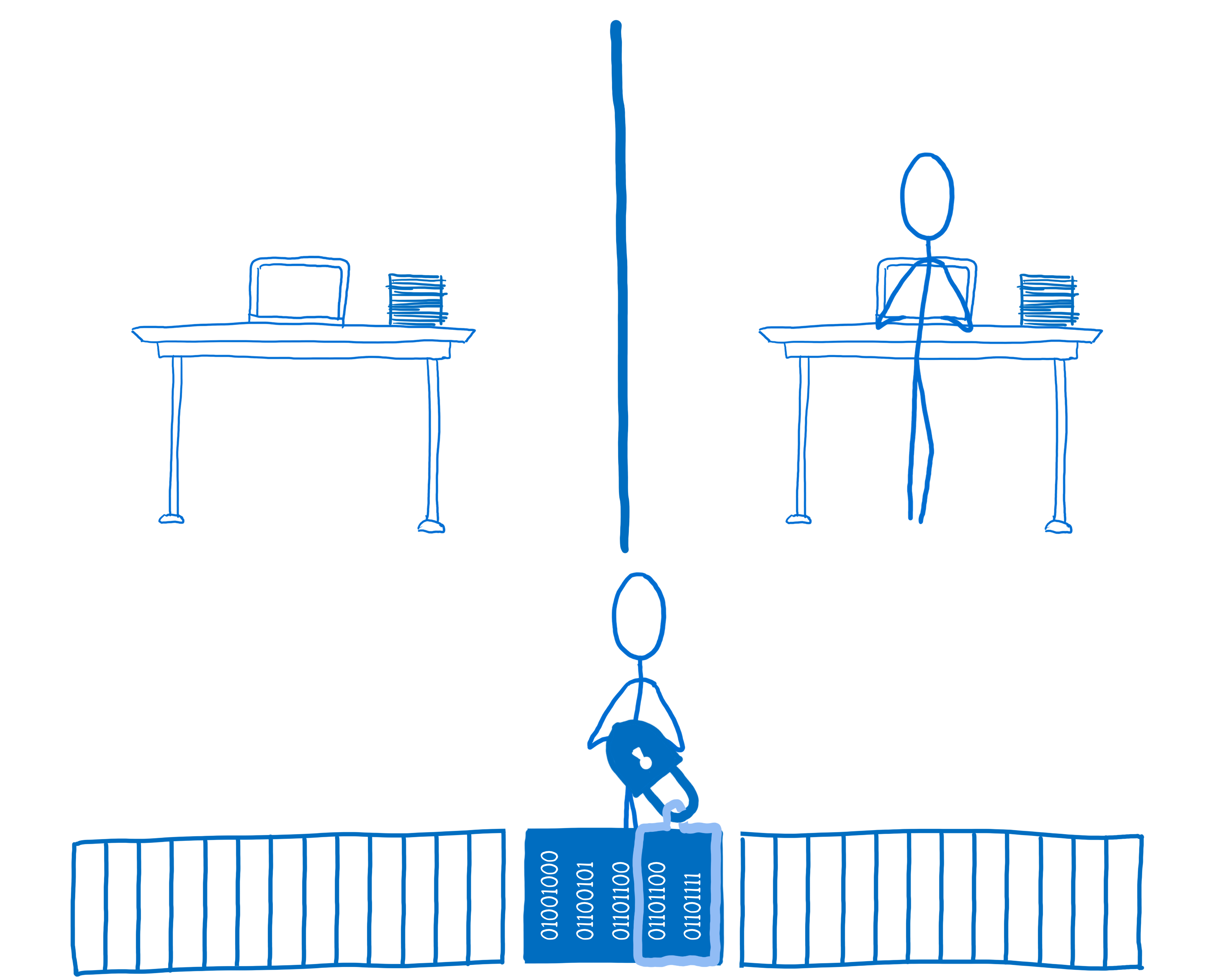
A lock library would use many of the different methods on the Atomics object, but the methods that are most important for this use case are:
<a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/wait">Atomics.wait</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/wake">Atomics.wake</a>
Race conditions caused by instruction reordering
There’s a third synchronization problem that Atomics take care of. This one can be surprising.
You probably don’t realize it, but there’s a very good chance that the code you’re writing isn’t running in the order you expect it to. Both compilers and CPUs reorder code to make it run faster.
For example, let’s say you’ve written some code to calculate a total. You want to set a flag when the calculation is finished.
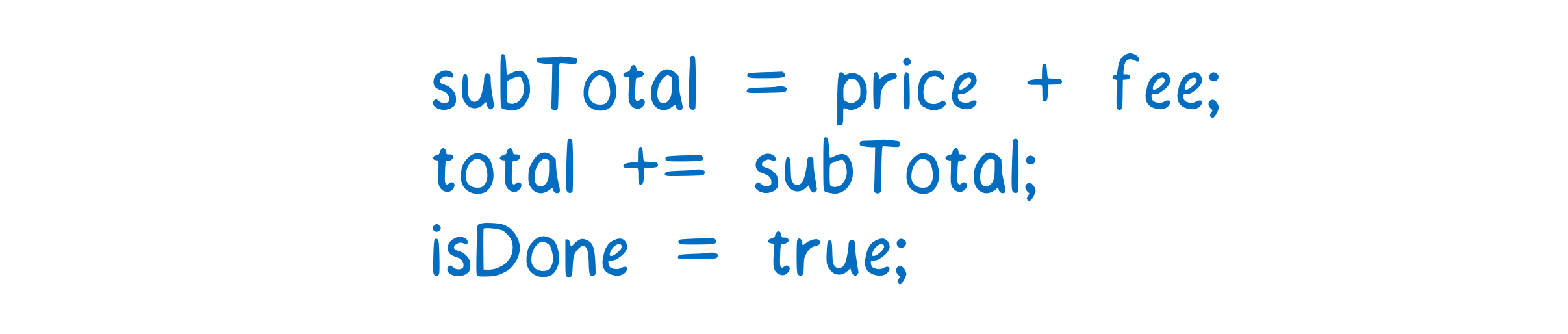
To compile this, we need to decide which register to use for each variable. Then we can translate the source code into instructions for the machine.

So far, everything is as expected.
What’s not obvious if you don’t understand how computers work at the chip level (and how the pipelines that they use for executing code work) is that line 2 in our code needs to wait a little bit before it can execute.
Most computers break down the process of running an instruction into multiple steps. This makes sure all of the different parts of the CPU are busy at all times, so it makes the best use of the CPU.
Here’s one example of the steps an instruction goes through:
- Fetch the next instruction from memory
- Figure out what the instruction is telling us to do (aka decode the instruction), and get the values from the registers
- Execute the instruction
- Write the result back to the register
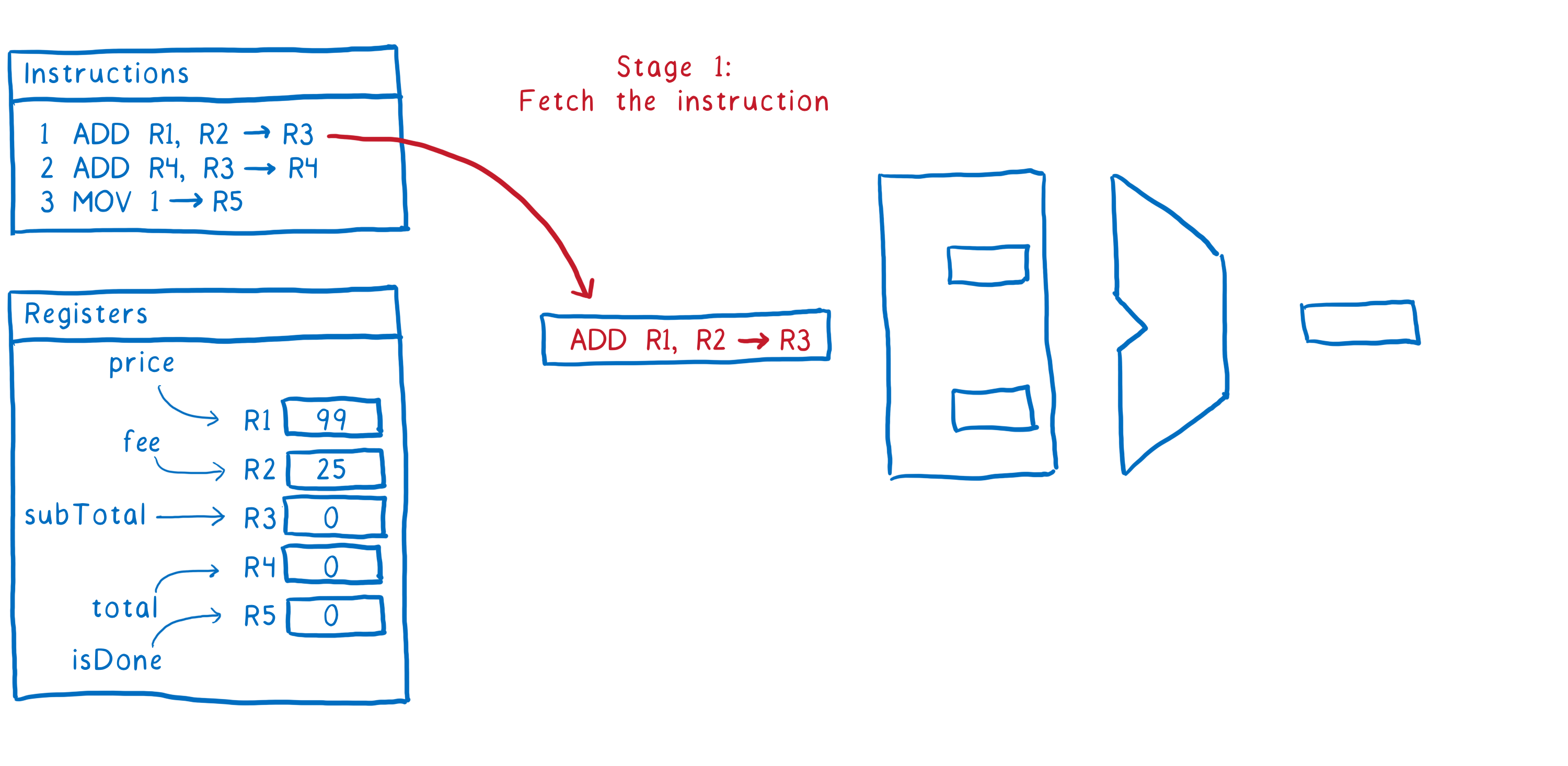

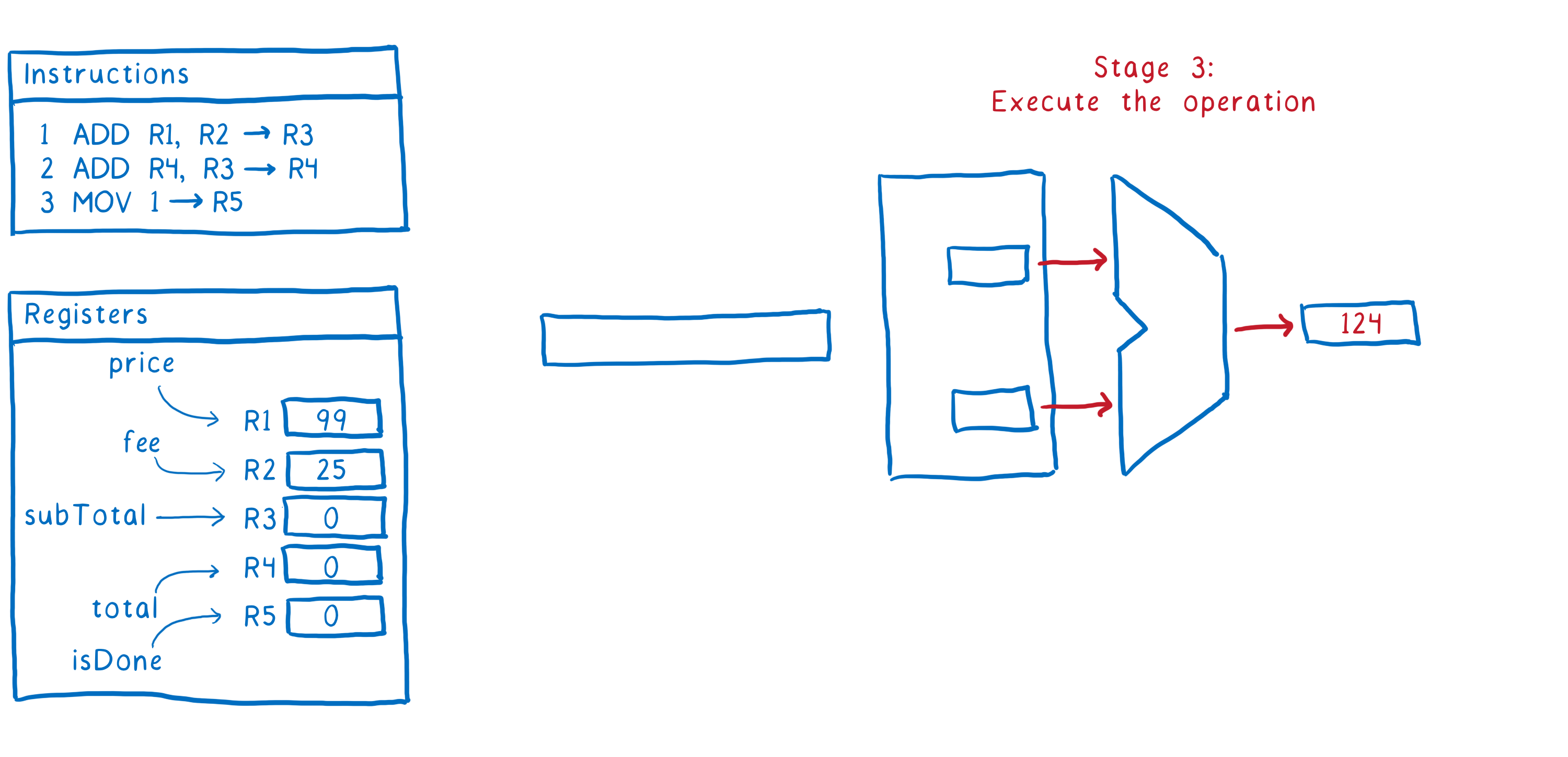
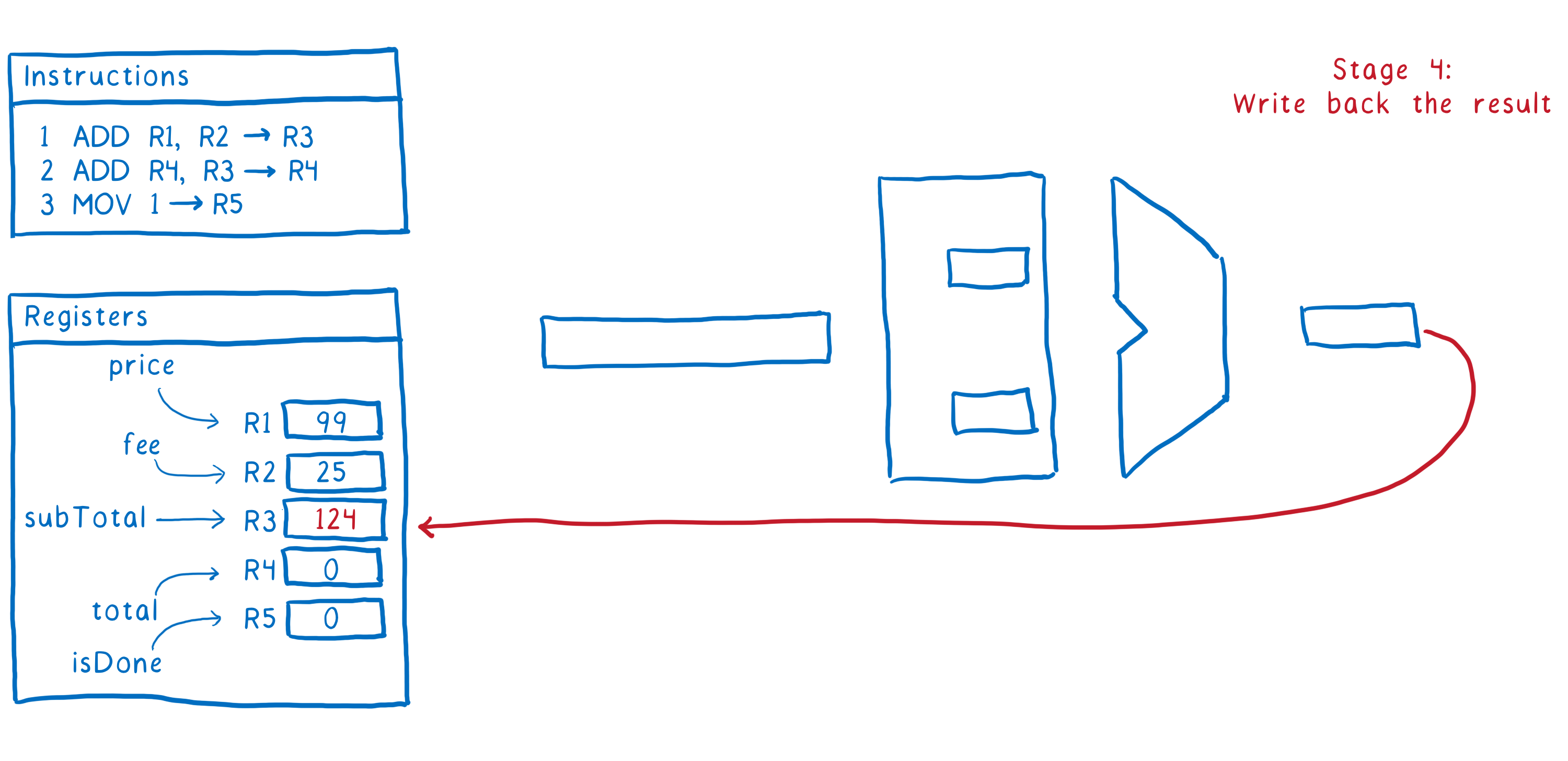
So that’s how one instruction goes through the pipeline. Ideally, we want to have the second instruction following directly after it. As soon as it has moved into stage 2, we want to fetch the next instruction.
The problem is that there is a dependency between instruction #1 and instruction #2.

We could just pause the CPU until instruction #1 has updated subTotal in the register. But that would slow things down.
To make things more efficient, what a lot of compilers and CPUs will do is reorder the code. They will look for other instructions which don’t use subTotal or total and move those in between those two lines.

This keeps a steady stream of instructions moving through the pipe.
Because line 3 didn’t depend on any values in line 1 or 2, the compiler or CPU figures it’s safe to reorder like this. When you’re running in a single thread, no other code will even see these values until the whole function is done, anyway.
But when you have another thread running at the same time on another processor, that’s not the case. The other thread doesn’t have to wait until the function is done to see these changes. It can see them almost as soon as they are written back to memory. So it can tell that isDone was set before total.
If you were using isDone as a flag that the total had been calculated and was ready to use in the other thread, then this kind of reordering would create race conditions.
Atomics attempt to solve some of these bugs. When you use an Atomic write, it’s like putting a fence between two parts of your code.
Atomic operations aren’t reordered relative to each other, and other operations aren’t moved around them. In particular, two operations that are often used to enforce ordering are:
<a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/load">Atomics.load</a><a href="https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Atomics/store">Atomics.store</a>
All variable updates above Atomics.store in the function’s source code are guaranteed to be done before Atomics.store is done writing its value back to memory. Even if the non-Atomic instructions are reordered relative to each other, none of them will be moved below a call to Atomics.store which comes below in the source code.
And all variable loads after Atomics.load in a function are guaranteed to be done after Atomics.load fetches its value. Again, even if the non-atomic instructions are reordered, none of them will be moved above an Atomics.load that comes above them in the source code.
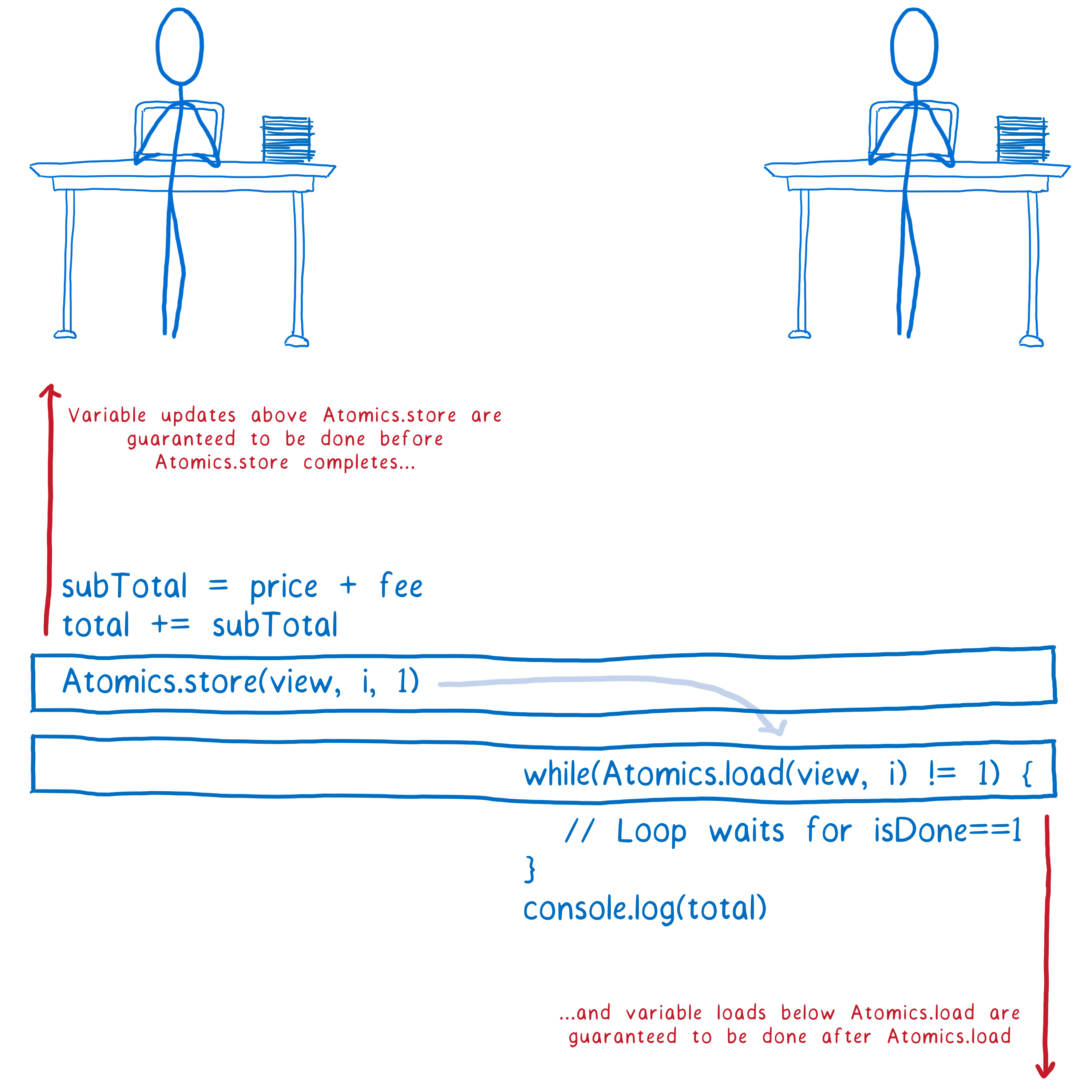
Note: The while loop I show here is called a spinlock and it’s very inefficient. And if it’s on the main thread, it can bring your application to a halt. You almost certainly don’t want to use that in real code.
Once again, these methods aren’t really meant for direct use in application code. Instead, libraries would use them to create locks.
Conclusion
Programming multiple threads that share memory is hard. There are many different kinds of race conditions just waiting to trip you up.

This is why you don’t want to use SharedArrayBuffers and Atomics in your application code directly. Instead, you should depend on proven libraries by developers who are experienced with multithreading, and who have spent time studying the memory model.
It is still early days for SharedArrayBuffer and Atomics. Those libraries haven’t been created yet. But these new APIs provide the basic foundation to build on top of.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
5 comments