
This is the third part in a series on WebAssembly and what makes it fast. If you haven’t read the others, we recommend starting from the beginning.
To understand how WebAssembly works, it helps to understand what assembly is and how compilers produce it.
In the article on the JIT, I talked about how communicating with the machine is like communicating with an alien.

I want to take a look now at how that alien brain works—how the machine’s brain parses and understands the communication coming in to it.
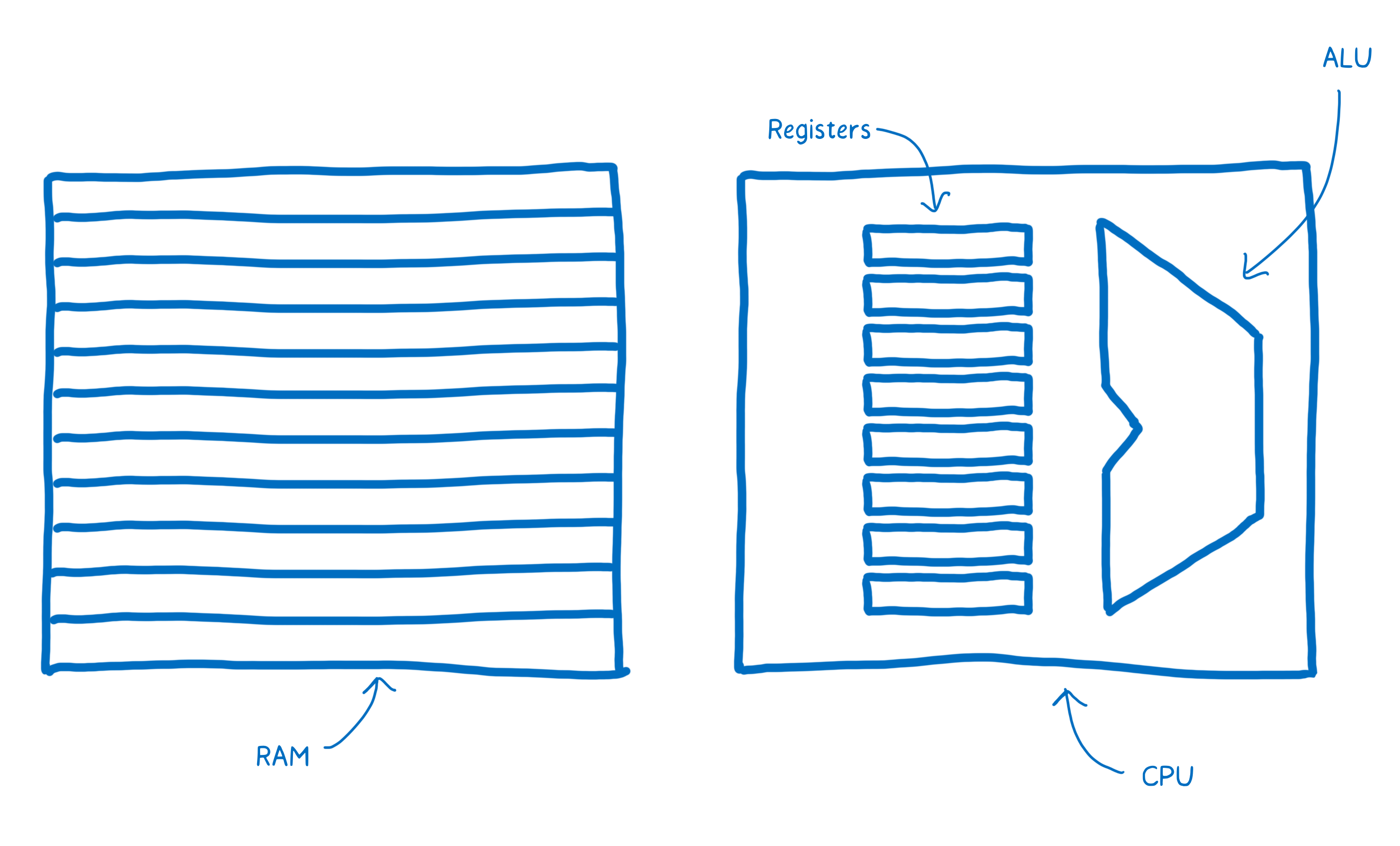
There’s a part of this brain that’s dedicated to the thinking—things like adding and subtracting, or logical operations. There’s also a part of the brain near that which provides short-term memory, and another part that provides longer-term memory.
These different parts have names.
- The part that does the thinking is the Arithmetic-logic Unit (ALU).
- The short term memory is provided by registers.
- The longer term memory is the Random Access Memory (or RAM).
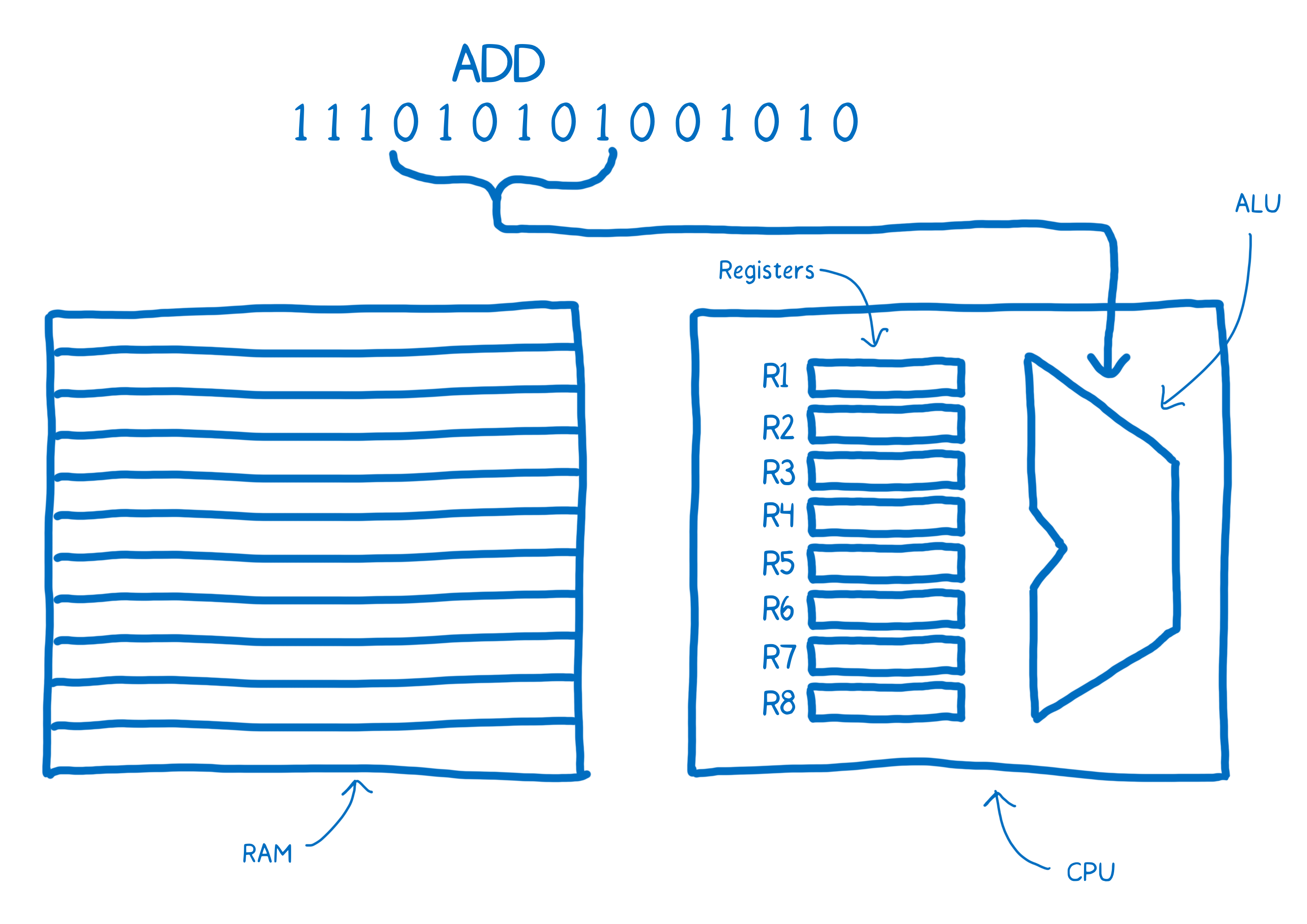
The sentences in machine code are called instructions.
What happens when one of these instructions comes into the brain? It gets split up into different parts that mean different things.
The way that this instruction is split up is specific to the wiring of this brain.
For example, a brain that is wired like this might always take the first six bits and pipe that in to the ALU. The ALU will figure out, based on the location of ones and zeros, that it needs to add two things together.
This chunk is called the “opcode”, or operation code, because it tells the ALU what operation to perform.
Then this brain would take the next two chunks of three bits each to determine which two numbers it should add. These would be addresses of the registers.
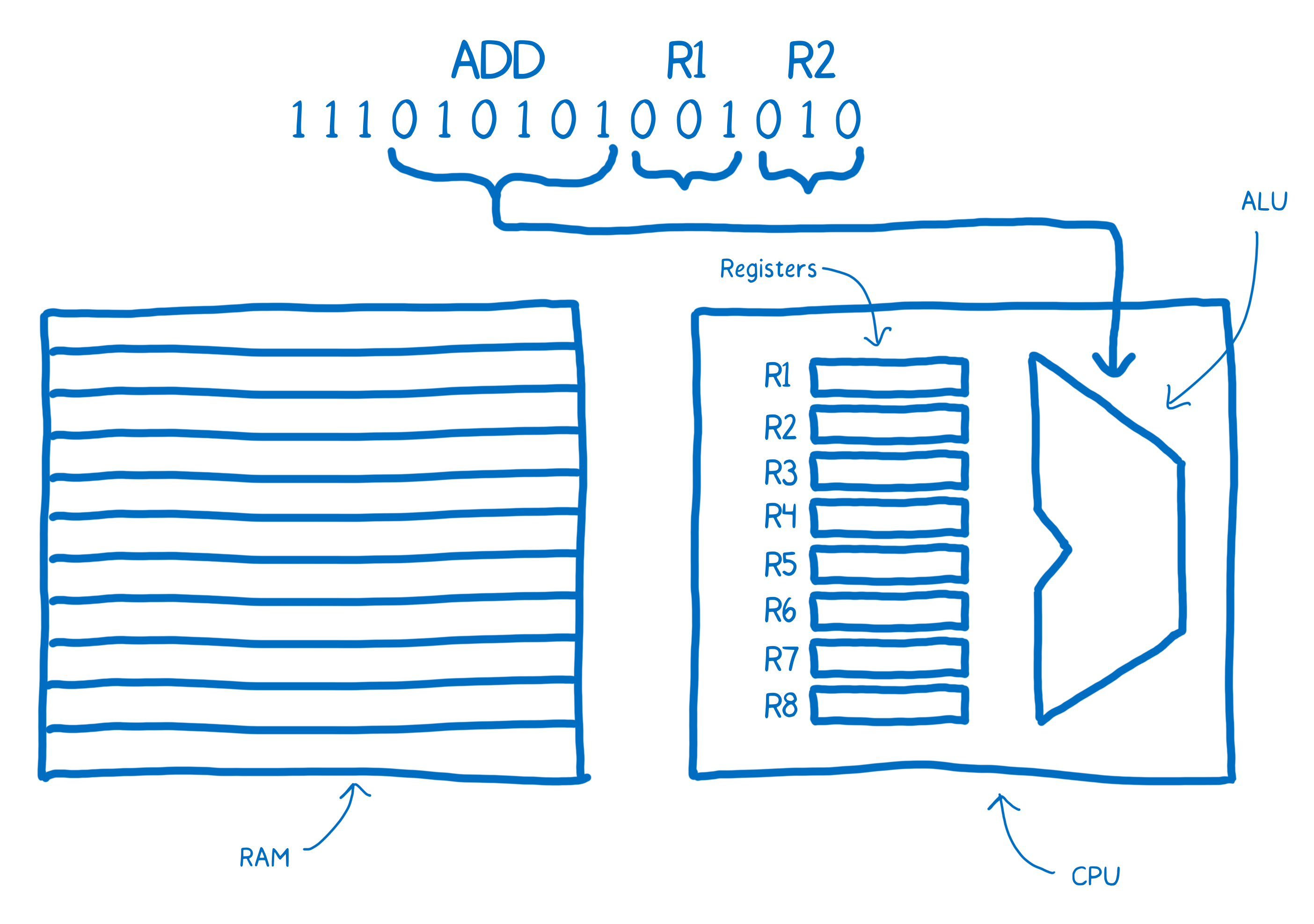
Note the annotations above the machine code here, which make it easier for us humans to understand what’s going on. This is what assembly is. It’s called symbolic machine code. It’s a way for humans to make sense of the machine code.
You can see here there is a pretty direct relationship between the assembly and the machine code for this machine. Because of this, there are different kinds of assembly for the different kinds of machine architectures that you can have. When you have a different architecture inside of a machine, it is likely to require its own dialect of assembly.
So we don’t just have one target for our translation. It’s not just one language called machine code. It’s many different kinds of machine code. Just as we speak different languages as people, machines speak different languages.
With human to alien translation, you may be going from English, or Russian, or Mandarin to Alien Language A or Alien language B. In programming terms, this is like going from C, or C++, or Rust to x86 or to ARM.
You want to be able to translate any one of these high-level programming languages down to any one of these assembly languages (which corresponds to the different architectures). One way to do this would be to create a whole bunch of different translators that can go from each language to each assembly.
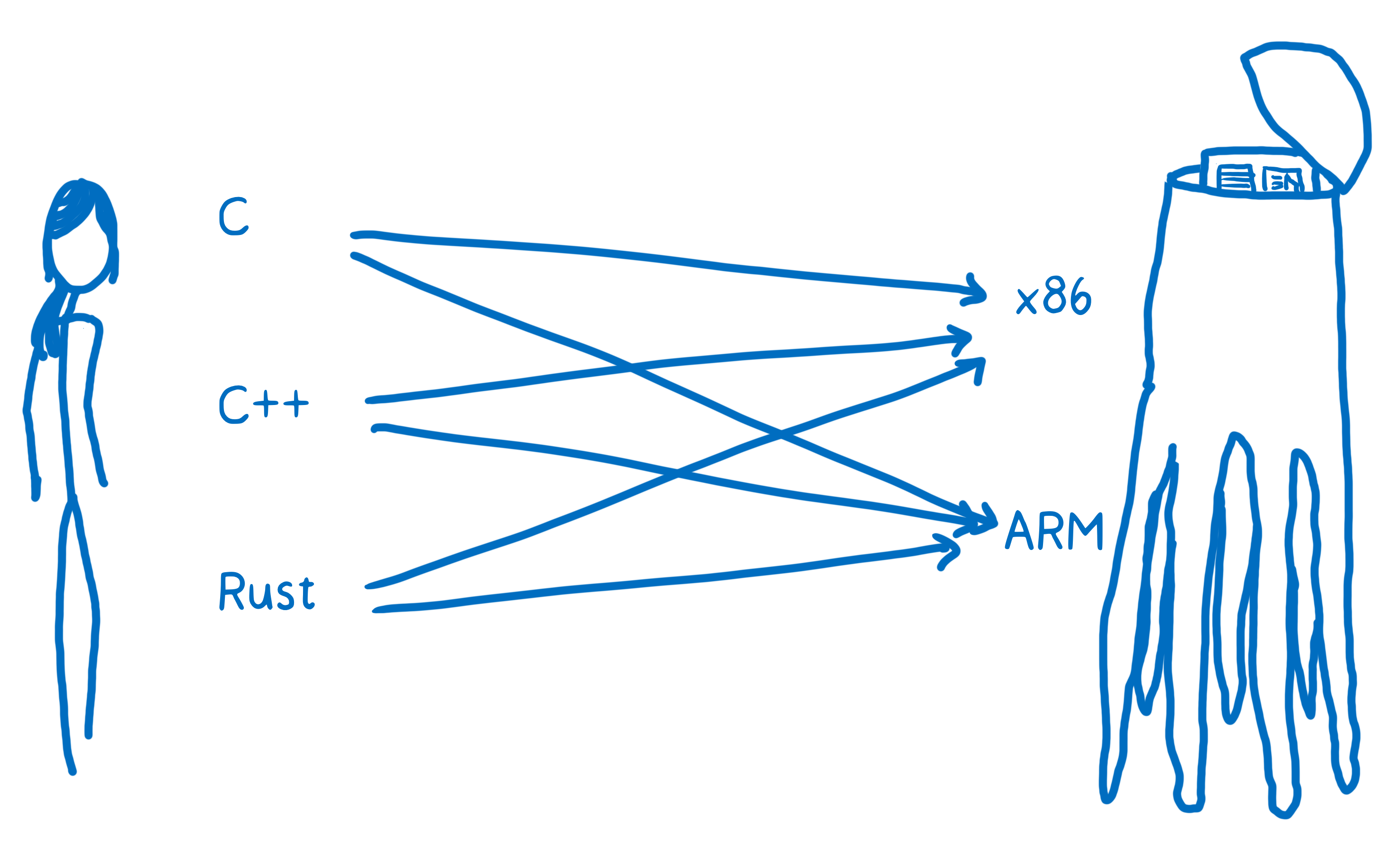
That’s going to be pretty inefficient. To solve this, most compilers put at least one layer in between. The compiler will take this high-level programming language and translate it into something that’s not quite as high level, but also isn’t working at the level of machine code. And that’s called an intermediate representation (IR).
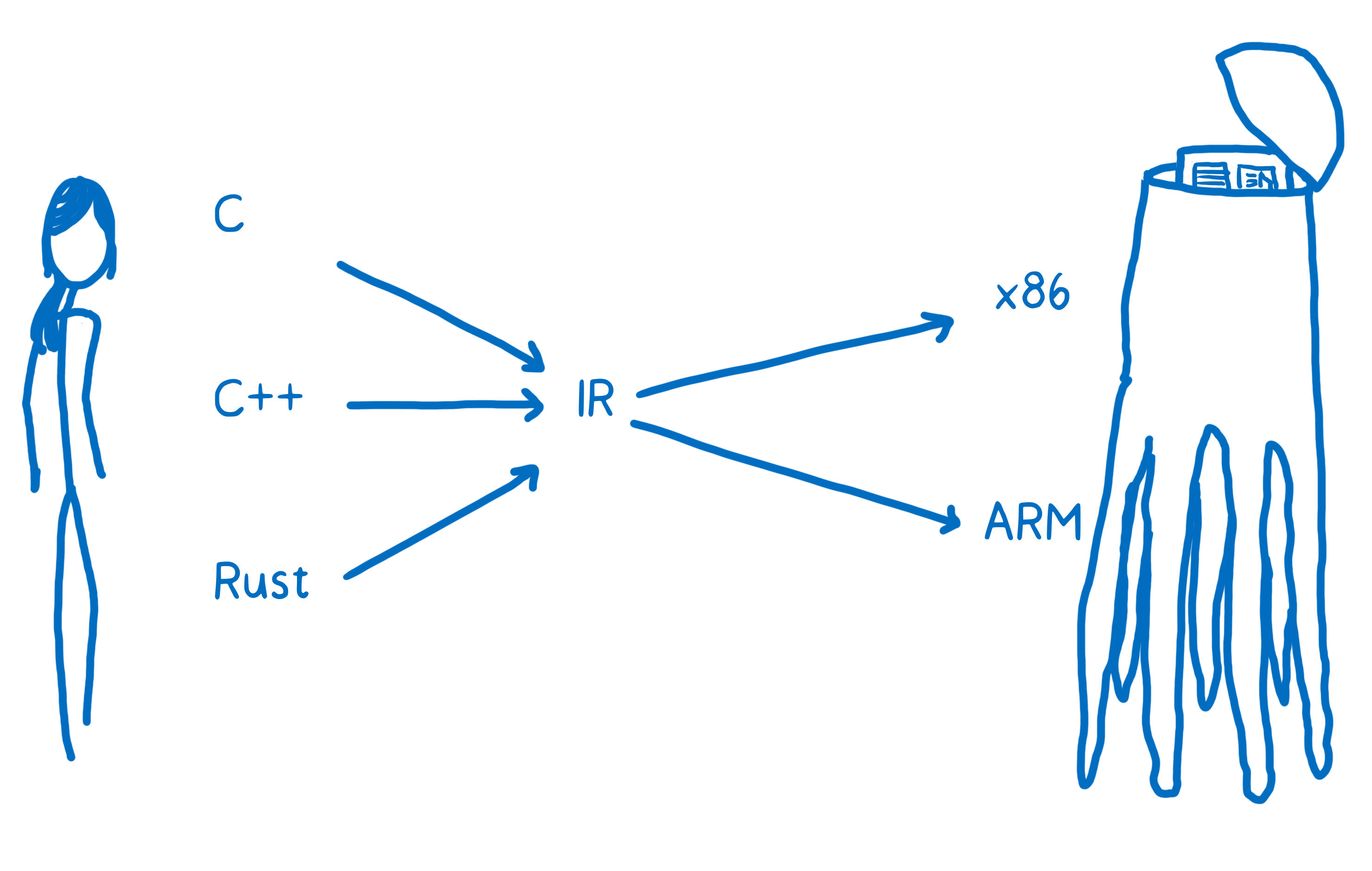
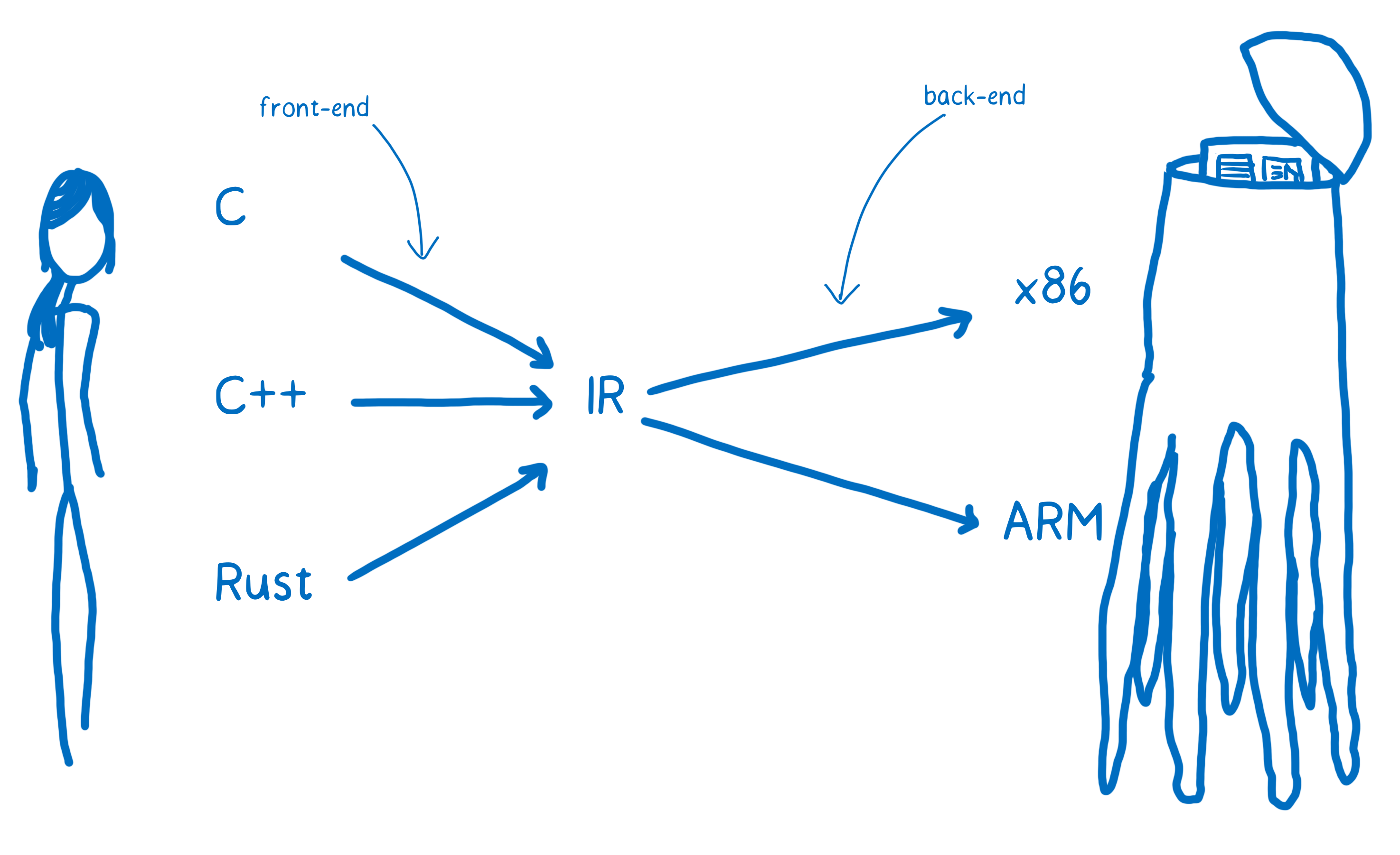
This means the compiler can take any one of these higher-level languages and translate it to the one IR language. From there, another part of the compiler can take that IR and compile it down to something specific to the target architecture.
The compiler’s front-end translates the higher-level programming language to the IR. The compiler’s backend goes from IR to the target architecture’s assembly code.
Conclusion
That’s what assembly is and how compilers translate higher-level programming languages to assembly. In the next article, we’ll see how WebAssembly fits in to this.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
6 comments