
Pyodide is an experimental project from Mozilla to create a full Python data science stack that runs entirely in the browser.

The impetus for Pyodide came from working on another Mozilla project, Iodide, which we presented in an earlier post. Iodide is a tool for data science experimentation and communication based on state-of-the-art web technologies. Notably, it’s designed to perform data science computation within the browser rather than on a remote kernel.
Unfortunately, the “language we all have” in the browser, JavaScript, doesn’t have a mature suite of data science libraries, and it’s missing a number of features that are useful for numerical computing, such as operator overloading. We still think it’s worthwhile to work on changing that and moving the JavaScript data science ecosystem forward. In the meantime, we’re also taking a shortcut: we’re meeting data scientists where they are by bringing the popular and mature Python scientific stack to the browser.
It’s also been argued more generally that Python not running in the browser represents an existential threat to the language—with so much user interaction happening on the web or on mobile devices, it needs to work there or be left behind. Therefore, while Pyodide tries to meet the needs of Iodide first, it is engineered to be useful on its own as well.
Pyodide gives you a full, standard Python interpreter that runs entirely in the browser, with full access to the browser’s Web APIs. In the example above (50 MB download), the density of calls to the City of Oakland, California’s “311” local information service is plotted in 3D. The data loading and processing is performed in Python, and then it hands off to Javascript and WebGL for the plotting.
For another quick example, here’s a simple doodling script that lets you draw in the browser window:
from js import document, iodide
canvas = iodide.output.element('canvas')
canvas.setAttribute('width', 450)
canvas.setAttribute('height', 300)
context = canvas.getContext("2d")
context.strokeStyle = "#df4b26"
context.lineJoin = "round"
context.lineWidth = 5
pen = False
lastPoint = (0, 0)
def onmousemove(e):
global lastPoint
if pen:
newPoint = (e.offsetX, e.offsetY)
context.beginPath()
context.moveTo(lastPoint[0], lastPoint[1])
context.lineTo(newPoint[0], newPoint[1])
context.closePath()
context.stroke()
lastPoint = newPoint
def onmousedown(e):
global pen, lastPoint
pen = True
lastPoint = (e.offsetX, e.offsetY)
def onmouseup(e):
global pen
pen = False
canvas.addEventListener('mousemove', onmousemove)
canvas.addEventListener('mousedown', onmousedown)
canvas.addEventListener('mouseup', onmouseup)
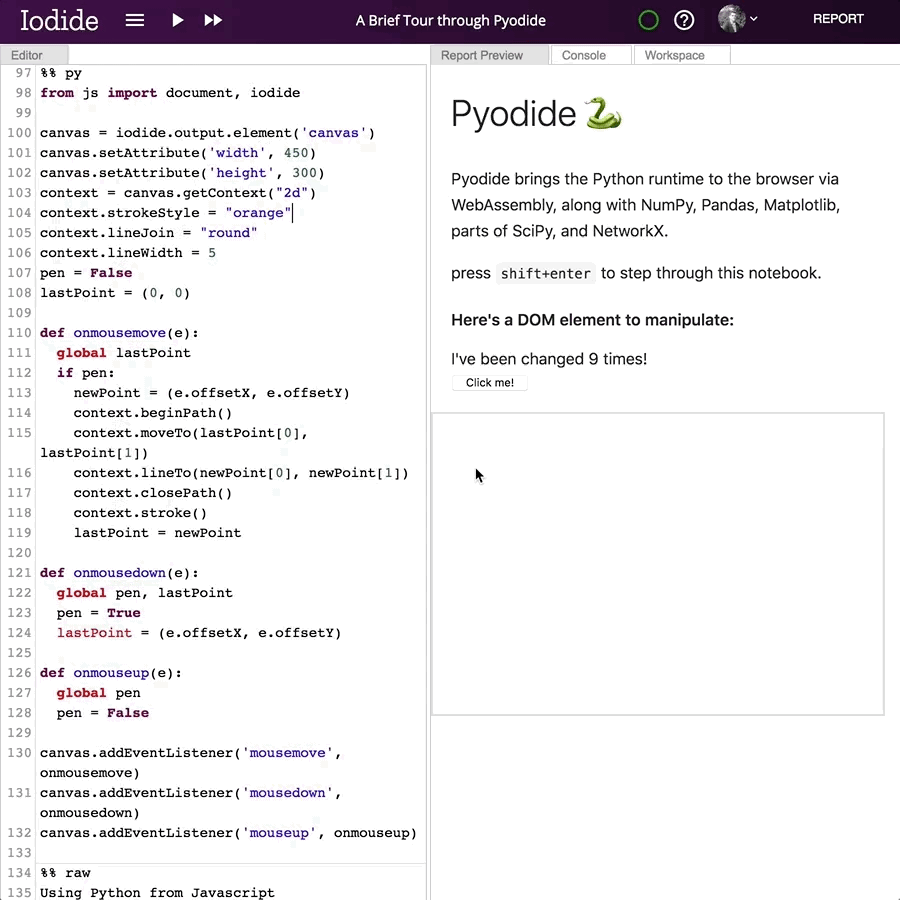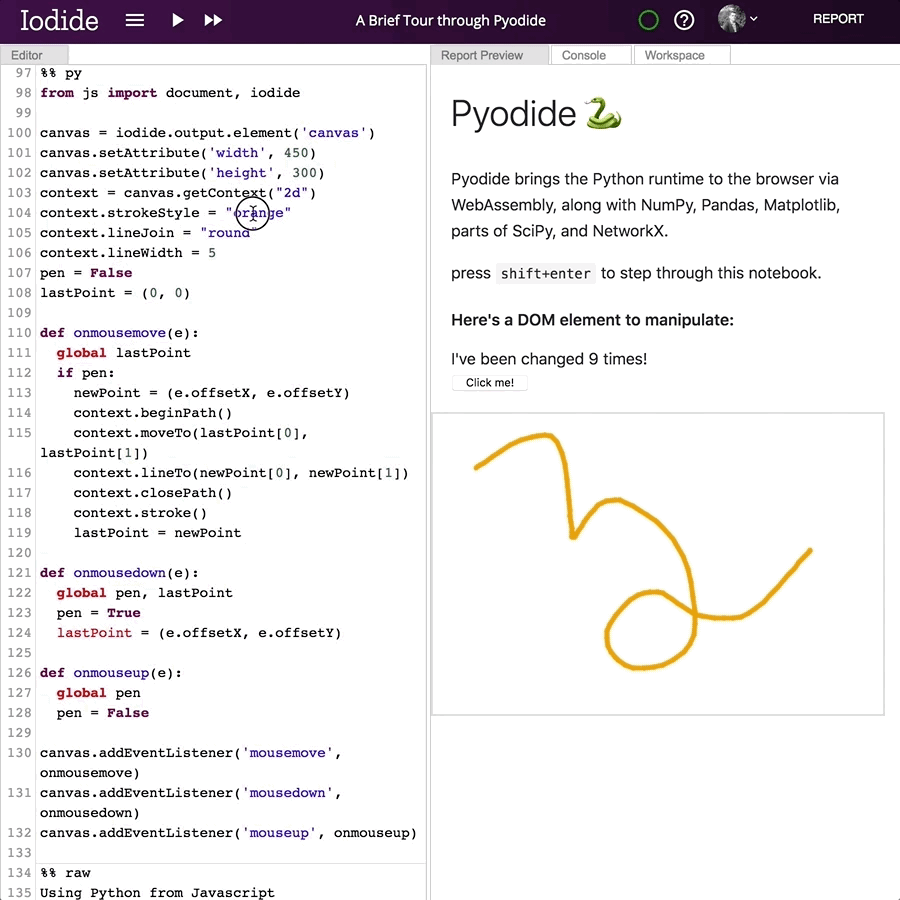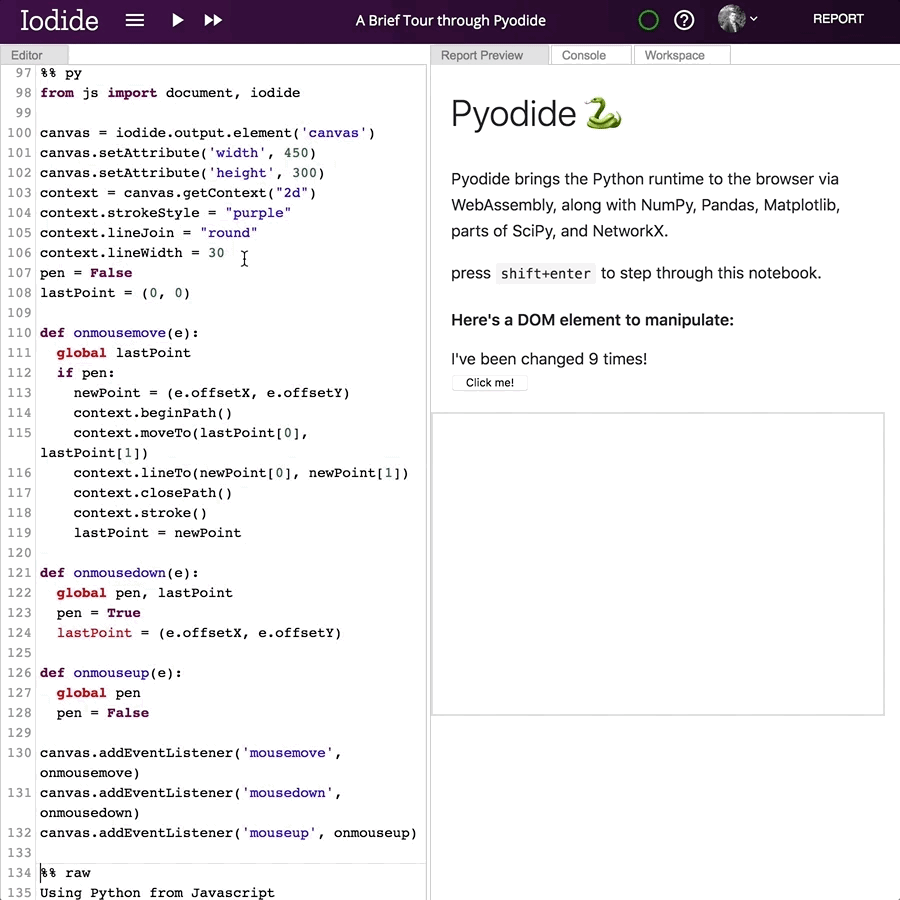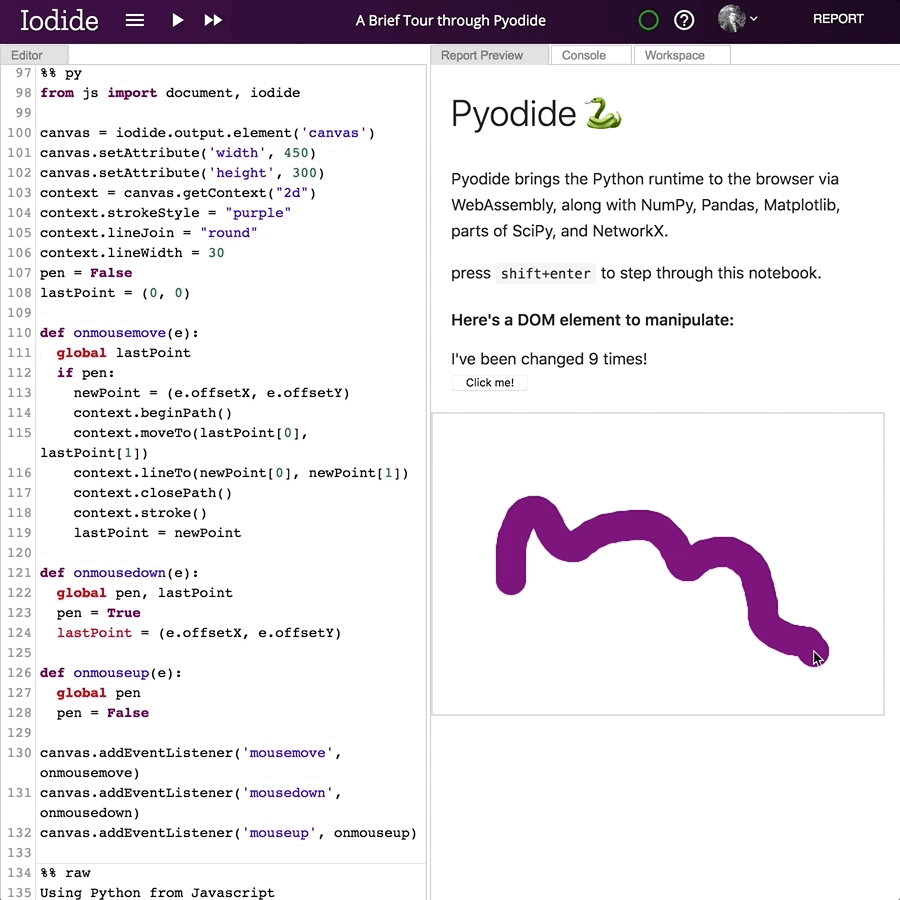
And this is what it looks like:
The best way to learn more about what Pyodide can do is to just go and try it! There is a demo notebook (50MB download) that walks through the high-level features. The rest of this post will be more of a technical deep-dive into how it works.
Prior art
There were already a number of impressive projects bringing Python to the browser when we started Pyodide. Unfortunately, none addressed our specific goal of supporting a full-featured mainstream data science stack, including NumPy, Pandas, Scipy, and Matplotlib.
Projects such as Transcrypt transpile (convert) Python to JavaScript. Because the transpilation step itself happens in Python, you either need to do all of the transpiling ahead of time, or communicate with a server to do that work. This doesn’t really meet our goal of letting the user write Python in the browser and run it without any outside help.
Projects like Brython and Skulpt are rewrites of the standard Python interpreter to JavaScript, therefore, they can run strings of Python code directly in the browser. Unfortunately, since they are entirely new implementations of Python, and in JavaScript to boot, they aren’t compatible with Python extensions written in C, such as NumPy and Pandas. Therefore, there’s no data science tooling.
PyPyJs is a build of the alternative just-in-time compiling Python implementation, PyPy, to the browser, using emscripten. It has the potential to run Python code really quickly, for the same reasons that PyPy does. Unfortunately, it has the same issues with performance with C extensions that PyPy does.
All of these approaches would have required us to rewrite the scientific computing tools to achieve adequate performance. As someone who used to work a lot on Matplotlib, I know how many untold person-hours that would take: other projects have tried and stalled, and it’s certainly a lot more work than our scrappy upstart team could handle. We therefore needed to build a tool that was based as closely as possible on the standard implementations of Python and the scientific stack that most data scientists already use.
After a discussion with some of Mozilla’s WebAssembly wizards, we saw that the key to building this was emscripten and WebAssembly: technologies to port existing code written in C to the browser. That led to the discovery of an existing but dormant build of Python for emscripten, cpython-emscripten, which was ultimately used as the basis for Pyodide.
emscripten and WebAssembly
There are many ways of describing what emscripten is, but most importantly for our purposes, it provides two things:
- A compiler from C/C++ to WebAssembly
- A compatibility layer that makes the browser feel like a native computing environment
WebAssembly is a new language that runs in modern web-browsers, as a complement to JavaScript. It’s a low-level assembly-like language that runs with near-native performance intended as a compilation target for low-level languages like C and C++. Notably, the most popular interpreter for Python, called CPython, is implemented in C, so this is the kind of thing emscripten was created for.
Pyodide is put together by:
- Downloading the source code of the mainstream Python interpreter (CPython), and the scientific computing packages (NumPy, etc.)
- Applying a very small set of changes to make them work in the new environment
- Compiling them to WebAssembly using emscripten’s compiler
If you were to just take this WebAssembly and load it in the browser, things would look very different to the Python interpreter than they do when running directly on top of your operating system. For example, web browsers don’t have a file system (a place to load and save files). Fortunately, emscripten provides a virtual file system, written in JavaScript, that the Python interpreter can use. By default, these virtual “files” reside in volatile memory in the browser tab, and they disappear when you navigate away from the page. (emscripten also provides a way for the file system to store things in the browser’s persistent local storage, but Pyodide doesn’t use it.)
By emulating the file system and other features of a standard computing environment, emscripten makes moving existing projects to the web browser possible with surprisingly few changes. (Some day, we may move to using WASI as the system emulation layer, but for now emscripten is the more mature and complete option).
Putting it all together, to load Pyodide in your browser, you need to download:
- The compiled Python interpreter as WebAssembly.
- A bunch of JavaScript provided by emscripten that provides the system emulation.
- A packaged file system containing all the files the Python interpreter will need, most notably the Python standard library.
These files can be quite large: Python itself is 21MB, NumPy is 7MB, and so on. Fortunately, these packages only have to be downloaded once, after which they are stored in the browser’s cache.
Using all of these pieces in tandem, the Python interpreter can access the files in its standard library, start up, and then start running the user’s code.
What works and doesn’t work
We run CPython’s unit tests as part of Pyodide’s continuous testing to get a handle on what features of Python do and don’t work. Some things, like threading, don’t work now, but with the newly-available WebAssembly threads, we should be able to add support in the near future.
Other features, like low-level networking sockets, are unlikely to ever work because of the browser’s security sandbox. Sorry to break it to you, your hopes of running a Python minecraft server inside your web browser are probably still a long way off. Nevertheless, you can still fetch things over the network using the browser’s APIs (more details below).
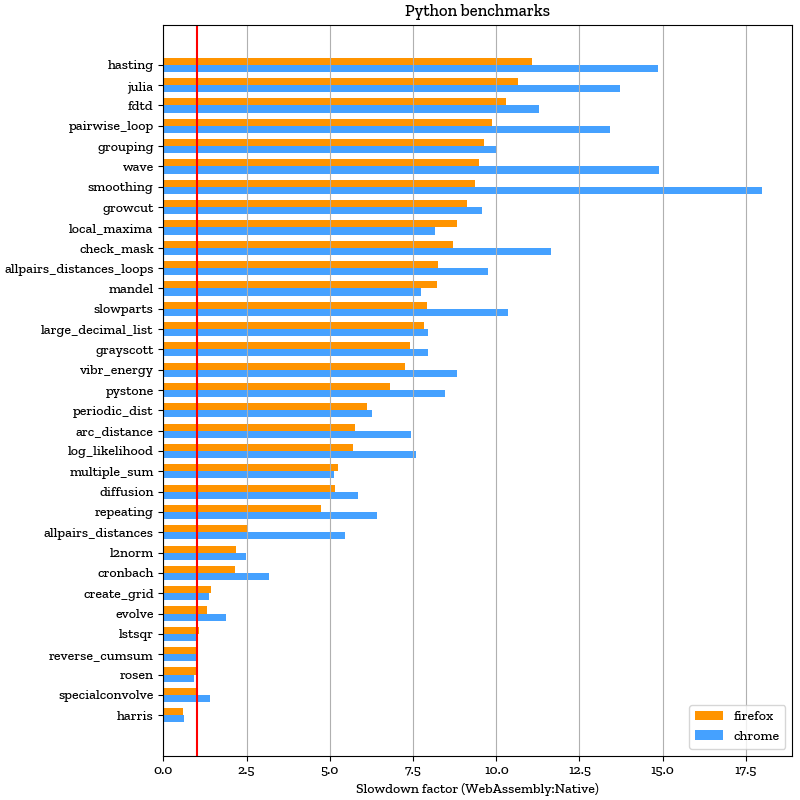
How fast is it?
Running the Python interpreter inside a JavaScript virtual machine adds a performance penalty, but that penalty turns out to be surprisingly small — in our benchmarks, around 1x-12x slower than native on Firefox and 1x-16x slower on Chrome. Experience shows that this is very usable for interactive exploration.
Notably, code that runs a lot of inner loops in Python tends to be slower by a larger factor than code that relies on NumPy to perform its inner loops. Below are the results of running various Pure Python and Numpy benchmarks in Firefox and Chrome compared to natively on the same hardware.
Interaction between Python and JavaScript
If all Pyodide could do is run Python code and write to standard out, it would amount to a cool trick, but it wouldn’t be a practical tool for real work. The real power comes from its ability to interact with browser APIs and other JavaScript libraries at a very fine level. WebAssembly has been designed to easily interact with the JavaScript running in the browser. Since we’ve compiled the Python interpreter to WebAssembly, it too has deep integration with the JavaScript side.
Pyodide implicitly converts many of the built-in data types between Python and JavaScript. Some of these conversions are straightforward and obvious, but as always, it’s the corner cases that are interesting.
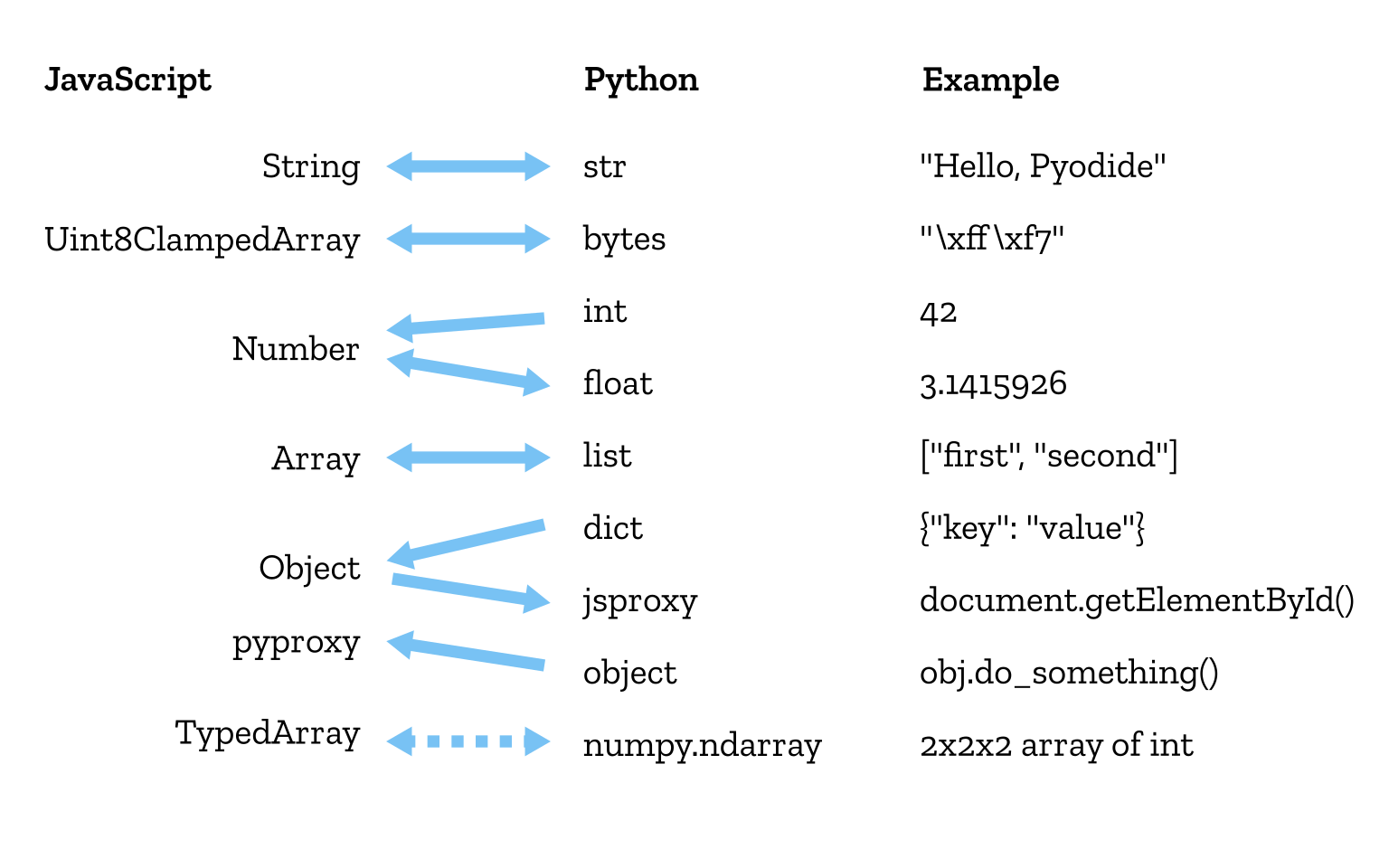
Python treats dicts and object instances as two distinct types. dicts (dictionaries) are just mappings of keys to values. On the other hand, objects generally have methods that “do something” to those objects. In JavaScript, these two concepts are conflated into a single type called Object. (Yes, I’ve oversimplified here to make a point.)
Without really understanding the developer’s intention for the JavaScript Object, it’s impossible to efficiently guess whether it should be converted to a Python dict or object. Therefore, we have to use a proxy and let “duck typing” resolve the situation.
Proxies are wrappers around a variable in the other language. Rather than simply reading the variable in JavaScript and rewriting it in terms of Python constructs, as is done for the basic types, the proxy holds on to the original JavaScript variable and calls methods on it “on demand”. This means that any JavaScript variable, no matter how custom, is fully accessible from Python. Proxies work in the other direction, too.
Duck typing is the principle that rather than asking a variable “are you a duck?” you ask it “do you walk like a duck?” and “do you quack like a duck?” and infer from that that it’s probably a duck, or at least does duck-like things. This allows Pyodide to defer the decision on how to convert the JavaScript Object: it wraps it in a proxy and lets the Python code using it decide how to handle it. Of course, this doesn’t always work, the duck may actually be a rabbit. Thus, Pyodide also provides ways to explicitly handle these conversions.
It’s this tight level of integration that allows a user to do their data processing in Python, and then send it to JavaScript for visualization. For example, in our Hipster Band Finder demo, we show loading and analyzing a data set in Python’s Pandas, and then sending it to JavaScript’s Plotly for visualization.
Accessing Web APIs and the DOM
Proxies also turn out to be the key to accessing the Web APIs, or the set of functions the browser provides that make it do things. For example, a large part of the Web API is on the document object. You can get that from Python by doing:
from js import documentThis imports the document object in JavaScript over to the Python side as a proxy. You can start calling methods on it from Python:
document.getElementById("myElement")All of this happens through proxies that look up what the document object can do on-the-fly. Pyodide doesn’t need to include a comprehensive list of all of the Web APIs the browser has.
Of course, using the Web API directly doesn’t always feel like the most Pythonic or user-friendly way to do things. It would be great to see the creation of a user-friendly Python wrapper for the Web API, much like how jQuery and other libraries have made the Web API easier to use from JavaScript. Let us know if you’re interested in working on such a thing!
Multidimensional Arrays
There are important data types that are specific to data science, and Pyodide has special support for these as well. Multidimensional arrays are collections of (usually numeric) values, all of the same type. They tend to be quite large, and knowing that every element is the same type has real performance advantages over Python’s lists or JavaScript’s Arrays that can hold elements of any type.
In Python, NumPy arrays are the most common implementation of multidimensional arrays. JavaScript has TypedArrays, which contain only a single numeric type, but they are single dimensional, so the multidimensional indexing needs to be built on top.
Since in practice these arrays can get quite large, we don’t want to copy them between language runtimes. Not only would that take a long time, but having two copies in memory simultaneously would tax the limited memory the browser has available.
Fortunately, we can share this data without copying. Multidimensional arrays are usually implemented with a small amount of metadata that describes the type of the values, the shape of the array and the memory layout. The data itself is referenced from that metadata by a pointer to another place in memory. It’s an advantage that this memory lives in a special area called the “WebAssembly heap,” which is accessible from both JavaScript and Python. We can simply copy the metadata (which is quite small) back and forth between the languages, keeping the pointer to the data referring to the WebAssembly heap.
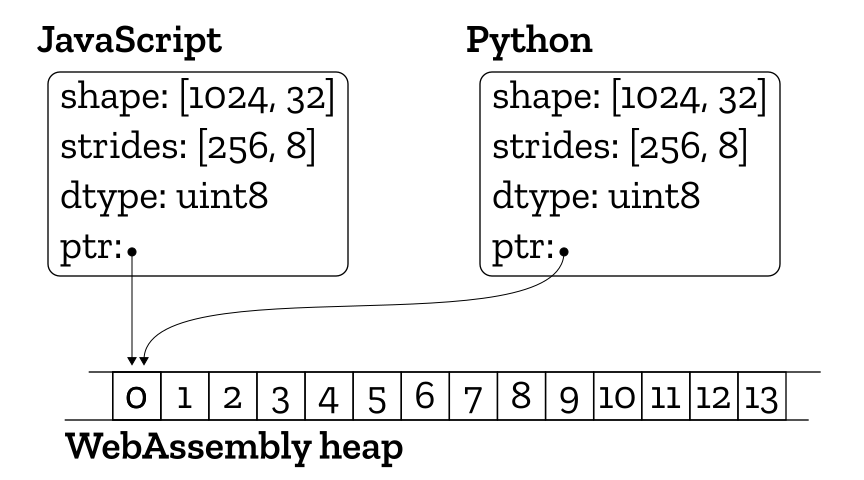
This idea is currently implemented for single-dimensional arrays, with a suboptimal workaround for higher-dimensional arrays. We need improvements to the JavaScript side to have a useful object to work with there. To date there is no one obvious choice for JavaScript multidimensional arrays. Promising projects such as Apache Arrow and xnd’s ndarray are working exactly in this problem space, and aim to make the passing of in-memory structured data between language runtimes easier. Investigations are ongoing to build off of these projects to make this sort of data conversion more powerful.
Real-time interactive visualization
One of the advantages of doing the data science computation in the browser rather than in a remote kernel, as Jupyter does, is that interactive visualizations don’t have to communicate over a network to reprocess and redisplay their data. This greatly reduces the latency — the round trip time it takes from the time the user moves their mouse to the time an updated plot is displayed to the screen.
Making that work requires all of the technical pieces described above to function together in tandem. Let’s look at this interactive example that shows how log-normal distributions work using matplotlib. First, the random data is generated in Python using Numpy. Next, Matplotlib takes that data, and draws it using its built-in software renderer. It sends the pixels back to the JavaScript side using Pyodide’s support for zero-copy array sharing, where they are finally rendered into an HTML canvas. The browser then handles getting those pixels to the screen. Mouse and keyboard events used to support interactivity are handled by callbacks that call from the web browser back into Python.

Packaging
The Python scientific stack is not a monolith—it’s actually a collection of loosely-affiliated packages that work together to create a productive environment. Among the most popular are NumPy (for numerical arrays and basic computation), Scipy (for more sophisticated general-purpose computation, such as linear algebra), Matplotlib (for visualization) and Pandas (for tabular data or “data frames”). You can see the full and constantly updated list of the packages that Pyodide builds for the browser here.
Some of these packages were quite straightforward to bring into Pyodide. Generally, anything written in pure Python without any extensions in compiled languages is pretty easy. In the moderately difficult category are projects like Matplotlib, which required special code to display plots in an HTML canvas. On the extremely difficult end of the spectrum, Scipy has been and remains a considerable challenge.
Roman Yurchak worked on making the large amount of legacy Fortran in Scipy compile to WebAssembly. Kirill Smelkov improved emscripten so shared objects can be reused by other shared objects, bringing Scipy to a more manageable size. (The work of these outside contributors was supported by Nexedi). If you’re struggling porting a package to Pyodide, please reach out to us on Github: there’s a good chance we may have run into your problem before.
Since we can’t predict which of these packages the user will ultimately need to do their work, they are downloaded to the browser individually, on demand. For example, when you import NumPy:
import numpy as npPyodide fetches the NumPy library (and all of its dependencies) and loads them into the browser at that time. Again, these files only need to be downloaded once, and are stored in the browser’s cache from then on.
Adding new packages to Pyodide is currently a semi-manual process that involves adding files to the Pyodide build. We’d prefer, long term, to take a distributed approach to this so anyone could contribute packages to the ecosystem without going through a single project. The best-in-class example of this is conda-forge. It would be great to extend their tools to support WebAssembly as a platform target, rather than redoing a large amount of effort.
Additionally, Pyodide will soon have support to load packages directly from PyPI (the main community package repository for Python), if that package is pure Python and distributes its package in the wheel format. This gives Pyodide access to around 59,000 packages, as of today.
Beyond Python
The relative early success of Pyodide has already inspired developers from other language communities, including Julia, R, OCaml, Lua, to make their language runtimes work well in the browser and integrate with web-first tools like Iodide. We’ve defined a set of levels to encourage implementors to create tighter integrations with the JavaScript runtime:
- Level 1: Just string output, so it’s useful as a basic console REPL (read-eval-print-loop).
- Level 2: Converts basic data types (numbers, strings, arrays and objects) to and from JavaScript.
- Level 3: Sharing of class instances (objects with methods) between the guest language and JavaScript. This allows for Web API access.
- Level 4: Sharing of data science related types (n-dimensional arrays and data frames) between the guest language and JavaScript.
We definitely want to encourage this brave new world, and are excited about the possibilities of having even more languages interoperating together. Let us know what you’re working on!
Conclusion
If you haven’t already tried Pyodide in action, go try it now! (50MB download)
It’s been really gratifying to see all of the cool things that have been created with Pyodide in the short time since its public launch. However, there’s still lots to do to turn this experimental proof-of-concept into a professional tool for everyday data science work. If you’re interested in helping us build that future, come find us on gitter, github and our mailing list.
Huge thanks to Brendan Colloran, Hamilton Ulmer and William Lachance, for their great work on Iodide and for reviewing this article, and Thomas Caswell for additional review.
About Michael Droettboom
Michael Droettboom is a Data Engineer at Mozilla, using data to improve the web while respecting the privacy of its users. He has built software tools to support many other disciplines, including the computational humanities, astronomy and medicine. He is a former lead developer of matplotlib and the original author of airspeed velocity.
8 comments