
Introduction
We have enabled Warp, a significant update to SpiderMonkey, by default in Firefox 83. SpiderMonkey is the JavaScript engine used in the Firefox web browser.
With Warp (also called WarpBuilder) we’re making big changes to our JIT (just-in-time) compilers, resulting in improved responsiveness, faster page loads and better memory usage. The new architecture is also more maintainable and unlocks additional SpiderMonkey improvements.
This post explains how Warp works and how it made SpiderMonkey faster.
How Warp works
Multiple JITs
The first step when running JavaScript is to parse the source code into bytecode, a lower-level representation. Bytecode can be executed immediately using an interpreter or can be compiled to native code by a just-in-time (JIT) compiler. Modern JavaScript engines have multiple tiered execution engines.
JS functions may switch between tiers depending on the expected benefit of switching:
- Interpreters and baseline JITs have fast compilation times, perform only basic code optimizations (typically based on Inline Caches), and collect profiling data.
- The Optimizing JIT performs advanced compiler optimizations but has slower compilation times and uses more memory, so is only used for functions that are warm (called many times).
The optimizing JIT makes assumptions based on the profiling data collected by the other tiers. If these assumptions turn out to be wrong, the optimized code is discarded. When this happens the function resumes execution in the baseline tiers and has to warm-up again (this is called a bailout).
For SpiderMonkey it looks like this (simplified):
Profiling data
Our previous optimizing JIT, Ion, used two very different systems for gathering profiling information to guide JIT optimizations. The first is Type Inference (TI), which collects global information about the types of objects used in the JS code. The second is CacheIR, a simple linear bytecode format used by the Baseline Interpreter and the Baseline JIT as the fundamental optimization primitive. Ion mostly relied on TI, but occasionally used CacheIR information when TI data was unavailable.
With Warp, we’ve changed our optimizing JIT to rely solely on CacheIR data collected by the baseline tiers. Here’s what this looks like:
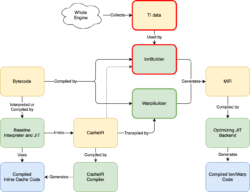
There’s a lot of information here, but the thing to note is that we’ve replaced the IonBuilder frontend (outlined in red) with the simpler WarpBuilder frontend (outlined in green). IonBuilder and WarpBuilder both produce Ion MIR, an intermediate representation used by the optimizing JIT backend.
Where IonBuilder used TI data gathered from the whole engine to generate MIR, WarpBuilder generates MIR using the same CacheIR that the Baseline Interpreter and Baseline JIT use to generate Inline Caches (ICs). As we’ll see below, the tighter integration between Warp and the lower tiers has several advantages.
How CacheIR works
Consider the following JS function:
function f(o) {
return o.x - 1;
}The Baseline Interpreter and Baseline JIT use two Inline Caches for this function: one for the property access (o.x), and one for the subtraction. That’s because we can’t optimize this function without knowing the types of o and o.x.
The IC for the property access, o.x, will be invoked with the value of o. It can then attach an IC stub (a small piece of machine code) to optimize this operation. In SpiderMonkey this works by first generating CacheIR (a simple linear bytecode format, you could think of it as an optimization recipe). For example, if o is an object and x is a simple data property, we generate this:
GuardToObject inputId 0 GuardShape objId 0, shapeOffset 0 LoadFixedSlotResult objId 0, offsetOffset 8 ReturnFromIC
Here we first guard the input (o) is an object, then we guard on the object’s shape (which determines the object’s properties and layout), and then we load the value of o.x from the object’s slots.
Note that the shape and the property’s index in the slots array are stored in a separate data section, not baked into the CacheIR or IC code itself. The CacheIR refers to the offsets of these fields with shapeOffset and offsetOffset. This allows many different IC stubs to share the same generated code, reducing compilation overhead.
The IC then compiles this CacheIR snippet to machine code. Now, the Baseline Interpreter and Baseline JIT can execute this operation quickly without calling into C++ code.
The subtraction IC works the same way. If o.x is an int32 value, the subtraction IC will be invoked with two int32 values and the IC will generate the following CacheIR to optimize that case:
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32SubResult lhsId 0, rhsId 1 ReturnFromIC
This means we first guard the left-hand side is an int32 value, then we guard the right-hand side is an int32 value, and we can then perform the int32 subtraction and return the result from the IC stub to the function.
The CacheIR instructions capture everything we need to do to optimize an operation. We have a few hundred CacheIR instructions, defined in a YAML file. These are the building blocks for our JIT optimization pipeline.
Warp: Transpiling CacheIR to MIR
If a JS function gets called many times, we want to compile it with the optimizing compiler. With Warp there are three steps:
- WarpOracle: runs on the main thread, creates a snapshot that includes the Baseline CacheIR data.
- WarpBuilder: runs off-thread, builds MIR from the snapshot.
- Optimizing JIT Backend: also runs off-thread, optimizes the MIR and generates machine code.
The WarpOracle phase runs on the main thread and is very fast. The actual MIR building can be done on a background thread. This is an improvement over IonBuilder, where we had to do MIR building on the main thread because it relied on a lot of global data structures for Type Inference.
WarpBuilder has a transpiler to transpile CacheIR to MIR. This is a very mechanical process: for each CacheIR instruction, it just generates the corresponding MIR instruction(s).
Putting this all together we get the following picture (click for a larger version):

We’re very excited about this design: when we make changes to the CacheIR instructions, it automatically affects all of our JIT tiers (see the blue arrows in the picture above). Warp is simply weaving together the function’s bytecode and CacheIR instructions into a single MIR graph.
Our old MIR builder (IonBuilder) had a lot of complicated code that we don’t need in WarpBuilder because all the JS semantics are captured by the CacheIR data we also need for ICs.
Trial Inlining: type specializing inlined functions
Optimizing JavaScript JITs are able to inline JavaScript functions into the caller. With Warp we are taking this a step further: Warp is also able to specialize inlined functions based on the call site.
Consider our example function again:
function f(o) {
return o.x - 1;
}This function may be called from multiple places, each passing a different shape of object or different types for o.x. In this case, the inline caches will have polymorphic CacheIR IC stubs, even if each of the callers only passes a single type. If we inline the function in Warp, we won’t be able to optimize it as well as we want.
To solve this problem, we introduced a novel optimization called Trial Inlining. Every function has an ICScript, which stores the CacheIR and IC data for that function. Before we Warp-compile a function, we scan the Baseline ICs in that function to search for calls to inlinable functions. For each inlinable call site, we create a new ICScript for the callee function. Whenever we call the inlining candidate, instead of using the default ICScript for the callee, we pass in the new specialized ICScript. This means that the Baseline Interpreter, Baseline JIT, and Warp will now collect and use information specialized for that call site.
Trial inlining is very powerful because it works recursively. For example, consider the following JS code:
function callWithArg(fun, x) {
return fun(x);
}
function test(a) {
var b = callWithArg(x => x + 1, a);
var c = callWithArg(x => x - 1, a);
return b + c;
}
When we perform trial inlining for the test function, we will generate a specialized ICScript for each of the callWithArg calls. Later on, we attempt recursive trial inlining in those caller-specialized callWithArg functions, and we can then specialize the fun call based on the caller. This was not possible in IonBuilder.
When it’s time to Warp-compile the test function, we have the caller-specialized CacheIR data and can generate optimal code.
This means we build up the inlining graph before functions are Warp-compiled, by (recursively) specializing Baseline IC data at call sites. Warp then just inlines based on that without needing its own inlining heuristics.
Optimizing built-in functions
IonBuilder was able to inline certain built-in functions directly. This is especially useful for things like Math.abs and Array.prototype.push, because we can implement them with a few machine instructions and that’s a lot faster than calling the function.
Because Warp is driven by CacheIR, we decided to generate optimized CacheIR for calls to these functions.
This means these built-ins are now also properly optimized with IC stubs in our Baseline Interpreter and JIT. The new design leads us to generate the right CacheIR instructions, which then benefits not just Warp but all of our JIT tiers.
For example, let’s look at a Math.pow call with two int32 arguments. We generate the following CacheIR:
LoadArgumentFixedSlot resultId 1, slotIndex 3 GuardToObject inputId 1 GuardSpecificFunction funId 1, expectedOffset 0, nargsAndFlagsOffset 8 LoadArgumentFixedSlot resultId 2, slotIndex 1 LoadArgumentFixedSlot resultId 3, slotIndex 0 GuardToInt32 inputId 2 GuardToInt32 inputId 3 Int32PowResult lhsId 2, rhsId 3 ReturnFromIC
First, we guard that the callee is the built-in pow function. Then we load the two arguments and guard they are int32 values. Then we perform the pow operation specialized for two int32 arguments and return the result of that from the IC stub.
Furthermore, the Int32PowResult CacheIR instruction is also used to optimize the JS exponentiation operator, x ** y. For that operator we might generate:
GuardToInt32 inputId 0 GuardToInt32 inputId 1 Int32PowResult lhsId 0, rhsId 1 ReturnFromIC
When we added Warp transpiler support for Int32PowResult, Warp was able to optimize both the exponentiation operator and Math.pow without additional changes. This is a nice example of CacheIR providing building blocks that can be used for optimizing different operations.
Results
Performance
Warp is faster than Ion on many workloads. The picture below shows a couple examples: we had a 20% improvement on Google Docs load time, and we are about 10-12% faster on the Speedometer benchmark:

We’ve seen similar page load and responsiveness improvements on other JS-intensive websites such as Reddit and Netflix. Feedback from Nightly users has been positive as well.
The improvements are largely because basing Warp on CacheIR lets us remove the code throughout the engine that was required to track the global type inference data used by IonBuilder, resulting in speedups across the engine.
The old system required all functions to track type information that was only useful in very hot functions. With Warp, the profiling information (CacheIR) used to optimize Warp is also used to speed up code running in the Baseline Interpreter and Baseline JIT.
Warp is also able to do more work off-thread and requires fewer recompilations (the previous design often overspecialized, resulting in many bailouts).
Synthetic JS benchmarks
Warp is currently slower than Ion on certain synthetic JS benchmarks such as Octane and Kraken. This isn’t too surprising because Warp has to compete with almost a decade of optimization work and tuning for those benchmarks specifically.
We believe these benchmarks are not representative of modern JS code (see also the V8 team’s blog post on this) and the regressions are outweighed by the large speedups and other improvements elsewhere.
That said, we will continue to optimize Warp the coming months and we expect to see improvements on all of these workloads going forward.
Memory usage
Removing the global type inference data also means we use less memory. For example the picture below shows JS code in Firefox uses 8% less memory when loading a number of websites (tp6):
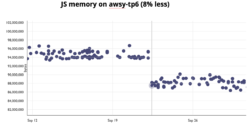
We expect this number to improve the coming months as we remove the old code and are able to simplify more data structures.
Faster GCs
The type inference data also added a lot of overhead to garbage collection. We noticed some big improvements in our telemetry data for GC sweeping (one of the phases of our GC) when we enabled Warp by default in Firefox Nightly on September 23:

Maintainability and Developer Velocity
Because WarpBuilder is a lot more mechanical than IonBuilder, we’ve found the code to be much simpler, more compact, more maintainable and less error-prone. By using CacheIR everywhere, we can add new optimizations with much less code. This makes it easier for the team to improve performance and implement new features.
What’s next?
With Warp we have replaced the frontend (the MIR building phase) of the IonMonkey JIT. The next step is removing the old code and architecture. This will likely happen in Firefox 85. We expect additional performance and memory usage improvements from that.
We will also continue to incrementally simplify and optimize the backend of the IonMonkey JIT. We believe there’s still a lot of room for improvement for JS-intensive workloads.
Finally, because all of our JITs are now based on CacheIR data, we are working on a tool to let us (and web developers) explore the CacheIR data for a JS function. We hope this will help developers understand JS performance better.
Acknowledgements
Most of the work on Warp was done by Caroline Cullen, Iain Ireland, Jan de Mooij, and our amazing contributors André Bargull and Tom Schuster. The rest of the SpiderMonkey team provided us with a lot of feedback and ideas. Christian Holler and Gary Kwong reported various fuzz bugs.
Thanks to Ted Campbell, Caroline Cullen, Steven DeTar, Matthew Gaudet, Melissa Thermidor, and especially Iain Ireland for their great feedback and suggestions for this post.
About Jan de Mooij
Jan is a software engineer at Mozilla where he works on SpiderMonkey, the JavaScript Engine in Firefox. He lives in the Netherlands.
8 comments