
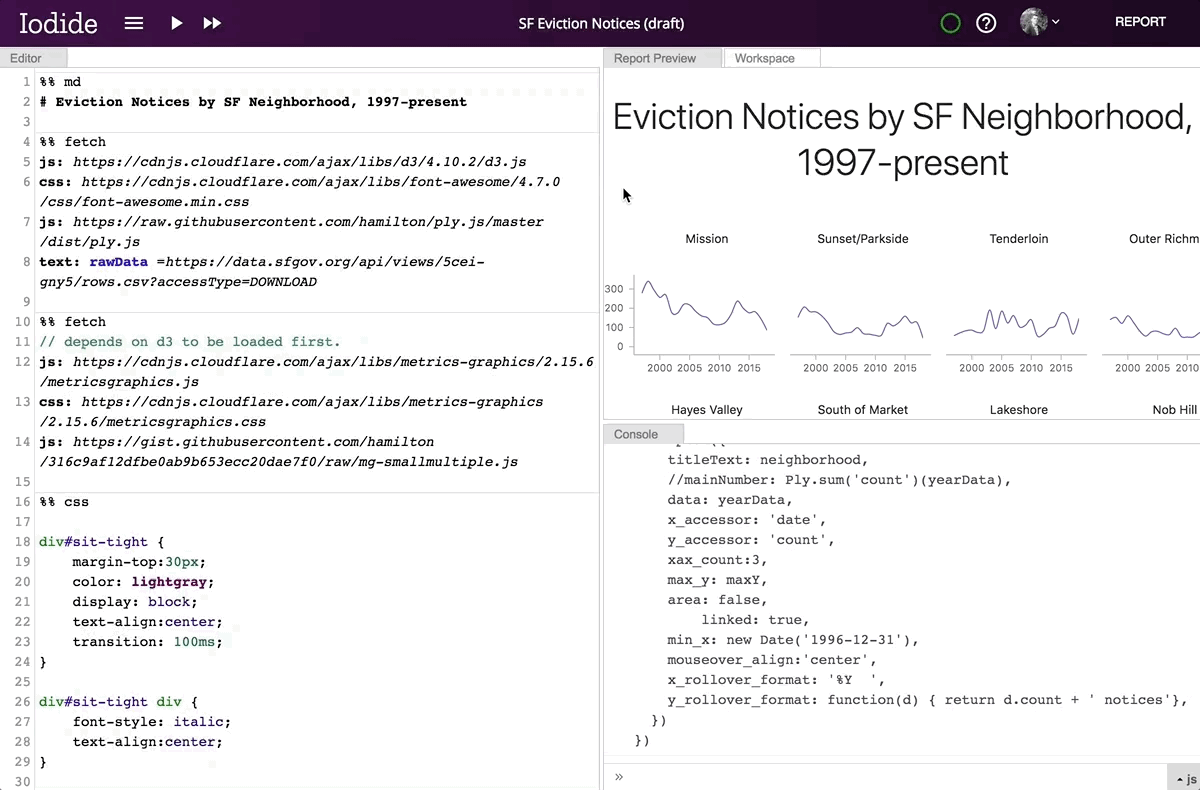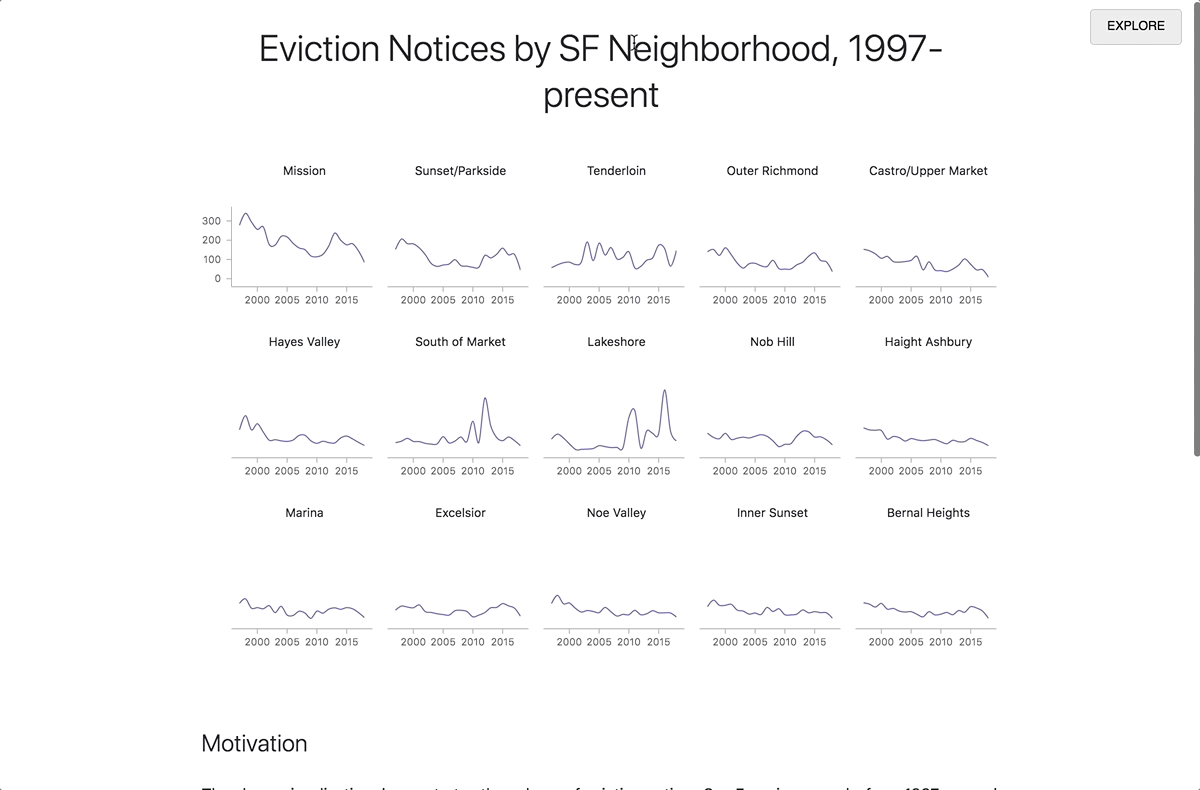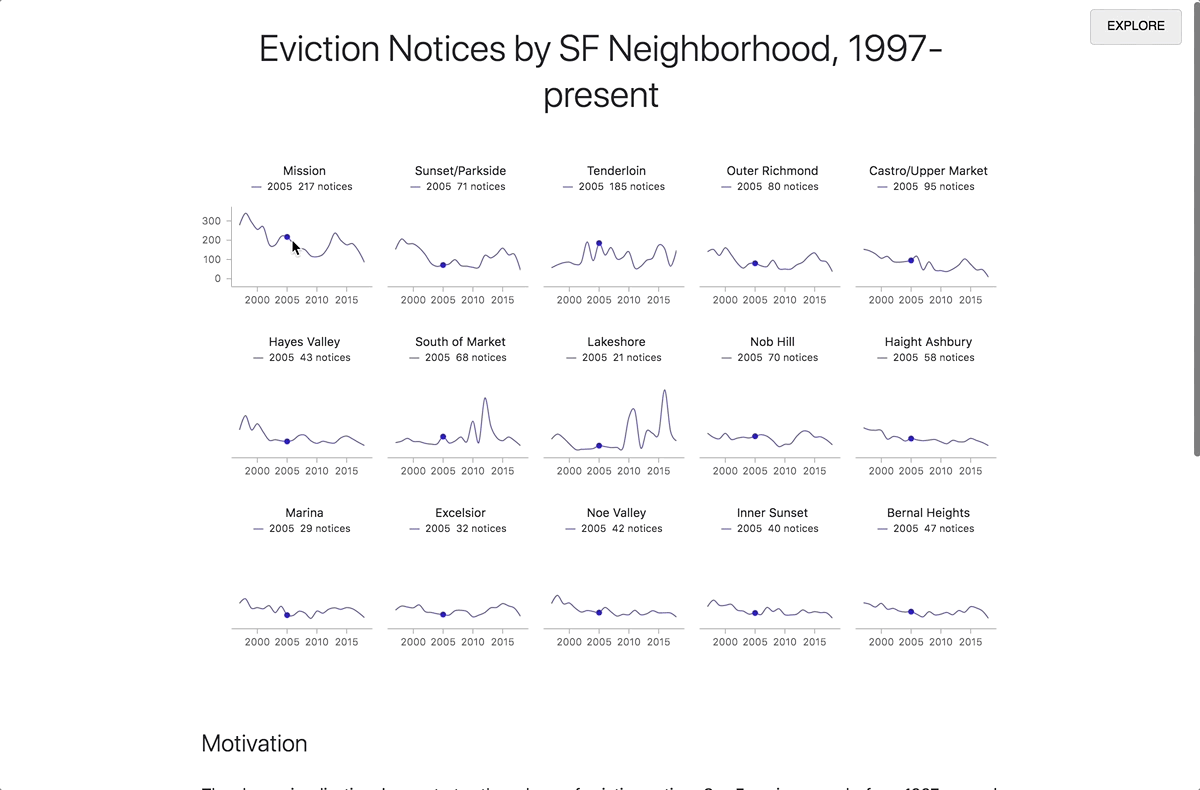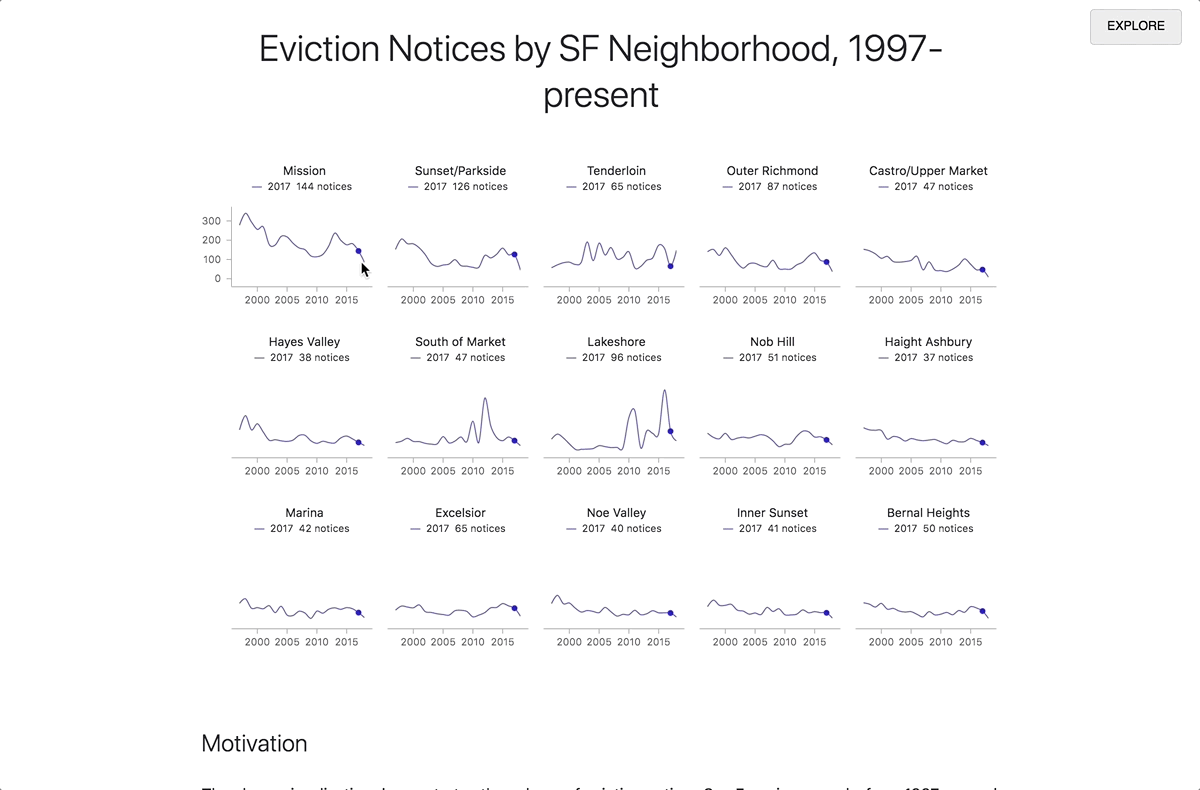
In the last 10 years, there has been an explosion of interest in “scientific computing” and “data science”: that is, the application of computation to answer questions and analyze data in the natural and social sciences. To address these needs, we’ve seen a renaissance in programming languages, tools, and techniques that help scientists and researchers explore and understand data and scientific concepts, and to communicate their findings. But to date, very few tools have focused on helping scientists gain unfiltered access to the full communication potential of modern web browsers. So today we’re excited to introduce Iodide, an experimental tool meant to help scientists write beautiful interactive documents using web technologies, all within an iterative workflow that feels similar to other scientific computing environments.

Iodide in action.
Beyond being just a programming environment for creating living documents in the browser, Iodide attempts to remove friction from communicative workflows by always bundling the editing tool with the clean readable document. This diverges from IDE-style environments that output presentational documents like .pdf files (which are then divorced from the original code) and cell-based notebooks which mix code and presentation elements. In Iodide, you can get both a document that looks however you want it to look, and easy access to the underlying code and editing environment.
Iodide is still very much in an alpha state, but following the internet aphorism “If you’re not embarrassed by the first version of your product, you’ve launched too late”, we’ve decided to do a very early soft launch in the hopes of getting feedback from a larger community. We have a demo that you can try out right now, but expect a lot of rough edges (and please don’t use this alpha release for critical work!). We’re hoping that, despite the rough edges, if you squint at this you’ll be able to see the value of the concept, and that the feedback you give us will help us figure out where to go next.
How we got to Iodide
Data science at Mozilla
At Mozilla, the vast majority of our data science work is focused on communication. Though we sometimes deploy models intended to directly improve a user’s experience, such as the recommendation engine that helps users discover browser extensions, most of the time our data scientists analyze our data in order to find and share insights that will inform the decisions of product managers, engineers and executives.
Data science work involves writing a lot of code, but unlike traditional software development, our objective is to answer questions, not to produce software. This typically results in some kind of report — a document, some plots, or perhaps an interactive data visualization. Like many data science organizations, at Mozilla we explore our data using fantastic tools like Jupyter and R-Studio. However, when it’s time to share our results, we cannot usually hand off a Jupyter notebook or an R script to a decision-maker, so we often end up doing things like copying key figures and summary statistics to a Google Doc.
We’ve found that making the round trip from exploring data in code to creating a digestible explanation and back again is not always easy. Research shows that many people share this experience. When one data scientist is reading through another’s final report and wants to look at the code behind it, there can be a lot of friction; sometimes tracking down the code is easy, sometimes not. If they want to attempt to experiment with and extend the code, things obviously get more difficult still. Another data scientist may have your code, but may not have an identical configuration on their machine, and setting that up takes time.
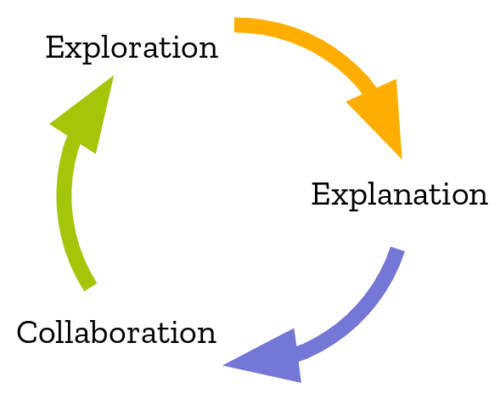
The virtuous circle of data science work.
Why is there so little web in science?
Against the background of these data science workflows at Mozilla, in late 2017 I undertook a project that called for interactive data visualization. Today you can create interactive visualizations using great libraries for Python, R, and Julia, but for what I wanted to accomplish, I needed to drop down to Javascript. This meant stepping away from my favorite data science environments. Modern web development tools are incredibly powerful, but extremely complicated. I really didn’t want to figure out how to get a fully-fledged Javascript build toolchain with hot module reloading up and running, but short of that I couldn’t find much aimed at creating clean, readable web documents within the live, iterative workflow familiar to me.
I started wondering why this tool didn’t exist — why there’s no Jupyter for building interactive web documents — and soon zoomed out to thinking about why almost no one uses Javascript for scientific computing. Three big reasons jumped out:
- Javascript itself has a mixed reputation among scientists for being slow and awkward;
- there aren’t many scientific computing libraries that run in the browser or that work with Javascript; and,
- as I’d discovered, there are very few scientific coding tools that enable fast iteration loop and also grant unfiltered access to the presentational capabilities in the browser.
These are very big challenges. But as I thought about it more, I began to think that working in a browser might have some real advantages for the kind of communicative data science that we do at Mozilla. The biggest advantage, of course, is that the browser has arguably the most advanced and well-supported set of presentation technologies on the planet, from the DOM to WebGL to Canvas to WebVR.
Thinking on the workflow friction mentioned above, another potential advantage occurred to me: in the browser, the final document need not be separate from the tool that created it. I wanted a tool designed to help scientists iterate on web documents (basically single-purpose web apps for explaining an idea)… and many tools we were using were themselves basically web apps. For the use case of writing these little web-app-documents, why not bundle the document with the tool used to write it?
By doing this, non-technical readers could see my nice looking document, but other data scientists could instantly get back to the original code. Moreover, since the compute kernel would be the browser’s JS engine, they’d be able to start extending and experimenting with the analysis code immediately. And they’d be able to do all this without connecting to remote computing resources or installing any software.
Towards Iodide
I started discussing the potential pros and cons of scientific computing in the browser with my colleagues, and in the course of our conversations, we noticed some other interesting trends.
Inside Mozilla we were seeing a lot of interesting demos showing off WebAssembly, a new way for browsers to run code written in languages other than Javascript. WebAssembly allows programs to be run at incredible speed, in some cases close to native binaries. We were seeing examples of computationally-expensive processes like entire 3D game engines running within the browser without difficulty. Going forward, it would be possible to compile best-in-class C and C++ numerical computing libraries to WebAssembly and wrap them in ergonomic JS APIs, just as the SciPy project does for Python. Indeed, projects had started to do this already.
WebAssembly makes it possible to run code at near-native speed in the browser.
We also noticed the Javascript community’s willingness to introduce new syntax when doing so helps people to solve their problem more effectively. Perhaps it would be possible to emulate some of key syntactic elements that make numerical programming more comprehensible and fluid in MATLAB, Julia, and Python — matrix multiplication, multidimensional slicing, broadcast array operations, and so on. Again, we found other people thinking along similar lines.
With these threads converging, we began to wonder if the web platform might be on the cusp of becoming a productive home for scientific computing. At the very least, it looked like it might evolve to serve some of the communicative workflows that we encounter at Mozilla (and that so many others encounter in industry and academia). With the core of Javascript improving all the time and the possibility of adding syntax extensions for numerical programming, perhaps JS itself could be made more appealing to scientists. WebAssembly seemed to offer a path to great science libraries. The third leg of the stool would be an environment for creating data science documents for the web. This last element is where we decided to focus our initial experimentation, which brought us to Iodide.
The anatomy of Iodide
Iodide is a tool designed to give scientists a familiar workflow for creating great-looking interactive documents using the full power of the web platform. To accomplish that, we give you a “report” — basically a web page that you can fill in with your content — and some tools for iteratively exploring data and modifying your report to create something you’re ready to share. Once you’re ready, you can send a link directly to your finalized report. If your colleagues and collaborators want to review your code and learn from it, they can drop back to an exploration mode in one click. If they want to experiment with the code and use it as the basis of their own work, with one more click they can fork it and start working on their own version.
Read on to learn a bit more about some of the ideas we’re experimenting with in an attempt to make this workflow feel fluid.
The Explore and Report Views
Iodide aims to tighten the loop between exploration, explanation, and collaboration. Central to that is the ability to move back and forth between a nice looking write-up and a useful environment for iterative computational exploration.
When you first create a new Iodide notebook, you start off in the “explore view.” This provides a set of panes including an editor for writing code, a console for viewing the output from code you evaluate, a workspace viewer for examining the variables you’ve created during your session, and a “report preview” pane in which you can see a preview of your report.
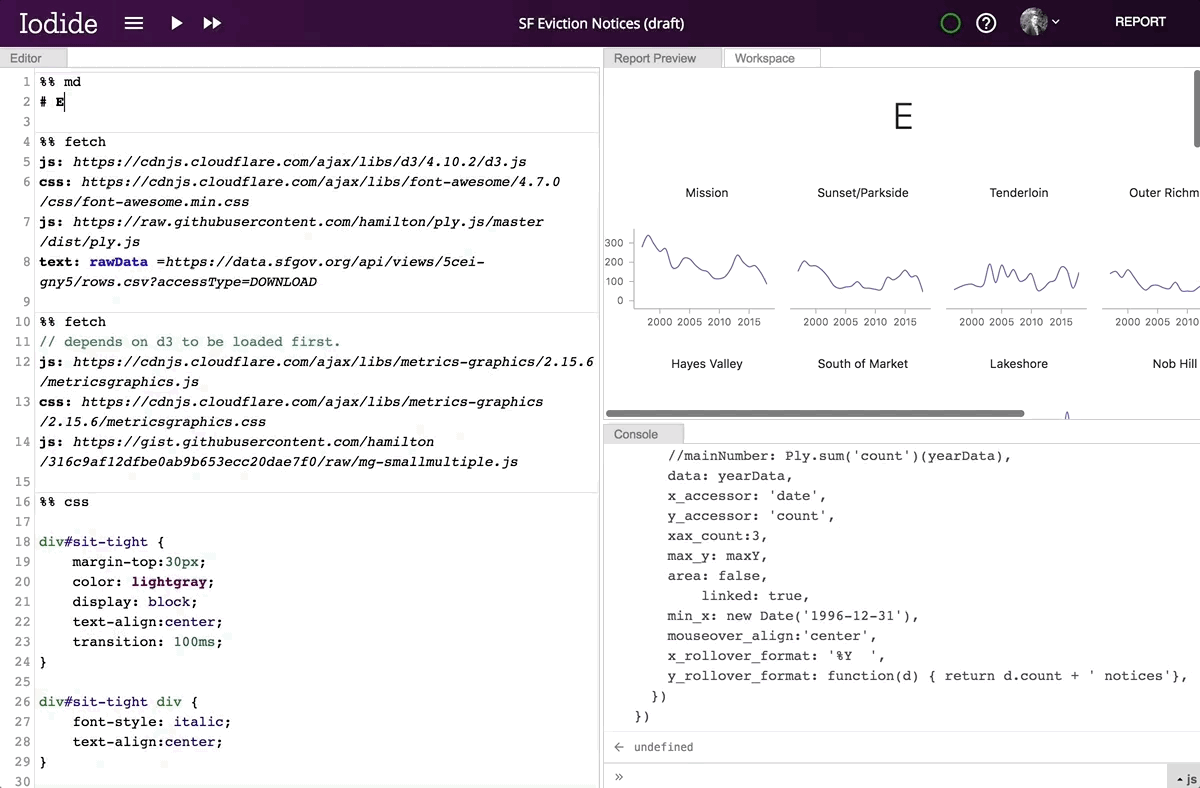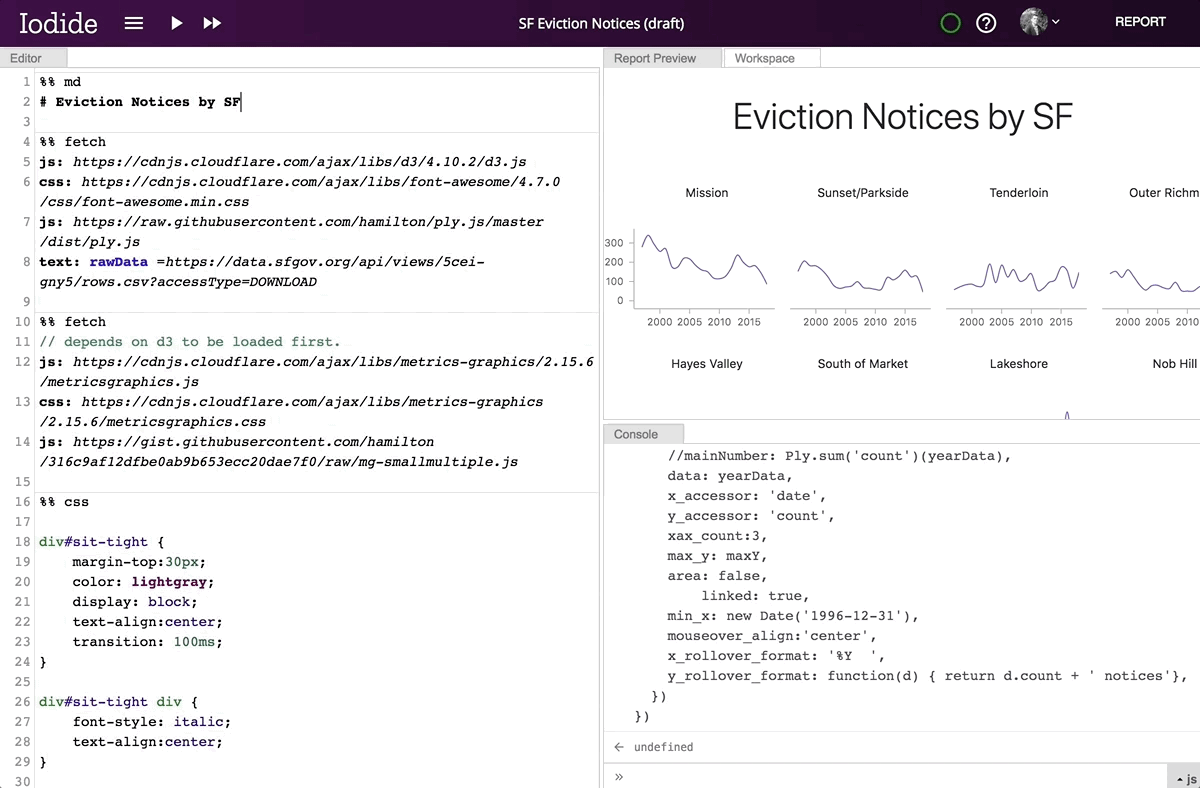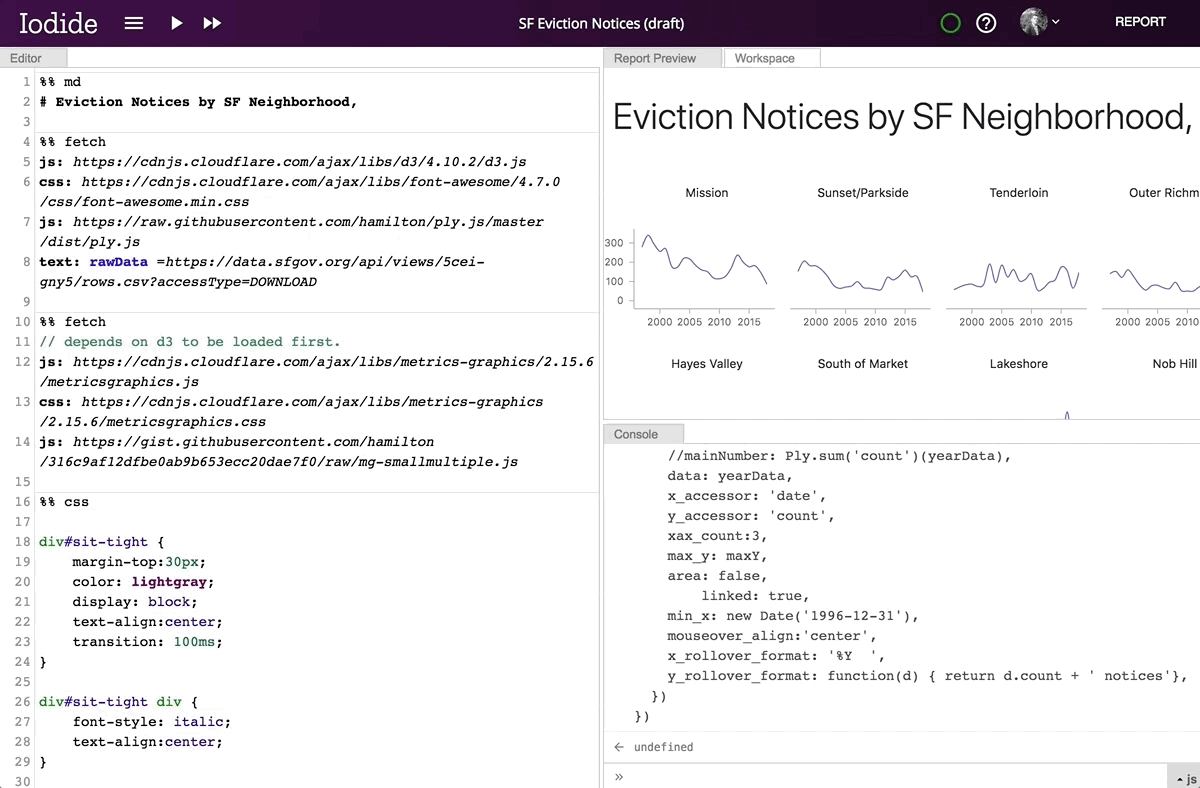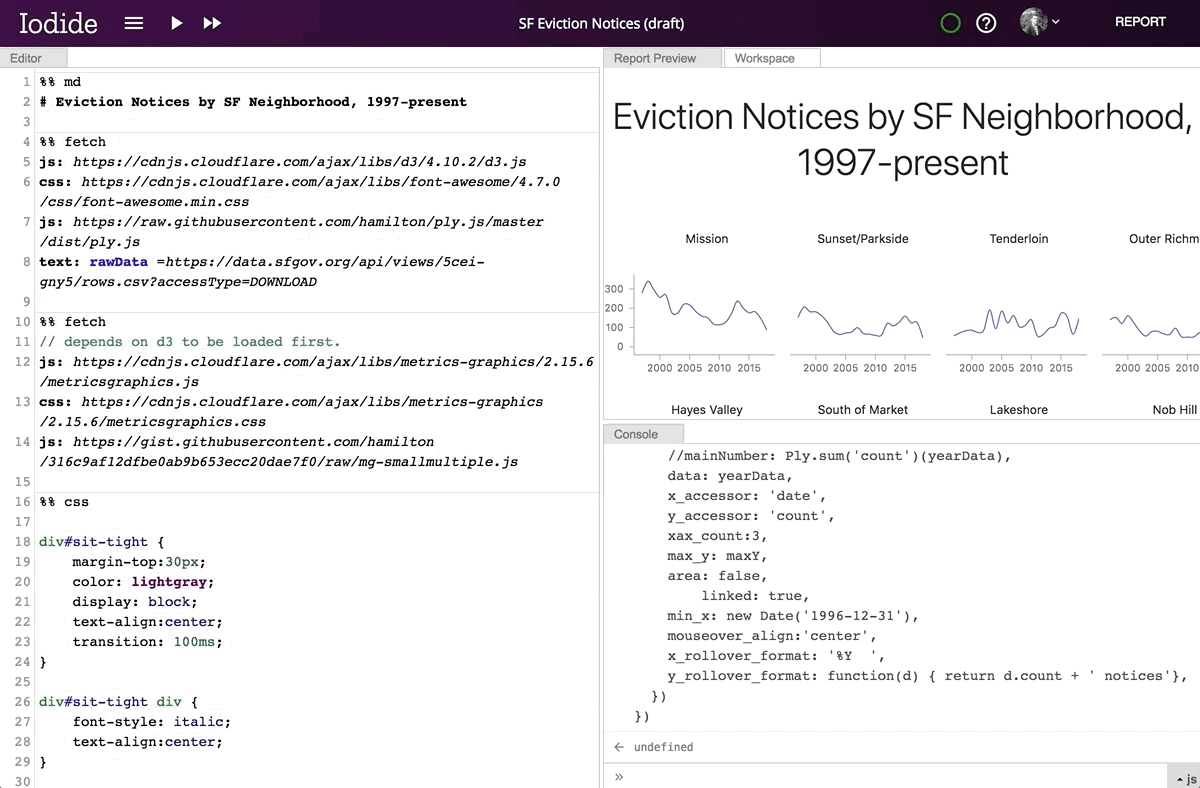
Editing a Markdown code chunk in Iodide’s explore view.
By clicking the “REPORT” button in the top right corner, the contents of your report preview will expand to fill the entire window, allowing you to put the story you want to tell front and center. Readers who don’t know how to code or who aren’t interested in the technical details are able to focus on what you’re trying to convey without having to wade through the code. When a reader visits the link to the report view, your code will runs automatically. if they want to review your code, simply clicking the “EXPLORE” button in the top right will bring them back into the explore view. From there, they can make a copy of the notebook for their own explorations.
Moving from explore to report view.
Whenever you share a link to an Iodide notebook, your collaborator can always access to both of these views. The clean, readable document is never separated from the underlying runnable code and the live editing environment.
Live, interactive documents with the power of the Web Platform
Iodide documents live in the browser, which means the computation engine is always available. Whenever you share your work, you share a live interactive report with running code. Moreover, since the computation happens in the browser alongside the presentation, there is no need to call a language backend in another process. This means that interactive documents update in real-time, opening up the possibility of seamless 3D visualizations, even with the low-latency and high frame-rate required for VR.
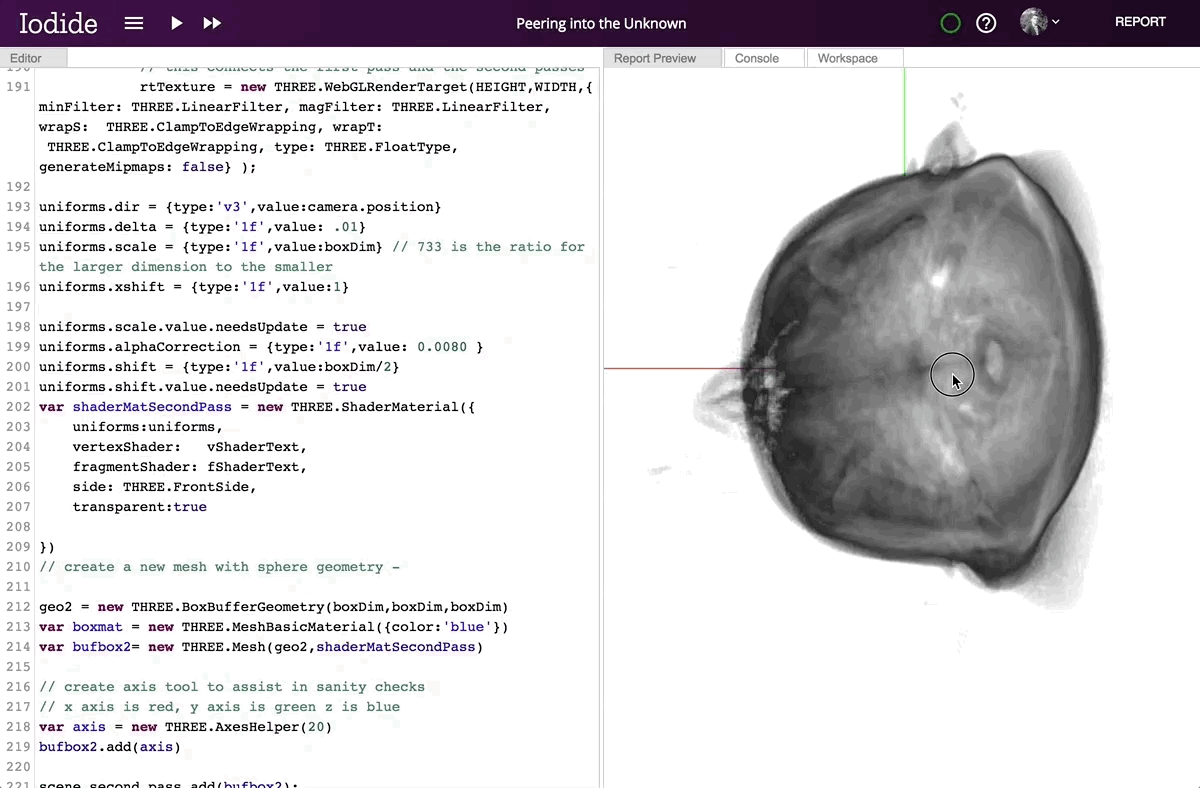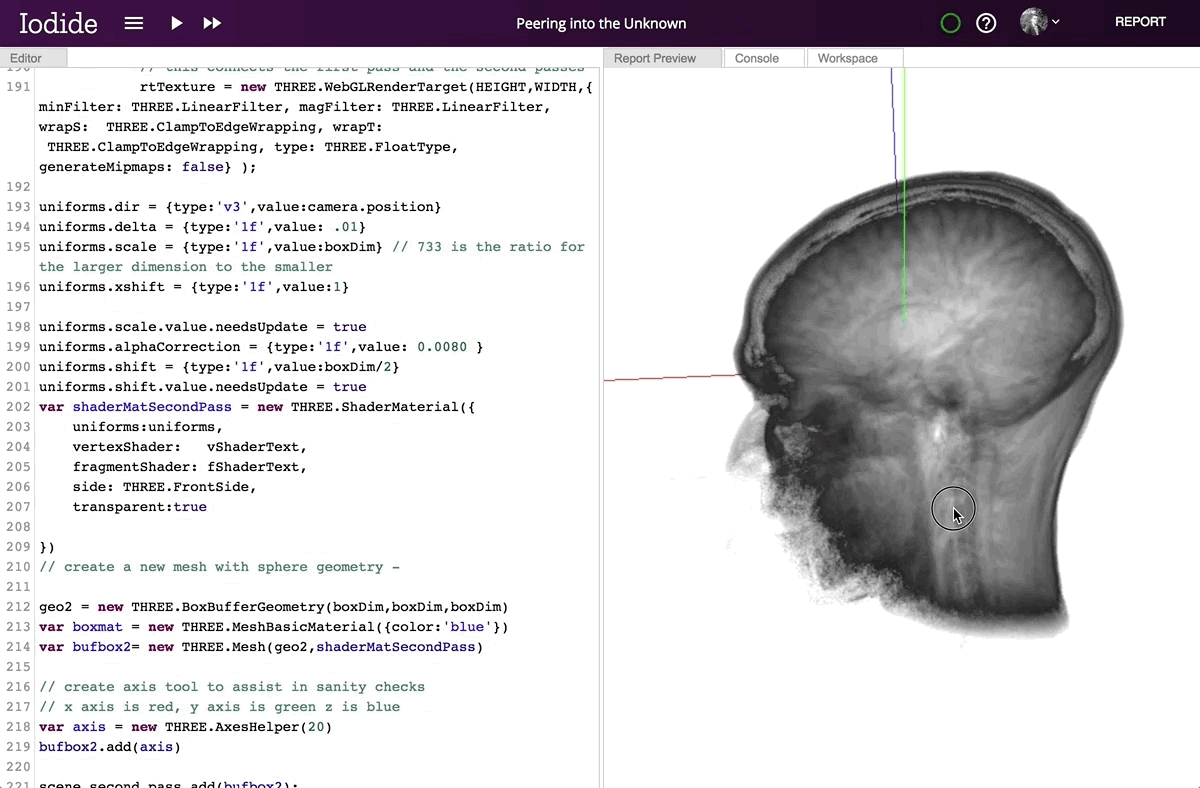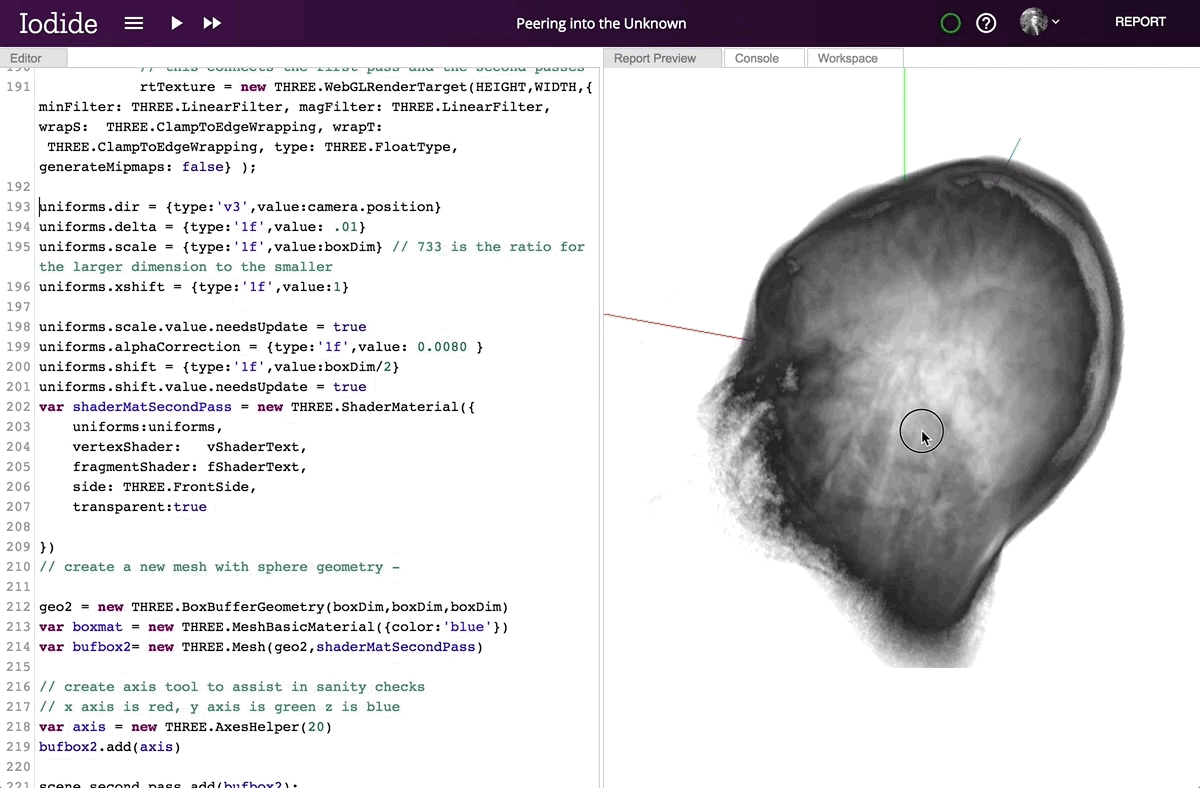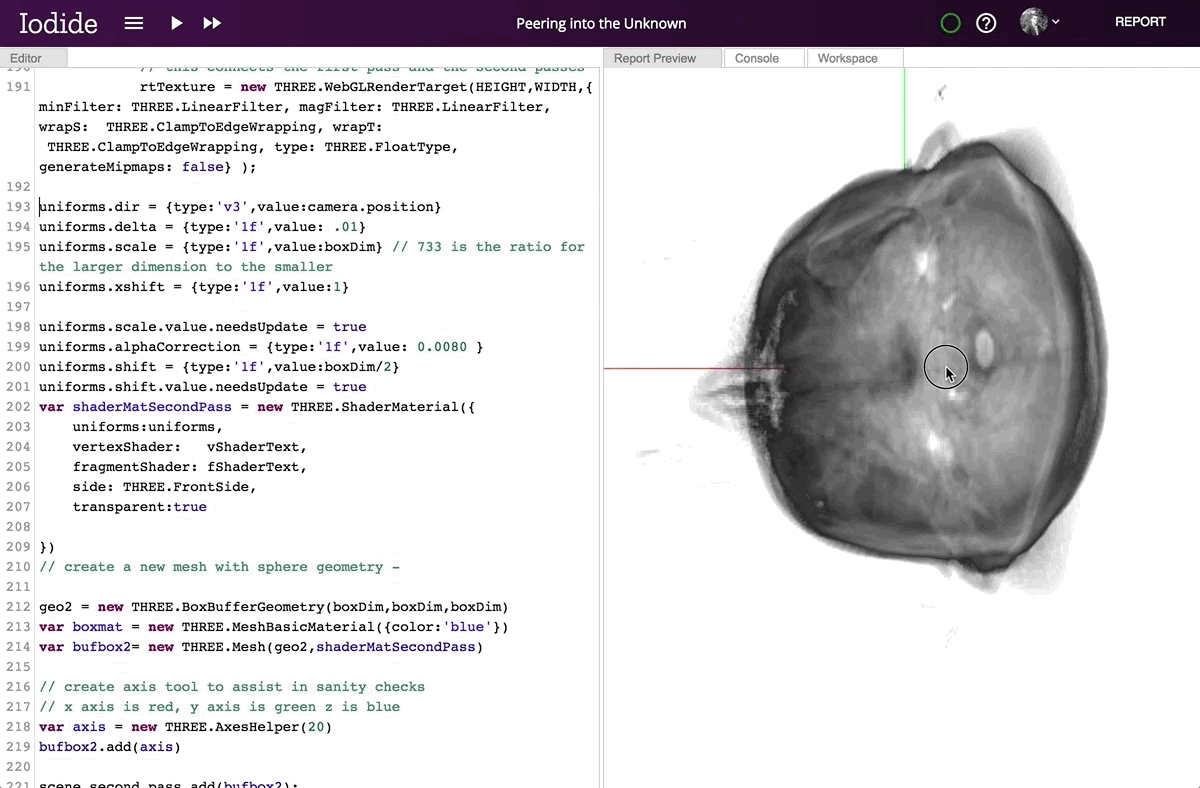
Contributor Devin Bayly explores MRI data of his brain
Sharing, collaboration, and reproducibility
Building Iodide in the web simplifies a number of the elements of workflow friction that we’ve encountered in other tools. Sharing is simplified because the write-up and the code are available at the same URL rather than, say, pasting a link to a script in the footnotes of a Google Doc. Collaboration is simplified because the compute kernel is the browser and libraries can be loaded via an HTTP request like any webpage loads script — no additional languages, libraries, or tools need to be installed. And because browsers provide a compatibility layer, you don’t have to worry about notebook behavior being reproducible across computers and OSes.
To support collaborative workflows, we’ve built a fairly simple server for saving and sharing notebooks. There is a public instance at iodide.io where you can experiment with Iodide and share your work publicly. It’s also possible to set up your own instance behind a firewall (and indeed this is what we’re already doing at Mozilla for some internal work). But importantly, the notebooks themselves are not deeply tied to a single instance of the Iodide server. Should the need arise, it should be easy to migrate your work to another server or export your notebook as a bundle for sharing on other services like Netlify or Github Pages (more on exporting bundles below under “What’s next?”). Keeping the computation in the client allows us to focus on building a really great environment for sharing and collaboration, without needing to build out computational resources in the cloud.
Pyodide: The Python science stack in the browser
When we started thinking about making the web better for scientists, we focused on ways that we could make working with Javascript better, like compiling existing scientific libraries to WebAssembly and wrapping them in easy to use JS APIs. When we proposed this to Mozilla’s WebAssembly wizards, they offered a more ambitious idea: if many scientists prefer Python, meet them where they are by compiling the Python science stack to run in WebAssembly.
We thought this sounded daunting — that it would be an enormous project and that it would never deliver satisfactory performance… but two weeks later Mike Droettboom had a working implementation of Python running inside an Iodide notebook. Over the next couple months, we added Numpy, Pandas, and Matplotlib, which are by far the most used modules in the Python science ecosystem. With help from contributors Kirill Smelkov and Roman Yurchak at Nexedi, we landed support for Scipy and scikit-learn. Since then, we’ve continued adding other libraries bit by bit.
Running the Python interpreter inside a Javascript virtual machine adds a performance penalty, but that penalty turns out to be surprisingly small — in our benchmarks, around 1x-12x slower than native on Firefox and 1x-16x slower on Chrome. Experience shows that this is very usable for interactive exploration.
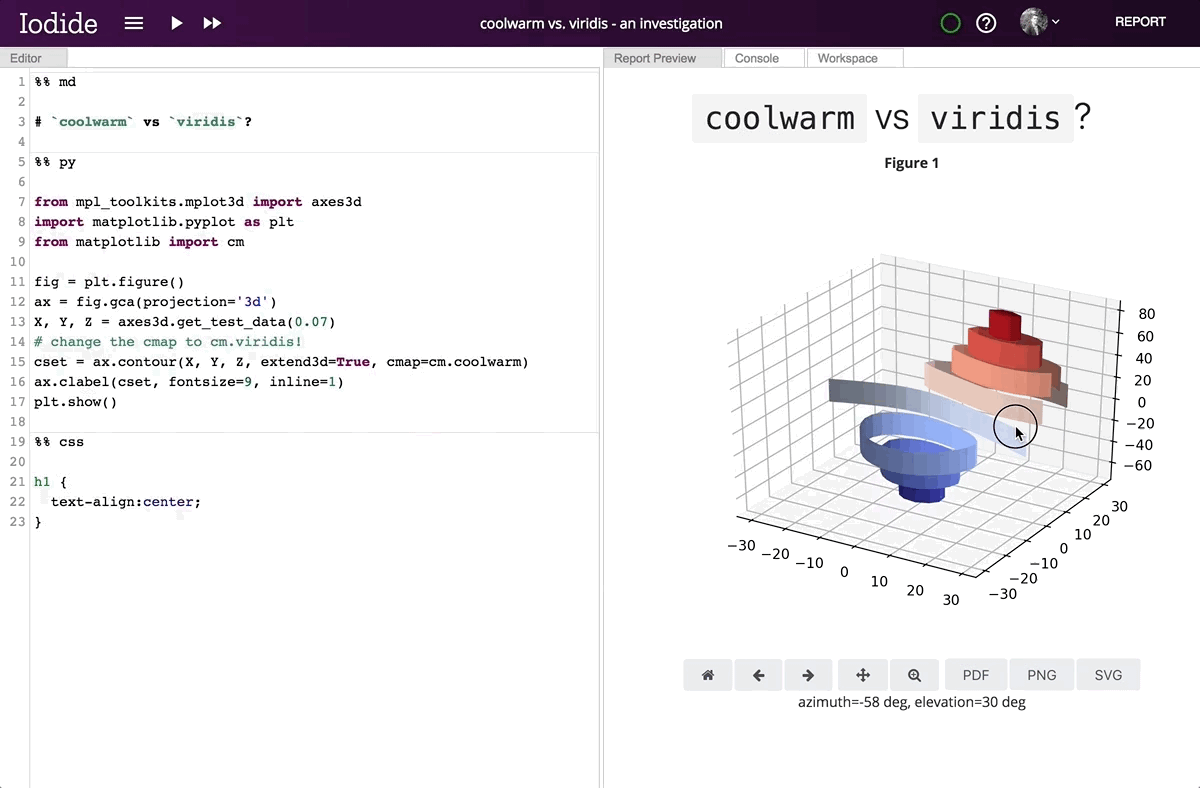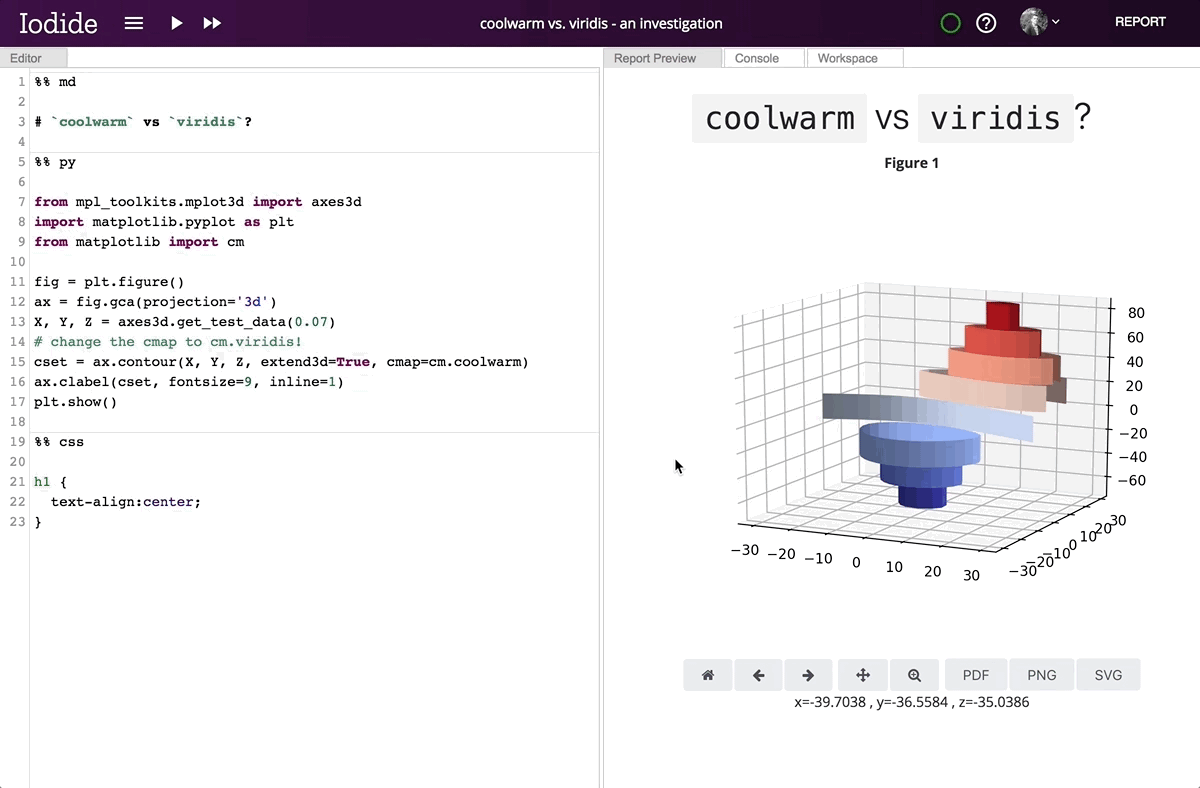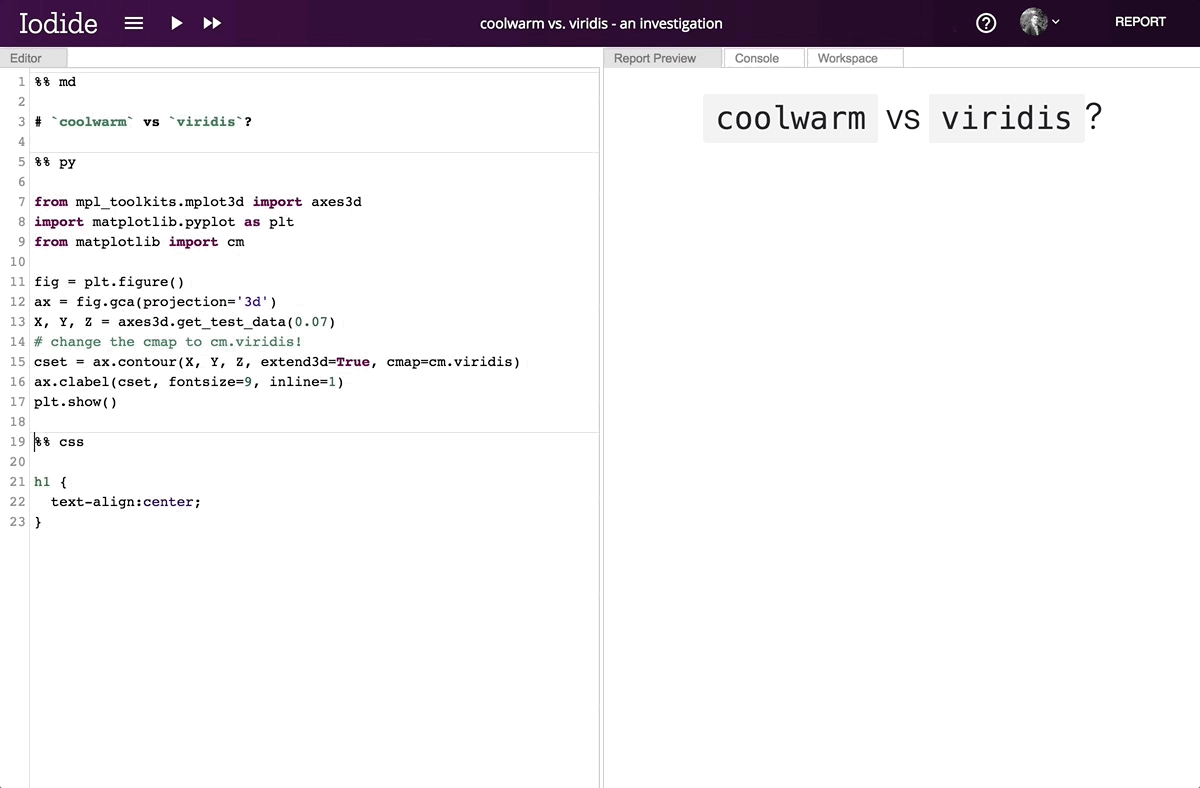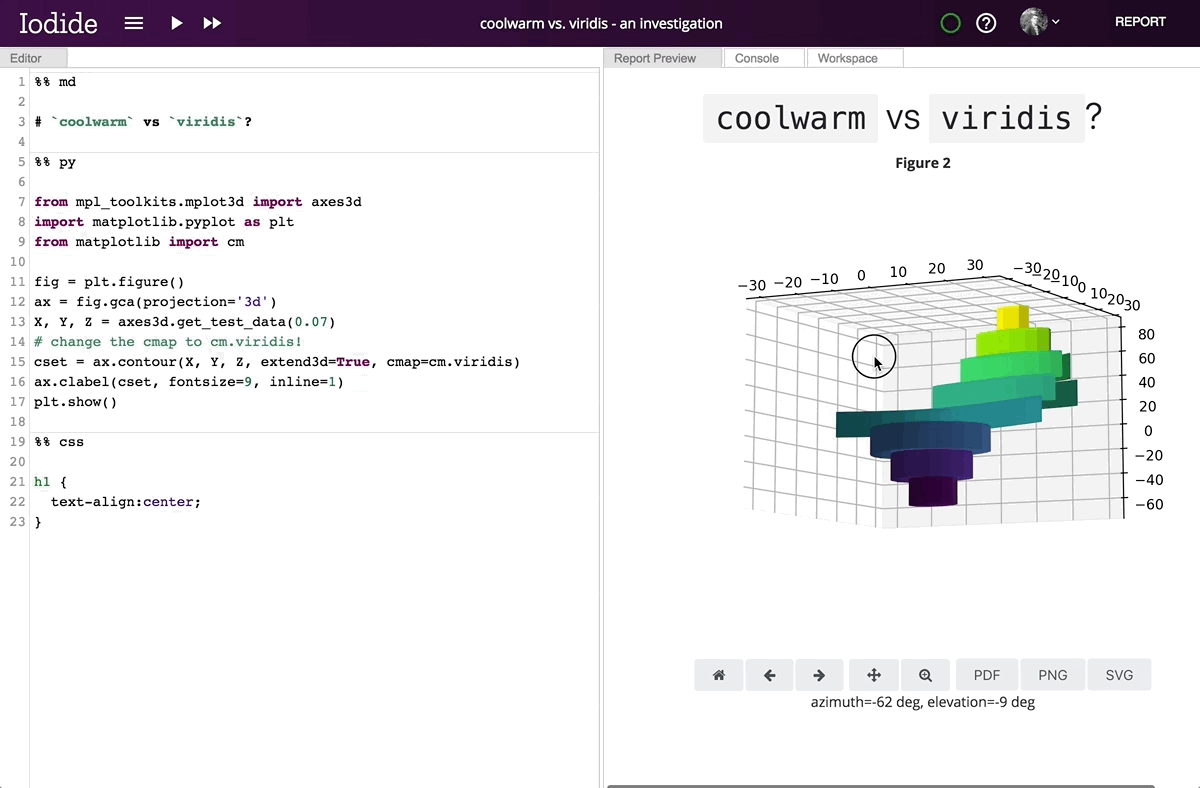
Running Matplotlib in the browser enables its interactive features, which are unavailable in static environments
Bringing Python into the browser creates some magical workflows. For example, you can import and clean your data in Python, and then access the resulting Python objects from Javascript (in most cases, the conversion happens automatically) so that you can display them using JS libraries like d3. Even more magically, you can access browser APIs from Python code, allowing you to do things like manipulate the DOM without touching Javascript.
Of course, there’s a lot more to say about Pyodide, and it deserves an article of its own — we’ll go into more detail in a follow up post next month.
JSMD (JavaScript MarkDown)
Just as in Jupyter and R’s R-Markdown mode, in Iodide you can interleave code and write-up as you wish, breaking your code into “code chunks” that you can modify and run as a separate units. Our implementation of this idea parallels R Markdown and MATLAB’s “cell mode”: rather than using an explicitly cell-based interface, the content of an Iodide notebook is just a text document that uses a special syntax to delimit specific types of cells. We call this text format “JSMD”.
Following MATLAB, code chunks are defined by lines starting with %% followed by a string indicating the language of the chunk below. We currently support chunks containing Javascript, CSS, Markdown (and HTML), Python, a special “fetch” chunk that simplifies loading resources, and a plugin chunk that allows you to extend Iodide’s functionality by adding new cell types.
We’ve found this format to be quite convenient. It makes it easy to use text-oriented tools like diff viewers and your own favorite text editor, and you can perform standard text operations like cut/copy/paste without having to learn shortcuts for cell management. For more details you can read about JSMD in our docs.
What’s next?
It’s worth repeating that we’re still in alpha, so we’ll be continuing to improve overall polish and squash bugs. But in addition to that, we have a number of features in mind for our next round of experimentation. If any of these ideas jump out as particularly useful, let us know! Even better, let us know if you’d like to help us build them!
Enhanced collaborative features
As mentioned above, so far we’ve built a very simple backend that allows you to save your work online, look at work done by other people, and quickly fork and extend existing notebooks made by other users, but these are just the initial steps in a useful collaborative workflow.
The next three big collaboration features we’re looking at adding are:
- Google Docs-style comment threads
- The ability to suggest changes to another user’s notebook via a fork/merge workflow similar to Github pull requests
- Simultaneous notebook editing like Google Docs.
At this point, we’re prioritizing them in roughly that order, but if you would tackle them in a different order or if you have other suggestions, let us know!
More languages!
We’ve spoken to folks from the R and Julia communities about compiling those languages to WebAssembly, which would allow their use in Iodide and other browser-based projects. Our initial investigation indicates that this should be doable, but that implementing these languages might be a bit more challenging than Python. As with Python, some cool workflows open up if you can, for example, fit statistical models in R or solve differential equations in Julia, and then display your results using browser APIs. If bringing these languages to the web interests you, please reach out — in particular, we’d love help from FORTRAN and LLVM experts.
Export notebook archive
Early versions of Iodide were self-contained runnable HTML files, which included both the JSMD code used in the analysis, and the JS code used to run Iodide itself, but we’ve moved away from this architecture. Later experiments have convinced us that the collaboration benefits of having an Iodide server outweigh the advantages of managing files on your local system. Nonetheless, these experiments showed us that it’s possible to take a runnable snapshot of an Iodide notebook by inling the Iodide code along with any data and libraries used by a notebook into one big HTML file. This might end up being a bigger file than you’d want to serve to regular users, but it could prove useful as a perfectly reproducible and archivable snapshot of an analysis.
Iodide to text editor browser extension
While many scientists are quite used to working in browser-based programming environments, we know that some people will never edit code in anything other than their favorite text editor. We really want Iodide to meet people where they are already, including those who prefer to type their code in another editor but want access to the interactive and iterative features that Iodide provides. To serve that need, we’ve started thinking about creating a lightweight browser extension and some simple APIs to let Iodide talk to client-side editors.
Feedback and collaboration welcome!
We’re not trying to solve all the problems of data science and scientific computing, and we know that Iodide will not be everyone’s cup of tea. If you need to process terabytes of data on GPU clusters, Iodide probably doesn’t have much to offer you. If you are publishing journal articles and you just need to write up a LaTeX doc, then there are better tools for your needs. If the whole trend of bringing things into the browser makes you cringe a little, no problem — there are a host of really amazing tools that you can use to do science, and we’re thankful for that! We don’t want to change the way anyone works, and for many scientists web-focused communication is beside the point. Rad! Live your best life!
But for those scientists who do produce content for the web, and for those who might like to do so if you had tools designed to support the way you work: we’d really love to hear from you!
Please visit iodide.io, try it out, and give us feedback (but again: keep in mind that this project is in alpha phase — please don’t use it for any critical work, and please be aware that while we’re in alpha everything is subject to change). You can take our quick survey, and Github issues and bug reports are very welcome. Feature requests and thoughts on the overall direction can be shared via our Google group or Gitter.
If you’d like to get involved in helping us build Iodide, we’re open source on Github. Iodide touches a wide variety of software disciplines, from modern frontend development to scientific computing to compilation and transpilation, so there are a lot of interesting things to do! Please reach out if any of this interests you!
Huge thanks to Hamilton Ulmer, William Lachance, and Mike Droettboom for their great work on Iodide and for reviewing this article.
18 comments