
Last month, Gregor Weber and I added an autocomplete search to MDN Web Docs, that allows you to quickly jump straight to the document you’re looking for by typing parts of the document title. This is the story about how that’s implemented. If you stick around to the end, I’ll share an “easter egg” feature that, once you’ve learned it, will make you look really cool at dinner parties. Or, perhaps you just want to navigate MDN faster than mere mortals.
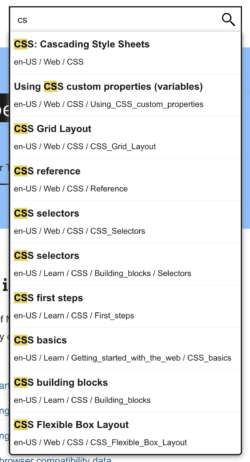
In its simplest form, the input field has an onkeypress event listener that filters through a complete list of every single document title (per locale). At the time of writing, there are 11,690 different document titles (and their URLs) for English US. You can see a preview by opening https://developer.mozilla.org/en-US/search-index.json. Yes, it’s huge, but it’s not too huge to load all into memory. After all, together with the code that does the searching, it’s only loaded when the user has indicated intent to type something. And speaking of size, because the file is compressed with Brotli, the file is only 144KB over the network.
Implementation details
By default, the only JavaScript code that’s loaded is a small shim that watches for onmouseover and onfocus for the search <input> field. There’s also an event listener on the whole document that looks for a certain keystroke. Pressing / at any point, acts the same as if you had used your mouse cursor to put focus into the <input> field. As soon as focus is triggered, the first thing it does is download two JavaScript bundles which turns the <input> field into something much more advanced. In its simplest (pseudo) form, here’s how it works:
<input
type="search"
name="q"
onfocus="startAutocomplete()"
onmouseover="startAutocomplete()"
placeholder="Site search..."
value="q">let started = false;
function startAutocomplete() {
if (started) {
return false;
}
const script = document.createElement("script");
script.src = "/static/js/autocomplete.js";
document.head.appendChild(script);
}Then it loads /static/js/autocomplete.js which is where the real magic happens. Let’s dig deeper with the pseudo code:
(async function() {
const response = await fetch('/en-US/search-index.json');
const documents = await response.json();
const inputValue = document.querySelector(
'input[type="search"]'
).value;
const flex = FlexSearch.create();
documents.forEach(({ title }, i) => {
flex.add(i, title);
});
const indexResults = flex.search(inputValue);
const foundDocuments = indexResults.map((index) => documents[index]);
displayFoundDocuments(foundDocuments.slice(0, 10));
})();As you can probably see, this is an oversimplification of how it actually works, but it’s not yet time to dig into the details. The next step is to display the matches. We use (TypeScript) React to do this, but the following pseudo code is easier to follow:
function displayFoundResults(documents) {
const container = document.createElement("ul");
documents.forEach(({url, title}) => {
const row = document.createElement("li");
const link = document.createElement("a");
link.href = url;
link.textContent = title;
row.appendChild(link);
container.appendChild(row);
});
document.querySelector('#search').appendChild(container);
}
Then with some CSS, we just display this as an overlay just beneath the <input> field. For example, we highlight each title according to the inputValue and various keystroke event handlers take care of highlighting the relevant row when you navigate up and down.
Ok, let’s dig deeper into the implementation details
We create the FlexSearch index just once and re-use it for every new keystroke. Because the user might type more while waiting for the network, it’s actually reactive so executes the actual search once all the JavaScript and the JSON XHR have arrived.
Before we dig into what this FlexSearch is, let’s talk about how the display actually works. For that we use a React library called downshift which handles all the interactions, displays, and makes sure the displayed search results are accessible. downshift is a mature library that handles a myriad of challenges with building a widget like that, especially the aspects of making it accessible.
So, what is this FlexSearch library? It’s another third party that makes sure that searching on titles is done with natural language in mind. It describes itself as the “Web’s fastest and most memory-flexible full-text search library with zero dependencies.” which is a lot more performant and accurate than attempting to simply look for one string in a long list of other strings.
Deciding which result to show first
In fairness, if the user types foreac, it’s not that hard to reduce a list of 10,000+ document titles down to only those that contain foreac in the title, then we decide which result to show first. The way we implement that is relying on pageview stats. We record, for every single MDN URL, which one gets the most pageviews as a form of determining “popularity”. The documents that most people decide to arrive on are most probably what the user was searching for.
Our build-process that generates the search-index.json file knows about each URLs number of pageviews. We actually don’t care about absolute numbers, but what we do care about is the relative differences. For example, we know that Array.prototype.forEach() (that’s one of the document titles) is a more popular page than TypedArray.prototype.forEach(), so we leverage that and sort the entries in search-index.json accordingly. Now, with FlexSearch doing the reduction, we use the “natural order” of the array as the trick that tries to give users the document they were probably looking for. It’s actually the same technique we use for Elasticsearch in our full site-search. More about that in: How MDN’s site-search works.
The easter egg: How to search by URL
Actually, it’s not a whimsical easter egg, but a feature that came from the fact that this autocomplete needs to work for our content creators. You see, when you work on the content in MDN you start a local “preview server” which is a complete copy of all documents but all running locally, as a static site, under http://localhost:5000. There, you don’t want to rely on a server to do searches. Content authors need to quickly move between documents, so much of the reason why the autocomplete search is done entirely in the client is because of that.
Commonly implemented in tools like the VSCode and Atom IDEs, you can do “fuzzy searches” to find and open files simply by typing portions of the file path. For example, searching for whmlemvo should find the file files/<b>w</b>eb/<b>h</b>t<b>ml</b>/<b>e</b>lement/<b>v</b>ide<b>o</b>. You can do that with MDN’s autocomplete search too. The way you do it is by typing / as the first input character.
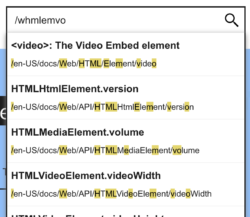
It makes it really quick to jump straight to a document if you know its URL but don’t want to spell it out exactly.
In fact, there’s another way to navigate and that is to first press / anywhere when browsing MDN, which activates the autocomplete search. Then you type / again, and you’re off to the races!
How to get really deep into the implementation details
The code for all of this is in the Yari repo which is the project that builds and previews all of the MDN content. To find the exact code, click into the client/src/search.tsx source code and you’ll find all the code for lazy-loading, searching, preloading, and displaying autocomplete searches.
About Peter Bengtsson
Peter is a staff web developer at Mozilla working on MDN Web Docs. He blogs on www.peterbe.com
11 comments