
This is the 1st article in a 3-part series:
- A crash course in memory management
- A cartoon intro to ArrayBuffers and SharedArrayBuffers
- Avoiding race conditions in SharedArrayBuffers with Atomics
To understand why ArrayBuffer and SharedArrayBuffer were added to JavaScript, you need to understand a bit about memory management.
You can think of memory in a machine as a bunch of boxes. I think of these like the mailboxes that you have in offices, or the cubbies that pre-schoolers have to store their things.
If you need to leave something for one of the other kids, you can put it inside a box.

Next to each one of these boxes, you have a number, which is the memory address. That’s how you tell someone where to find the thing you’ve left for them.
Each one of these boxes is the same size and can hold a certain amount of info. The size of the box is specific to the machine. That size is called word size. It’s usually something like 32-bits or 64-bits. But to make it easier to show, I’m going to use a word size of 8 bits.
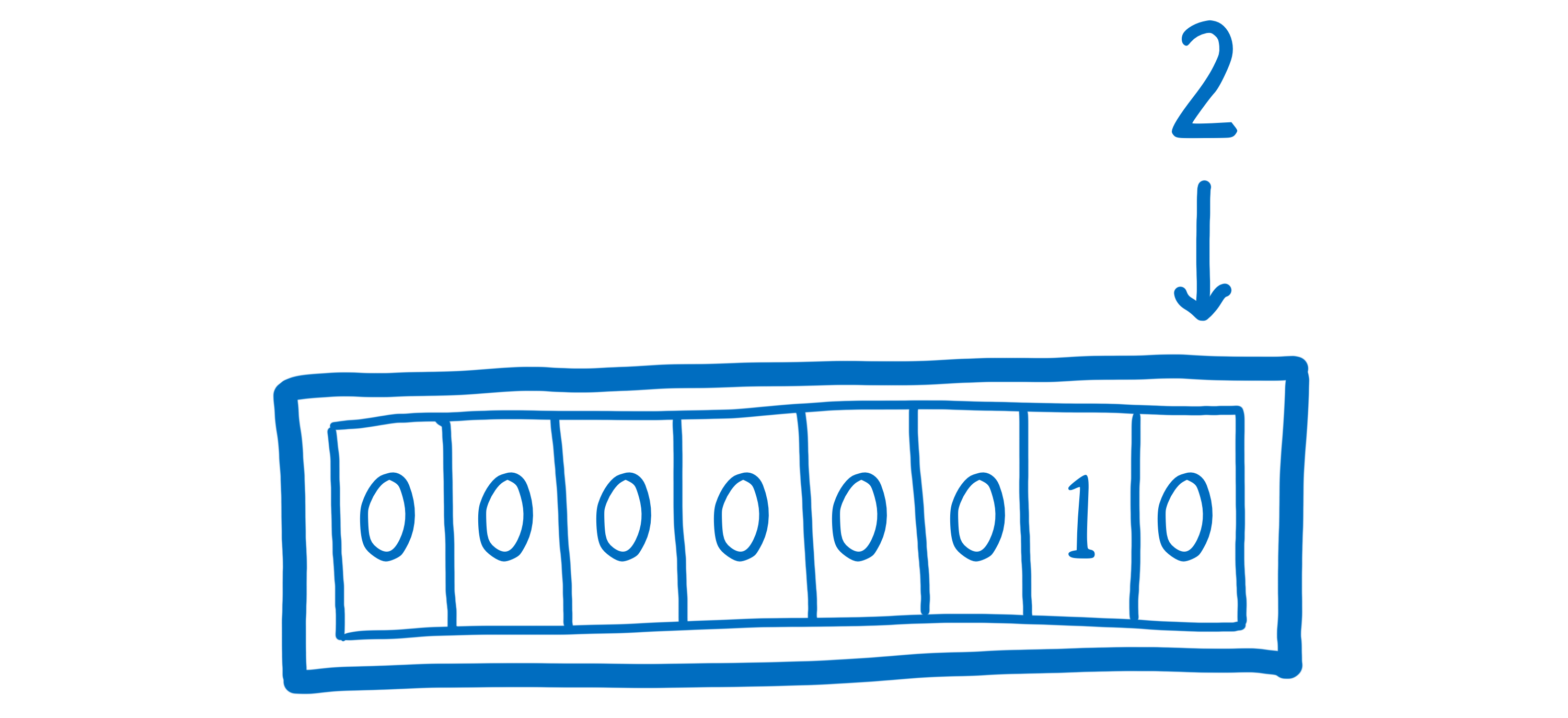
If we wanted to put the number 2 in one of these boxes, we could do it easily. Numbers are easy to represent in binary.
What if we want something that’s not a number though? Like the letter H?
We’d need to have a way to represent it as a number. To do that, we need an encoding, something like UTF-8. And we’d need something to turn it into that number… like an encoder ring. And then we can store it.
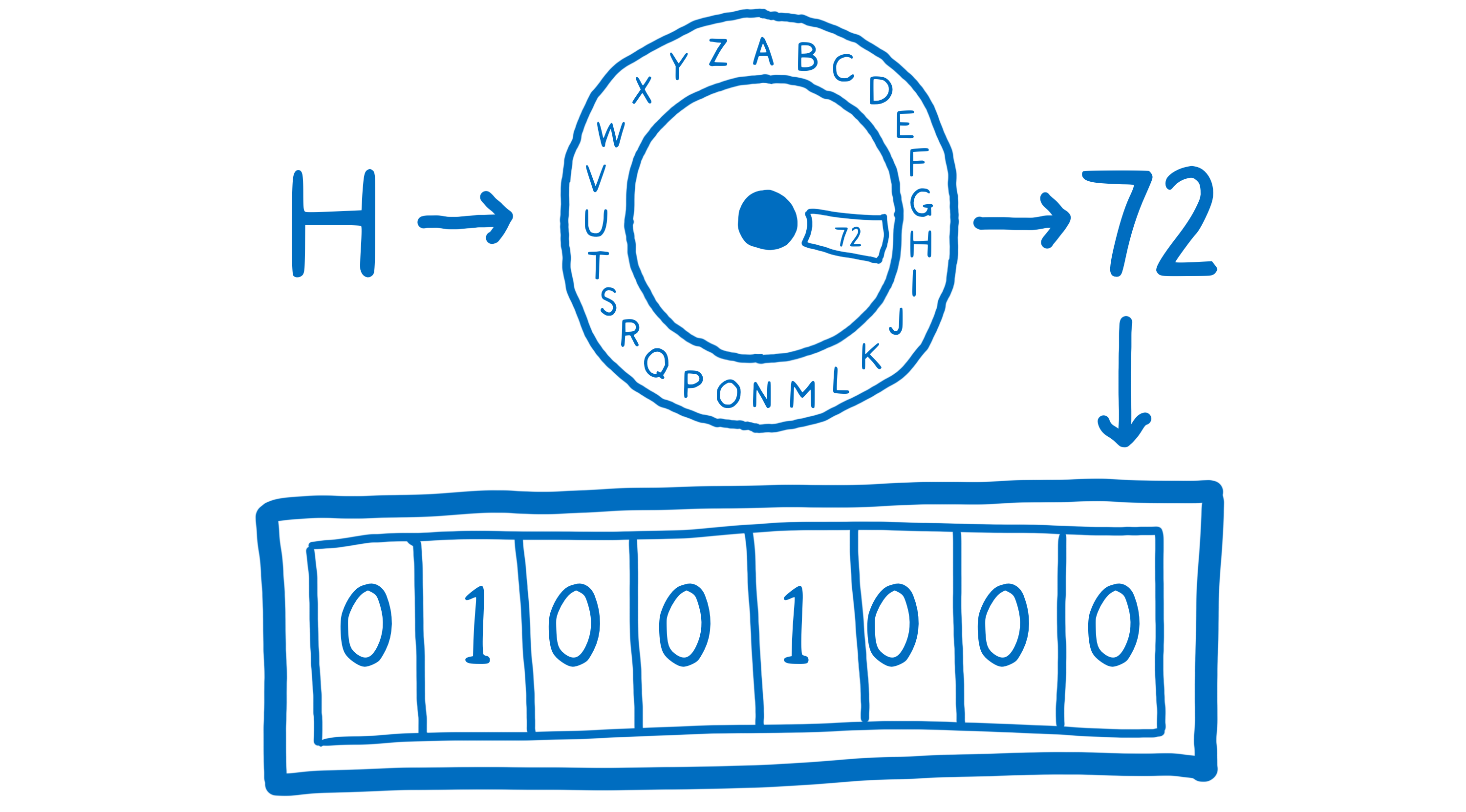
When we want to get it back out of the box, we’d have to put it through a decoder to translate it back to H.
Automatic memory management
When you’re working in JavaScript you don’t actually need to think about this memory. It’s abstracted away from you. This means you don’t touch the memory directly.
Instead, the JS engine acts as an intermediary. It manages the memory for you.
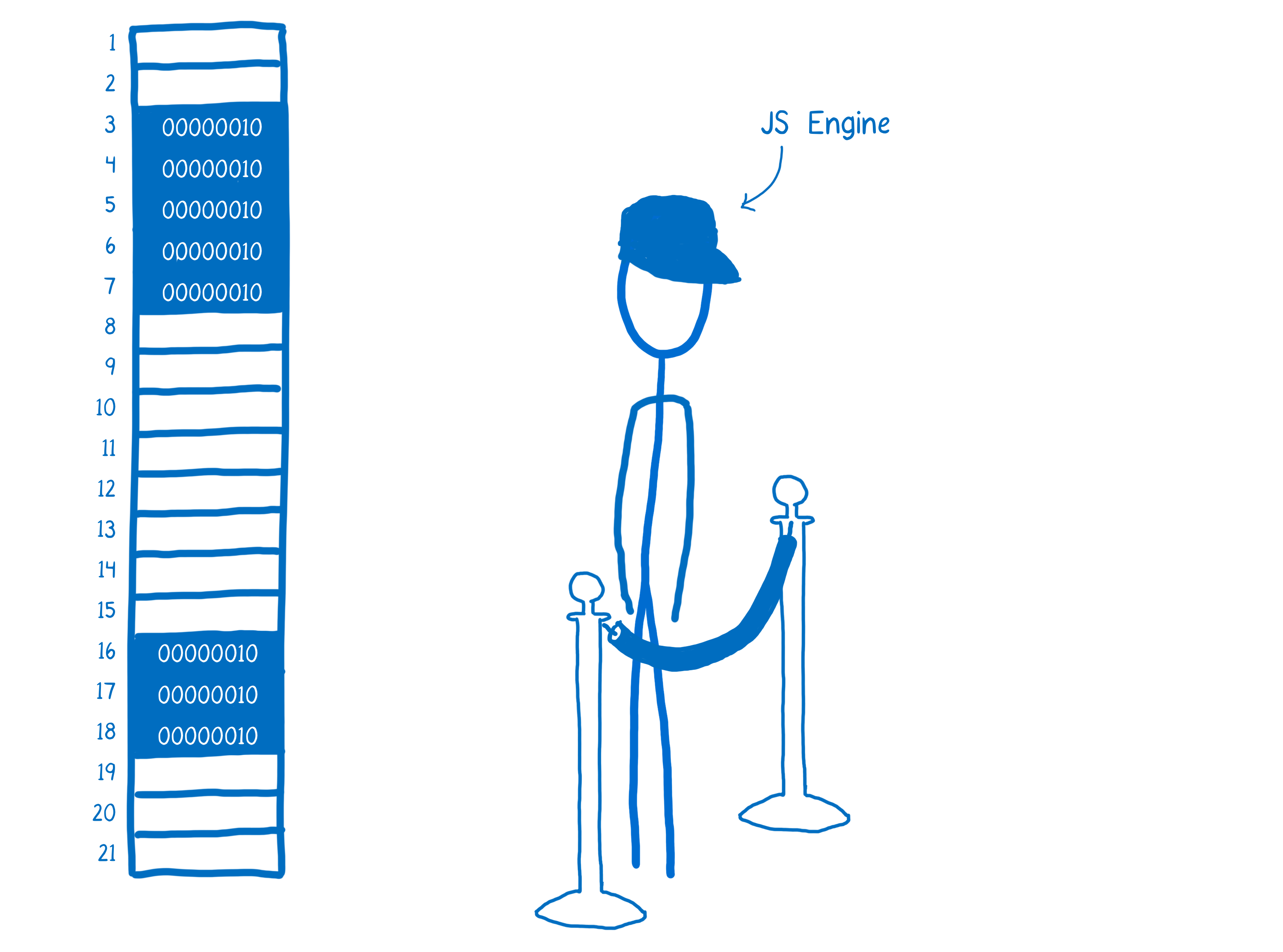
So let’s say some JS code, like React, wants to create a variable.

What the JS engine does is run that value through an encoder to get the binary representation of the value.
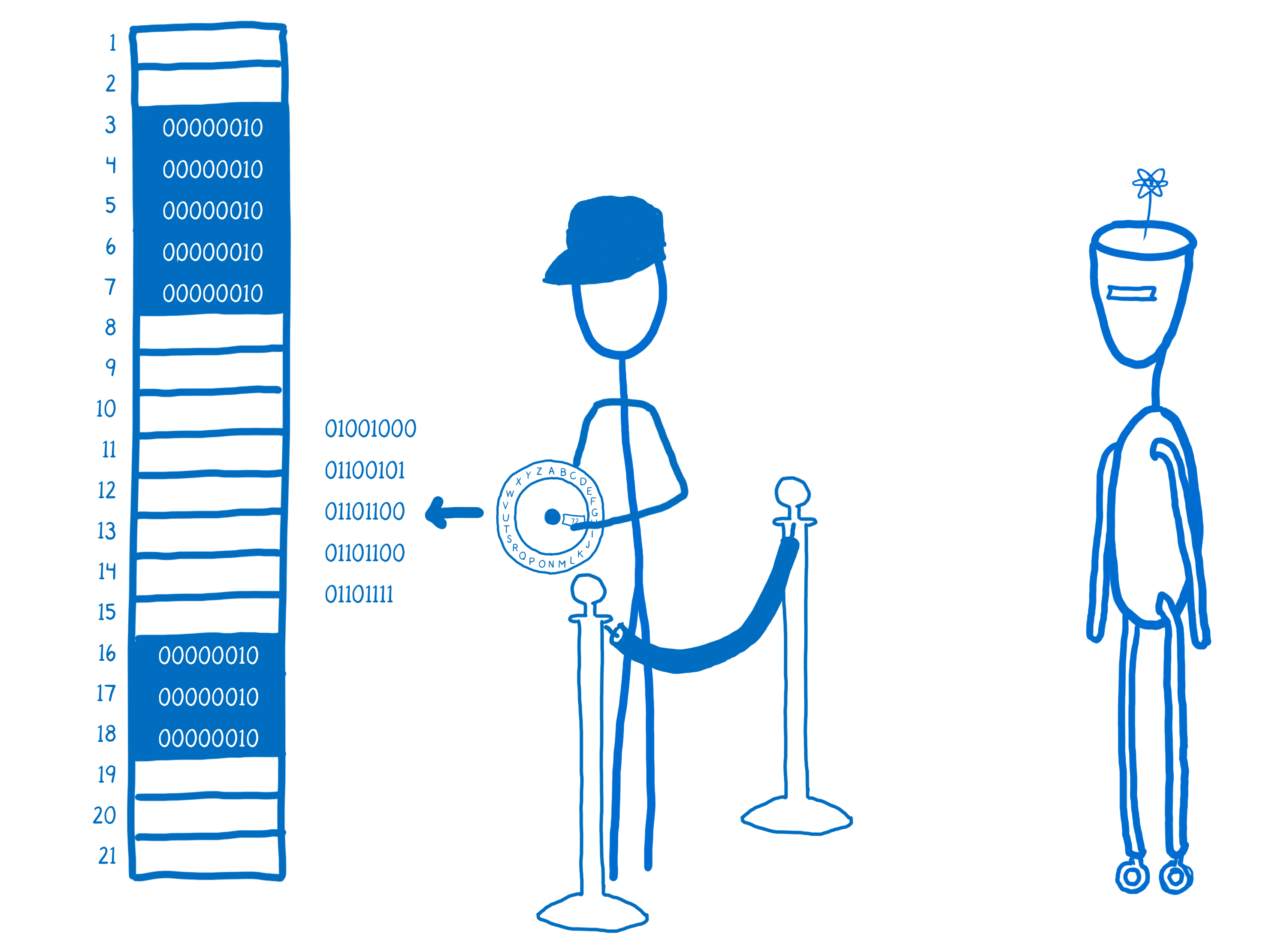
And it will find space in the memory that it can put that binary representation into. This process is called allocating memory.
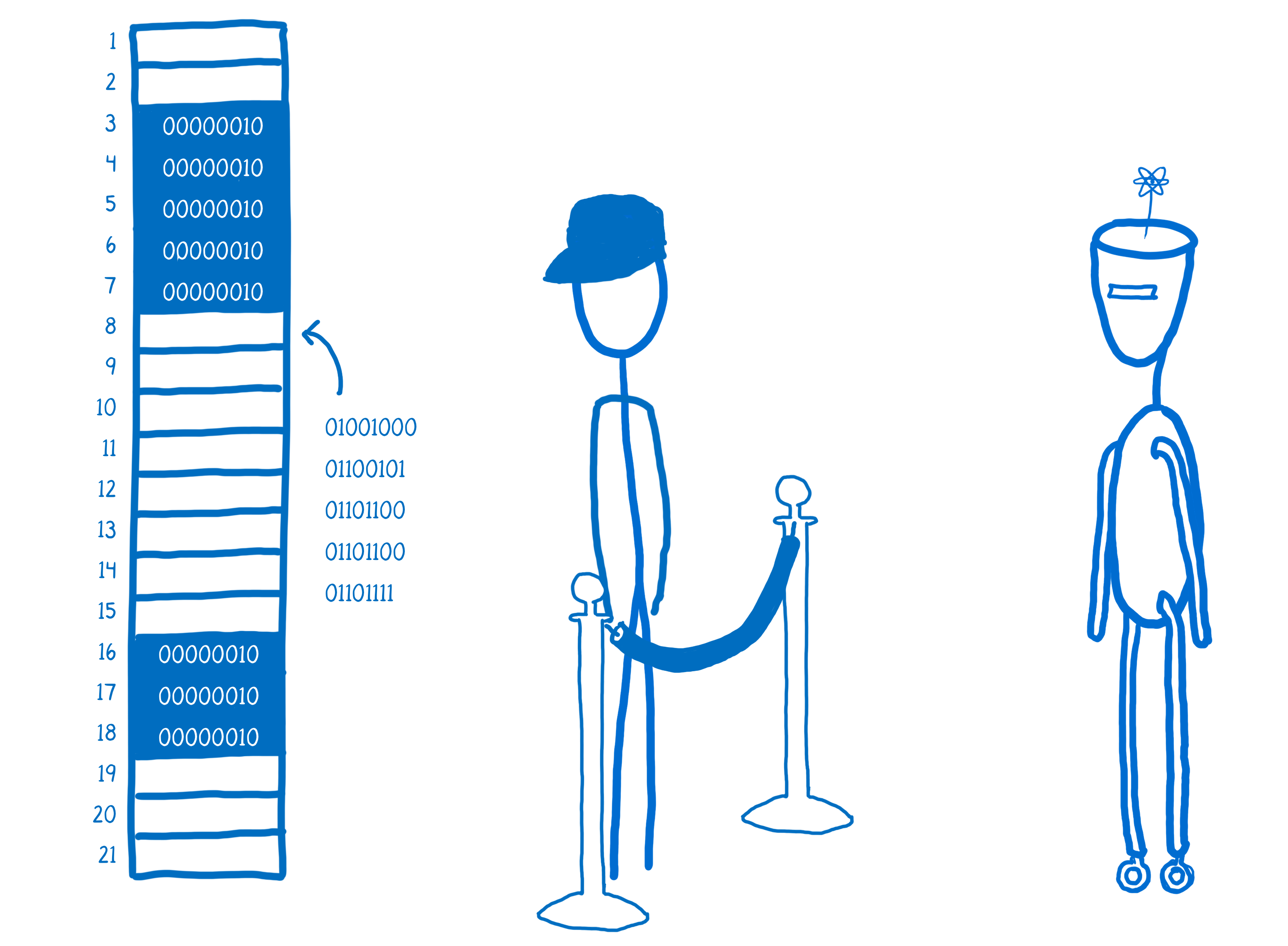
Then, the engine will keep track of whether or not this variable is still accessible from anywhere in the program. If the variable can no longer be reached, the memory is going to be reclaimed so that the JS engine can put new values there.

This process of watching the variables—strings, objects, and other kinds of values that go in memory—and clearing them out when they can’t be reached anymore is called garbage collection.
Languages like JavaScript, where the code doesn’t deal with memory directly, are called memory-managed languages.
This automatic memory management can make things easier for developers. But it also adds some overhead. And that overhead can sometimes make performance unpredictable.
Manual memory management
Languages with manually managed memory are different. For example, let’s look at how React would work with memory if it were written in C (which would be possible now with WebAssembly).
C doesn’t have that layer of abstraction that JavaScript does on the memory. Instead, you’re operating directly on memory. You can load things from memory, and you can store things to memory.
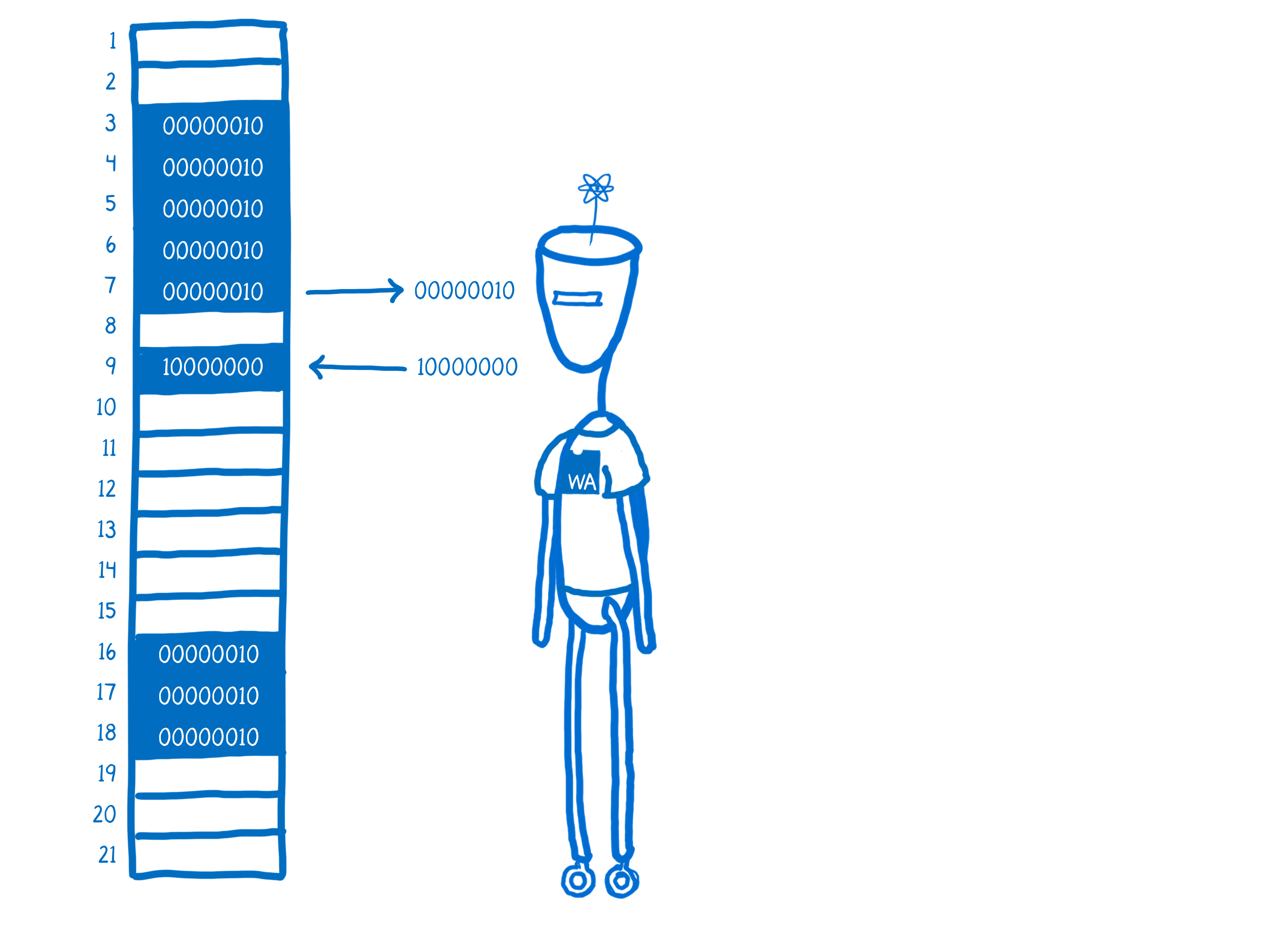
When you’re compiling C or other languages down to WebAssembly, the tool that you use will add in some helper code to your WebAssembly. For example, it would add code that does the encoding and decoding bytes. This code is called a runtime environment. The runtime environment will help handle some of the stuff that the JS engine does for JS.

But for a manually managed language, that runtime won’t include garbage collection.
This doesn’t mean that you’re totally on your own. Even in languages with manual memory management, you’ll usually get some help from the language runtime. For example, in C, the runtime will keep track of which memory addresses are open in something called a free list.

You can use the function malloc (short for memory allocate) to ask the runtime to find some memory addresses that can fit your data. This will take those addresses off of the free list. When you’re done with that data, you have to call free to deallocate the memory. Then those addresses will be added back to the free list.
You have to figure out when to call those functions. That’s why it’s called manual memory management—you manage the memory yourself.
As a developer, figuring out when to clear out different parts of memory can be hard. If you do it at the wrong time, it can cause bugs and even lead to security holes. If you don’t do it, you run out of memory.
This is why many modern languages use automatic memory management—to avoid human error. But that comes at the cost of performance. I’ll explain more about this in the next article.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
19 comments