
Background: RegExps in SpiderMonkey
Regular expressions – commonly known as RegExps – are a powerful tool in JavaScript for manipulating strings. They provide a rich syntax to describe and capture character information. They’re also heavily used, so it’s important for SpiderMonkey (the JavaScript engine in Firefox) to optimize them well.
Over the years, we’ve had several approaches to RegExps. Conveniently, there’s a fairly clear dividing line between the RegExp engine and the rest of SpiderMonkey. It’s still not easy to replace the RegExp engine, but it can be done without too much impact on the rest of SpiderMonkey.
In 2014, we took advantage of this flexibility to replace YARR (our previous RegExp engine) with a forked copy of Irregexp, the engine used in V8. This raised a tricky question: how do you make code designed for one engine work inside another? Irregexp uses a number of V8 APIs, including core concepts like the representation of strings, the object model, and the garbage collector.
At the time, we chose to heavily rewrite Irregexp to use our own internal APIs. This made it easier for us to work with, but much harder to import new changes from upstream. RegExps were changing relatively infrequently, so this seemed like a good trade-off. At first, it worked out well for us. When new features like the ‘\u’ flag were introduced, we added them to Irregexp. Over time, though, we began to fall behind. ES2018 added four new RegExp features: the dotAll flag, named capture groups, Unicode property escapes, and look-behind assertions. The V8 team added Irregexp support for those features, but the SpiderMonkey copy of Irregexp had diverged enough to make it difficult to apply the same changes.
We began to rethink our approach. Was there a way for us to support modern RegExp features, with less of an ongoing maintenance burden? What would our RegExp engine look like if we prioritized keeping it up to date? How close could we stay to upstream Irregexp?
Solution: Building a shim layer for Irregexp
The answer, it turns out, is very close indeed. As of the writing of this post, SpiderMonkey is using the very latest version of Irregexp, imported from the V8 repository, with no changes other than mechanically rewritten #include statements. Refreshing the import requires minimal work beyond running an update script. We are actively contributing bug reports and patches upstream.
How did we get to this point? Our approach was to build a shim layer between SpiderMonkey and Irregexp. This shim provides Irregexp with access to all the functionality that it normally gets from V8: everything from memory allocation, to code generation, to a variety of utility functions and data structures.
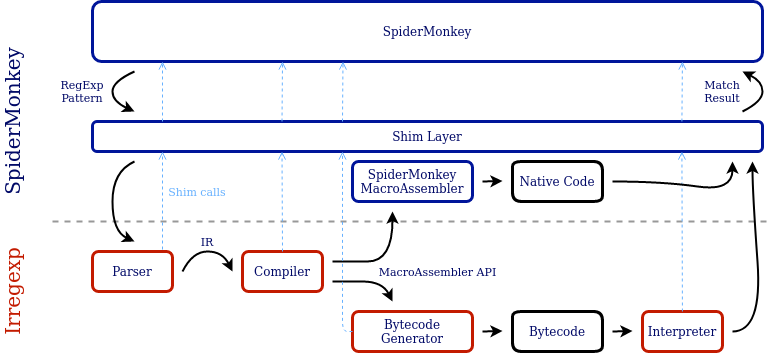
This took some work. A lot of it was a straightforward matter of hooking things together. For example, the Irregexp parser and compiler use V8’s Zone, an arena-style memory allocator, to allocate temporary objects and discard them efficiently. SpiderMonkey’s equivalent is called a LifoAlloc, but it has a very similar interface. Our shim was able to implement calls to Zone methods by forwarding them directly to their LifoAlloc equivalents.
Other areas had more interesting solutions. A few examples:
Code Generation
Irregexp has two strategies for executing RegExps: a bytecode interpreter, and a just-in-time compiler. The former generates denser code (using less memory), and can be used on systems where native code generation is not available. The latter generates code that runs faster, which is important for RegExps that are executed repeatedly. Both SpiderMonkey and V8 interpret RegExps on first use, then tier up to compiling them later.
Tools for generating native code are very engine-specific. Fortunately, Irregexp has a well-designed API for code generation, called RegExpMacroAssembler. After parsing and optimizing the RegExp, the RegExpCompiler will make a series of calls to a RegExpMacroAssembler to generate code. For example, to determine whether the next character in the string matches a particular character, the compiler will call CheckCharacter. To backtrack if a back-reference fails to match, the compiler will call CheckNotBackReference.
Overall, there are roughly 40 available operations. Together, these operations can represent any JavaScript RegExp. The macro-assembler is responsible for converting these abstract operations into a final executable form. V8 contains no less than nine separate implementations of RegExpMacroAssembler: one for each of the eight architectures it supports, and a final implementation that generates bytecode for the interpreter. SpiderMonkey can reuse the bytecode generator and the interpreter, but we needed our own macro-assembler. Fortunately, a couple of things were working in our favour.
First, SpiderMonkey’s native code generation tools work at a higher level than V8’s. Instead of having to implement a macro-assembler for each architecture, we only needed one, which could target any supported machine. Second, much of the work to implement RegExpMacroAssembler using SpiderMonkey’s code generator had already been done for our first import of Irregexp. We had to make quite a few changes to support new features (especially look-behind references), but the existing code gave us an excellent starting point.
Garbage Collection
Memory in JavaScript is automatically managed. When memory runs short, the garbage collector (GC) walks through the program and cleans up any memory that is no longer in use. If you’re writing JavaScript, this happens behind the scenes. If you’re implementing JavaScript, though, it means you have to be careful. When you’re working with something that might be garbage-collected – a string, say, that you’re matching against a RegExp – you need to inform the GC. Otherwise, if you call a function that triggers a garbage collection, the GC might move your string somewhere else (or even get rid of it entirely, if you were the only remaining reference). For obvious reasons, this is a bad thing. The process of telling the GC about the objects you’re using is called rooting. One of the most interesting challenges for our shim implementation was the difference between the way SpiderMonkey and V8 root things.
SpiderMonkey creates its roots right on the C++ stack. For example, if you want to root a string, you create a Rooted<JSString*> that lives in your local stack frame. When your function returns, the root disappears and the GC is free to collect your JSString. In V8, you create a Handle. Under the hood, V8 creates a root and stores it in a parallel stack. The lifetime of roots in V8 is controlled by HandleScope objects, which mark a point on the root stack when they are created, and clear out every root newer than the marked point when they are destroyed.
To make our shim work, we implemented our own miniature version of V8’s HandleScopes. As an extra complication, some types of objects are garbage-collected in V8, but are regular non-GC objects in SpiderMonkey. To handle those objects (no pun intended), we added a parallel stack of “PseudoHandles”, which look like normal Handles to Irregexp, but are backed by (non-GC) unique pointers.
Collaboration
None of this would have been possible without the support and advice of the V8 team. In particular, Jakob Gruber has been exceptionally helpful. It turns out that this project aligns nicely with a pre-existing desire on the V8 team to make Irregexp more independent of V8. While we tried to make our shim as complete as possible, there were some circumstances where upstream changes were the best solution. Many of those changes were quite minor. Some were more interesting.
Some code at the interface between V8 and Irregexp turned out to be too hard to use in SpiderMonkey. For example, to execute a compiled RegExp, Irregexp calls NativeRegExpMacroAssembler::Match. That function was tightly entangled with V8’s string representation. The string implementations in the two engines are surprisingly close, but not so close that we could share the code. Our solution was to move that code out of Irregexp entirely, and to hide other unusable code behind an embedder-specific #ifdef. These changes are not particularly interesting from a technical perspective, but from a software engineering perspective they give us a clearer sense of where the API boundary might be drawn in a future project to separate Irregexp from V8.
As our prototype implementation neared completion, we realized that one of the remaining failures in SpiderMonkey’s test suite was also failing in V8. Upon investigation, we determined that there was a subtle mismatch between Irregexp and the JavaScript specification when it came to case-insensitive, non-unicode RegExps. We contributed a patch upstream to rewrite Irregexp’s handling of characters with non-standard case-folding behaviour (like ‘ß’, LATIN SMALL LETTER SHARP S, which gives “SS” when upper-cased).
Our opportunities to help improve Irregexp didn’t stop there. Shortly after we landed the new version of Irregexp in Firefox Nightly, our intrepid fuzzing team discovered a convoluted RegExp that crashed in debug builds of both SpiderMonkey and V8. Fortunately, upon further investigation, it turned out to be an overly strict assertion. It did, however, inspire some additional code quality improvements in the RegExp interpreter.
Conclusion: Up to date and ready to go
What did we get for all this work, aside from some improved subscores on the JetStream2 benchmark?
Most importantly, we got full support for all the new RegExp features. Unicode property escapes and look-behind references only affect RegExp matching, so they worked as soon as the shim was complete. The dotAll flag only required a small amount of additional work to support. Named captures involved slightly more support from the rest of SpiderMonkey, but a couple of weeks after the new engine was enabled, named captures landed too. (While testing them, we turned up one last bug in the equivalent V8 code.) This brings Firefox fully up to date with the latest ECMAScript standards for JavaScript.
We also have a stronger foundation for future RegExp support. More collaboration on Irregexp is mutually beneficial. SpiderMonkey can add new RegExp syntax much more quickly. V8 gains an extra set of eyes and hands to find and fix bugs. Hypothetical future embedders of Irregexp have a proven starting point.
The new engine is available in Firefox 78, which is currently in our Developer Edition browser release. Hopefully, this work will be the basis for RegExps in Firefox for years to come.
About Iain Ireland
Iain works for Mozilla on SpiderMonkey, the JavaScript engine. He lives in Canada.
5 comments