
The Firefox Quantum release is getting close. It brings many performance improvements, including the super fast CSS engine that we brought over from Servo.
But there’s another big piece of Servo technology that’s not in Firefox Quantum quite yet, though it’s coming soon. That’s WebRender, which is being added to Firefox as part of the Quantum Render project.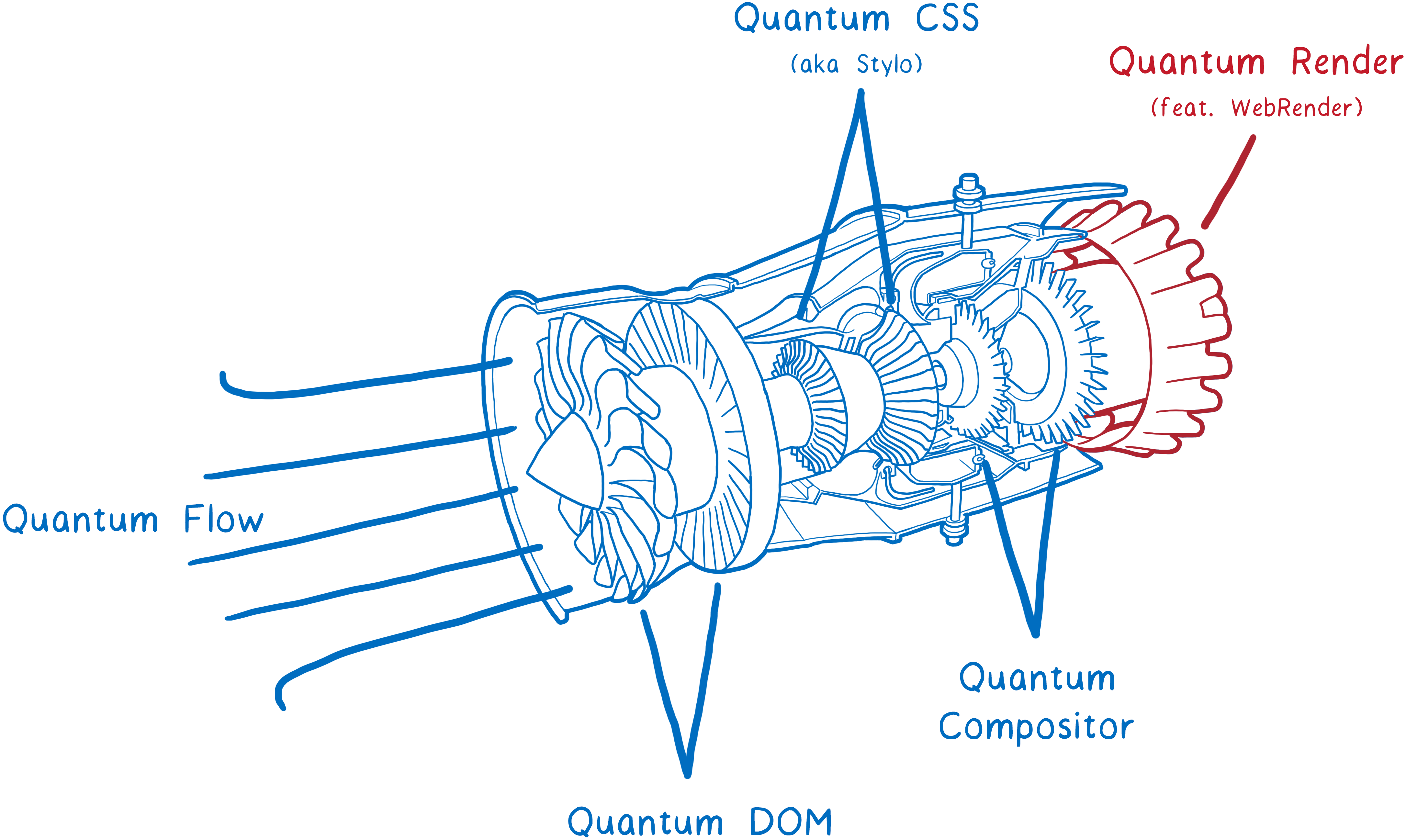
WebRender is known for being extremely fast. But WebRender isn’t really about making rendering faster. It’s about making it smoother.
With WebRender, we want apps to run at a silky smooth 60 frames per second (FPS) or better no matter how big the display is or how much of the page is changing from frame to frame. And it works. Pages that chug along at 15 FPS in Chrome or today’s Firefox run at 60 FPS with WebRender.
So how does WebRender do that? It fundamentally changes the way the rendering engine works to make it more like a 3D game engine.
Let’s take a look at what this means. But first…
What does a renderer do?
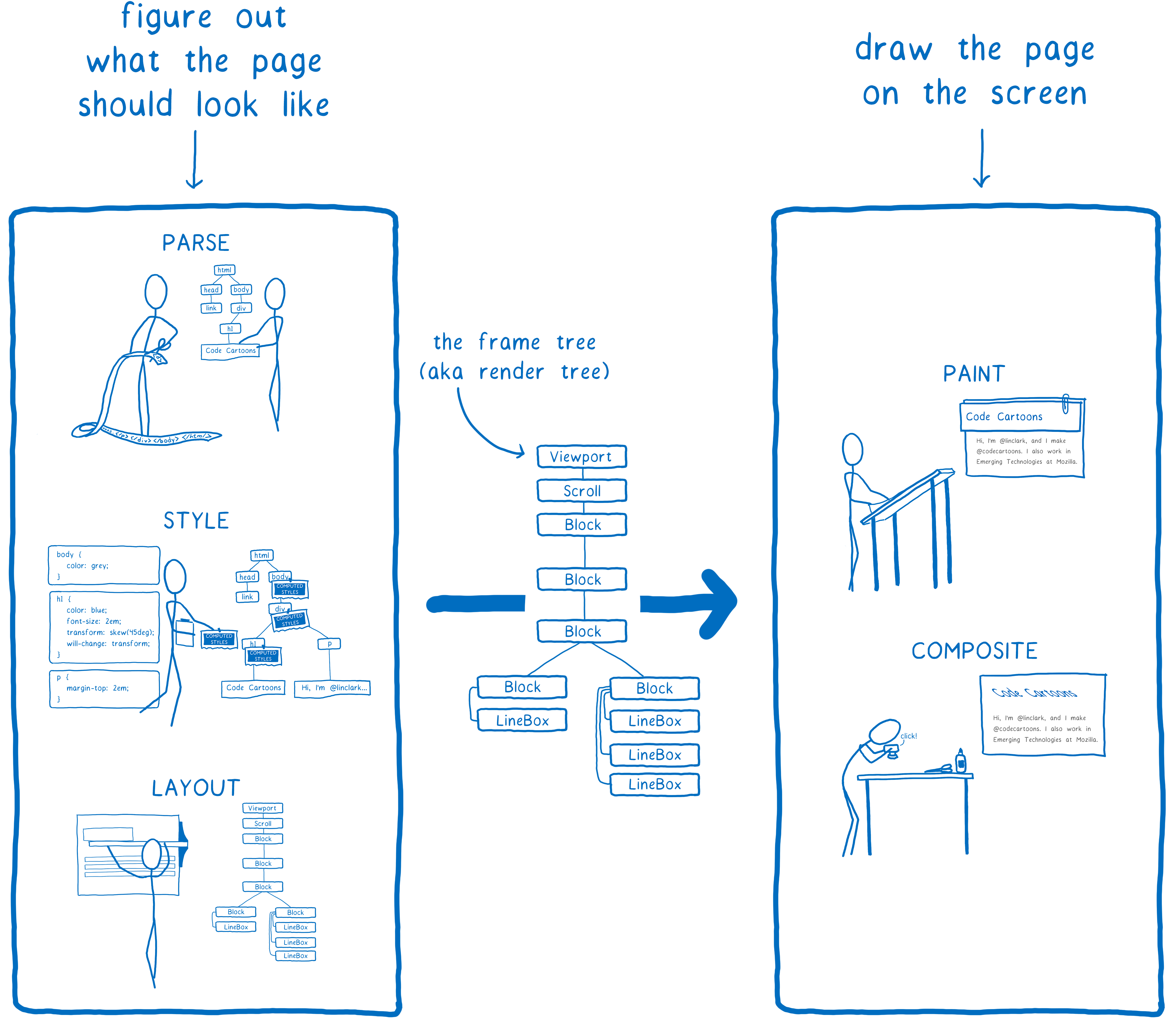
In the article on Stylo, I talked about how the browser goes from HTML and CSS to pixels on the screen, and how most browsers do this in five steps.
We can split these five steps into two halves. The first half basically builds up a plan. To make this plan, it combines the HTML and CSS with information like the viewport size to figure out exactly what each element should look like—its width, height, color, etc. The end result is something called a frame tree or a render tree.
The second half—painting and compositing—is what a renderer does. It takes that plan and turns it into pixels to display on the screen.
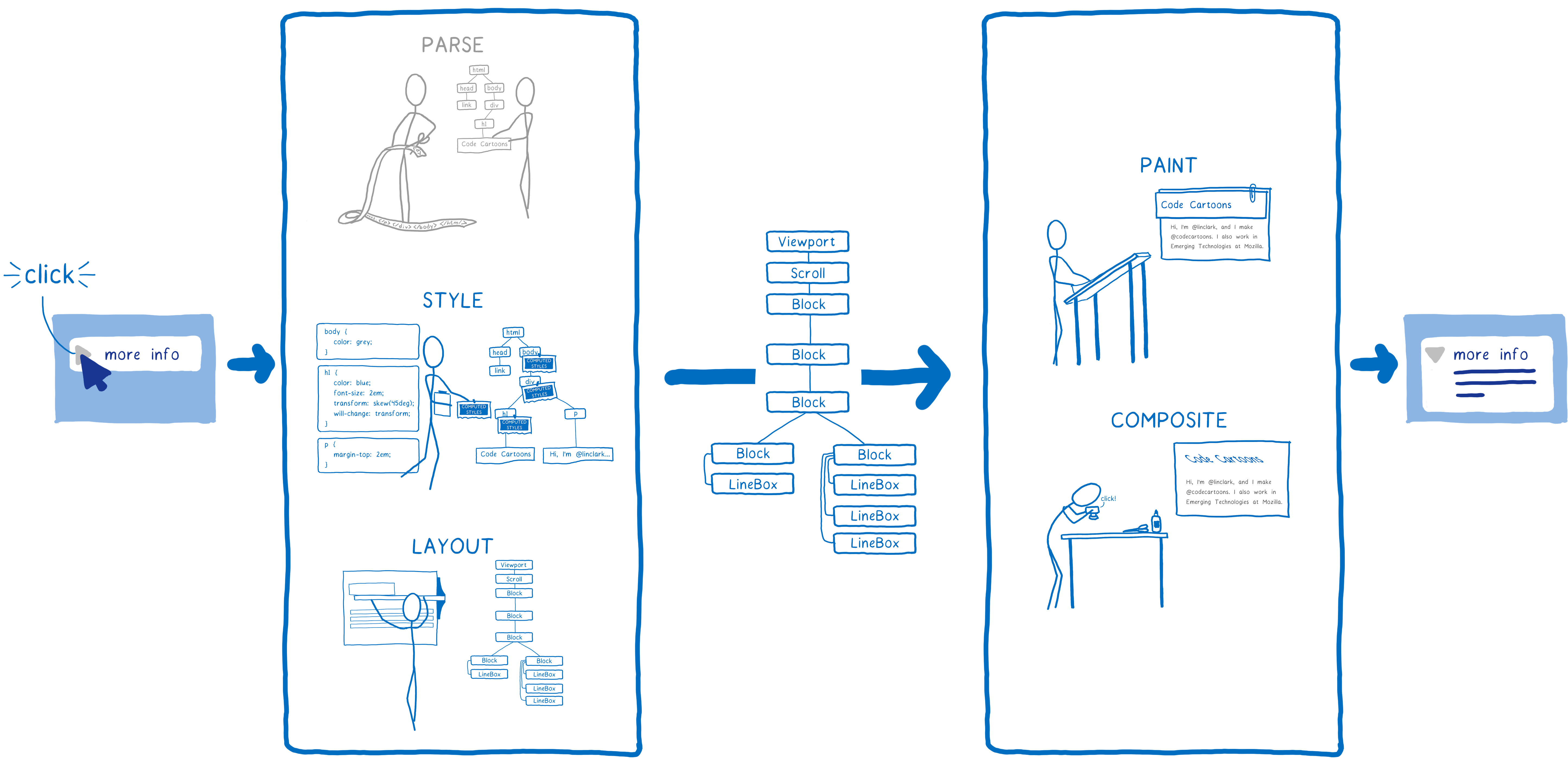
But the browser doesn’t just have to do this once for a web page. It has to do it over and over again for the same web page. Any time something changes on this page—for example, a div is toggled open—the browser has to go through a lot of these steps.
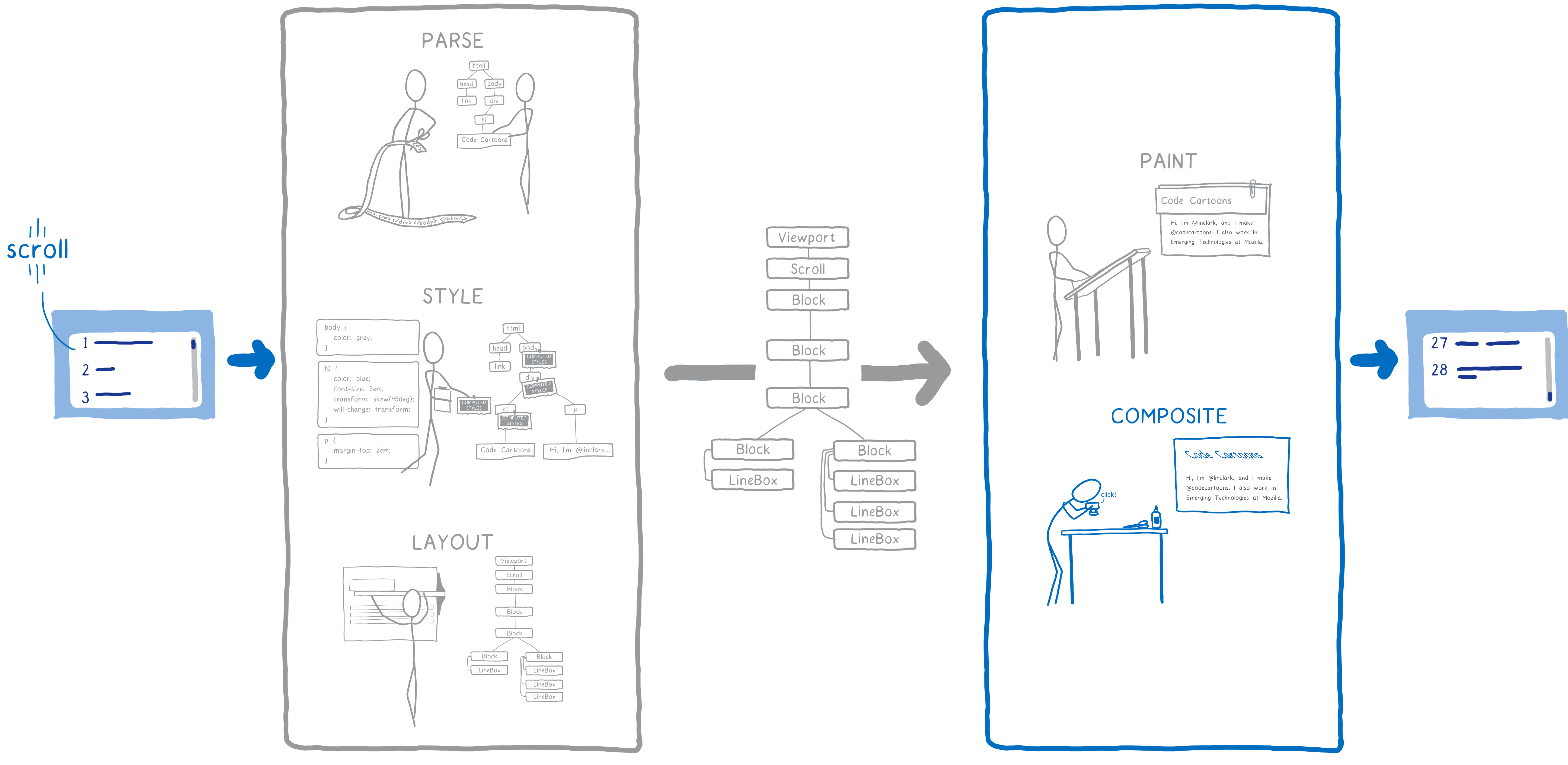
Even in cases where nothing’s really changing on the page—for example where you’re scrolling or where you are highlighting some text on the page—the browser still has to go through at least some of the second part again to draw new pixels on the screen.
If you want things like scrolling or animation to look smooth, they need to be going at 60 frames per second.
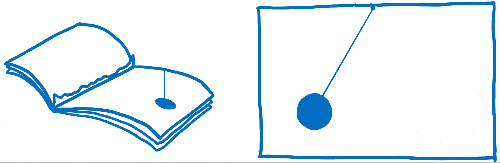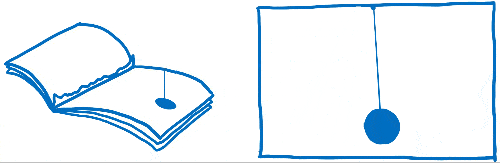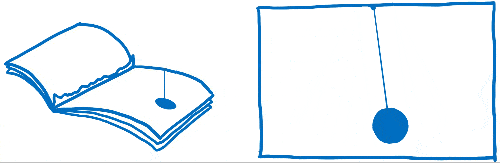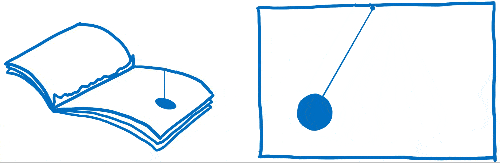
You may have heard this phrase—frames per second (FPS)—before, without being sure what it meant. I think of this like a flip book. It’s like a book of drawings that are static, but you can use your thumb to flip through so that it looks like the pages are animated.
In order for the animation in this flip book to look smooth, you need to have 60 pages for every second in the animation.
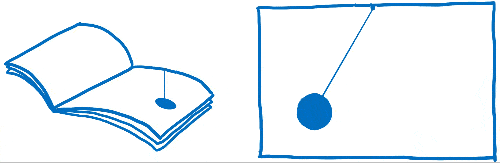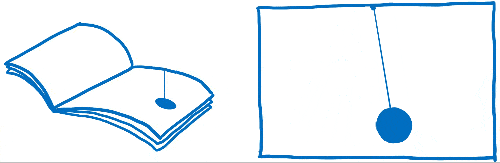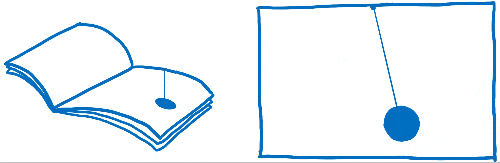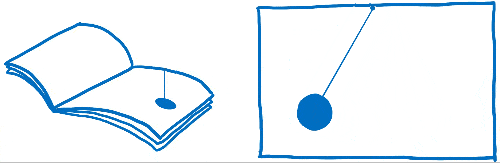
The pages in this flip book are made out of graph paper. There are lots and lots of little squares, and each of the squares can only contain one color.
The job of the renderer is to fill in the boxes in this graph paper. Once all of the boxes in the graph paper are filled in, it is finished rendering the frame.
Now, of course there is not actual graph paper inside of your computer. Instead, there’s a section of memory in the computer called a frame buffer. Each memory address in the frame buffer is like a box in the graph paper… it corresponds to a pixel on the screen. The browser will fill in each slot with the numbers that represent the color in RGBA (red, green, blue, and alpha) values.
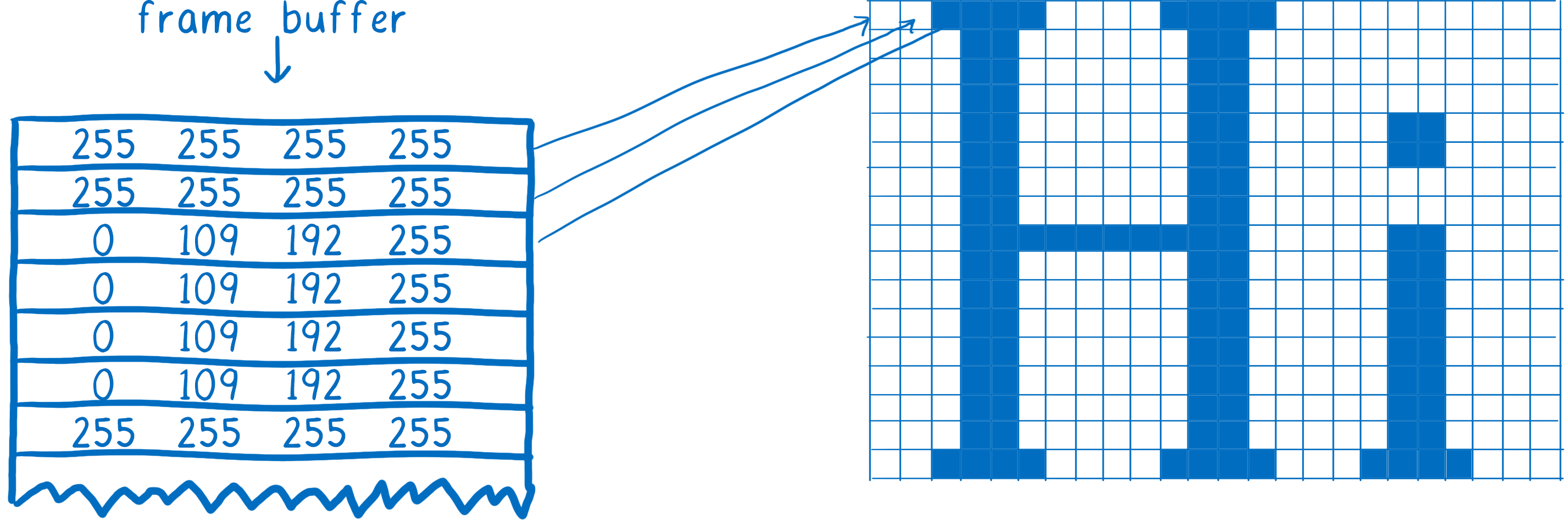
When the display needs to refresh itself, it will look at this section of memory.
Most computer displays will refresh 60 times per second. This is why browsers try to render pages at 60 frames per second. That means the browser has 16.67 milliseconds to do all of the setup —CSS styling, layout, painting—and fill in all of the slots in the frame buffer with pixel colors. This time frame between two frames (16.67 ms) is called the frame budget.
Sometimes you hear people talk about dropped frames. A dropped frame is when the system doesn’t finish its work within the frame budget. The display tries to get the new frame from the frame buffer before the browser is done filling it in. In this case, the display shows the old version of the frame again.
A dropped frame is kind of like if you tore a page out of that flip book. It would make the animation seem to stutter or jump because you’re missing the transition between the previous page and the next.
So we want to make sure that we get all of these pixels into the frame buffer before the display checks it again. Let’s look at how browsers have historically done this, and how that has changed over time. Then we can see how we can make this faster.
A brief history of painting and compositing
Note: Painting and compositing is where browser rendering engines are the most different from each other. Single-platform browsers (Edge and Safari) work a bit differently than multi-platform browsers (Firefox and Chrome) do.
Even in the earliest browsers, there were some optimizations to make pages render faster. For example, if you were scrolling content, the browser would keep the part that was still visible and move it. Then it would paint new pixels in the blank spot.
This process of figuring out what has changed and then only updating the changed elements or pixels is called invalidation.
As time went on, browsers started applying more invalidation techniques, like rectangle invalidation. With rectangle invalidation, you figure out the smallest rectangle around each part of the screen that changed. Then, you only redraw what’s inside those rectangles.
This really reduces the amount of work that you need to do when there’s not much changing on the page… for example, when you have a single blinking cursor.
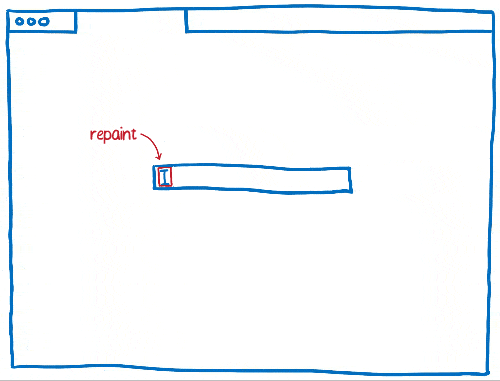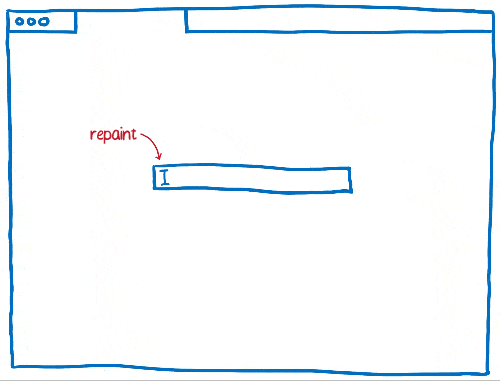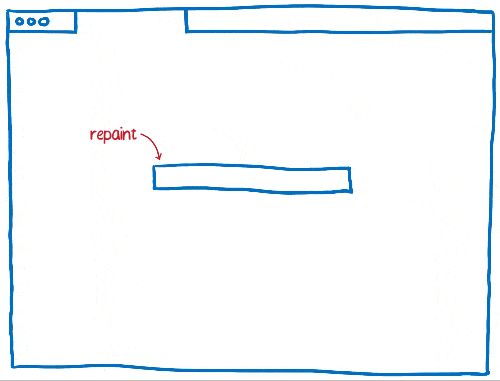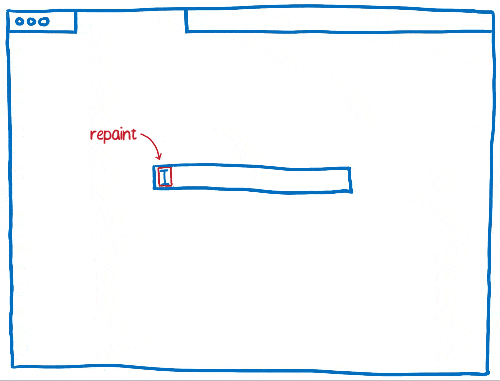
But that doesn’t help much when large parts of the page are changing. So the browsers came up with new techniques to handle those cases.
Introducing layers and compositing
Using layers can help a lot when large parts of the page are changing… at least, in certain cases.
The layers in browsers are a lot like layers in Photoshop, or the onion skin layers that were used in hand-drawn animation. Basically, you paint different elements of the page on different layers. Then you then place those layers on top of each other.
They have been a part of the browser for a long time, but they weren’t always used to speed things up. At first, they were just used to make sure pages rendered correctly. They corresponded to something called stacking contexts.
For example, if you had a translucent element, it would be in its own stacking context. That meant it got its own layer so you could blend its color with the color below it. These layers were thrown out as soon as the frame was done. On the next frame, all the layers would be repainted again.
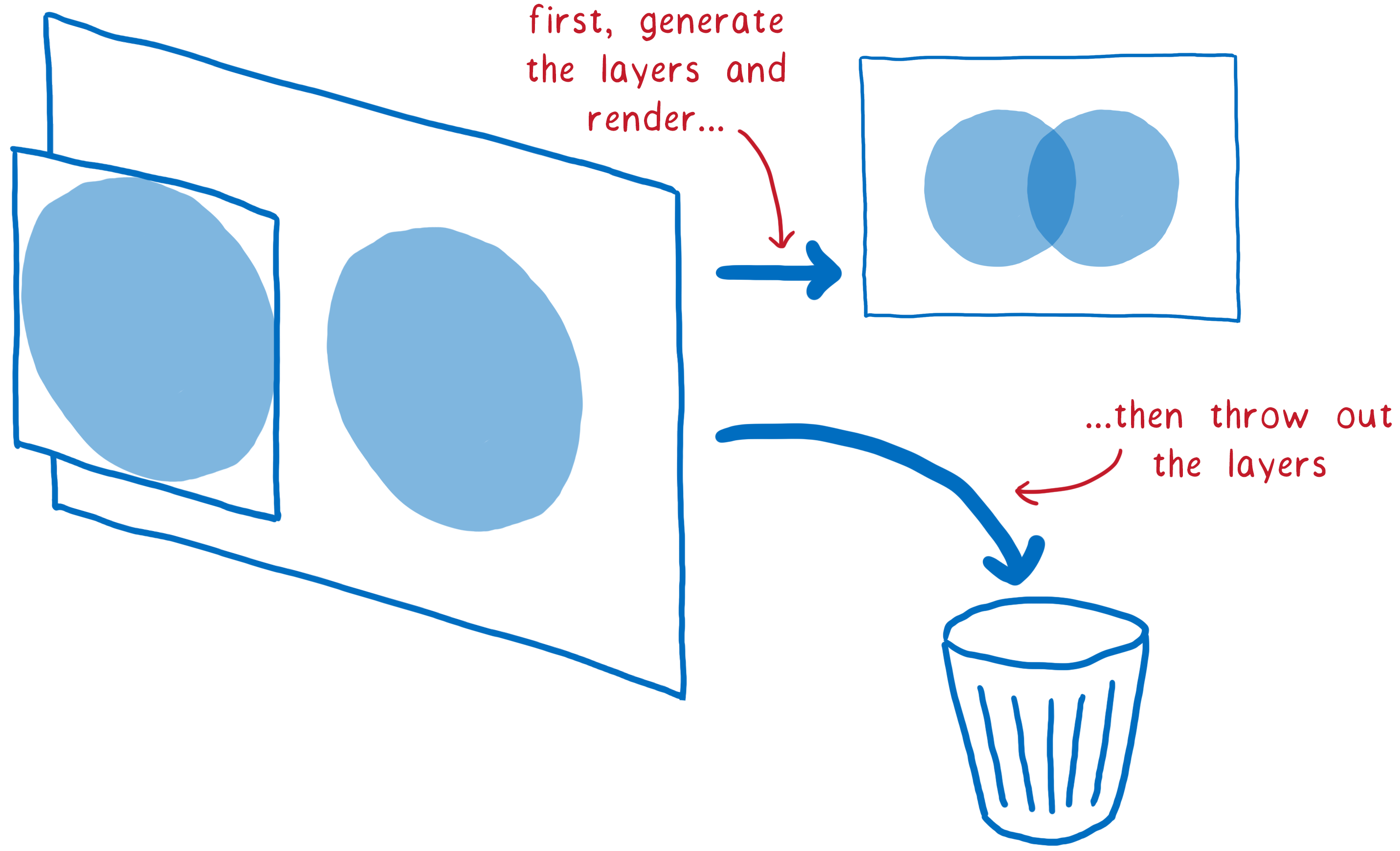
But often the things on these layers didn’t change from frame to frame. For example, think of a traditional animation. The background doesn’t change, even if the characters in the foreground do. It’s a lot more efficient to keep that background layer around and just reuse it.
So that’s what browsers did. They retained the layers. Then the browser could just repaint layers that had changed. And in some cases, layers weren’t even changing. They just needed to be rearranged—for example, if an animation was moving across the screen, or something was being scrolled.
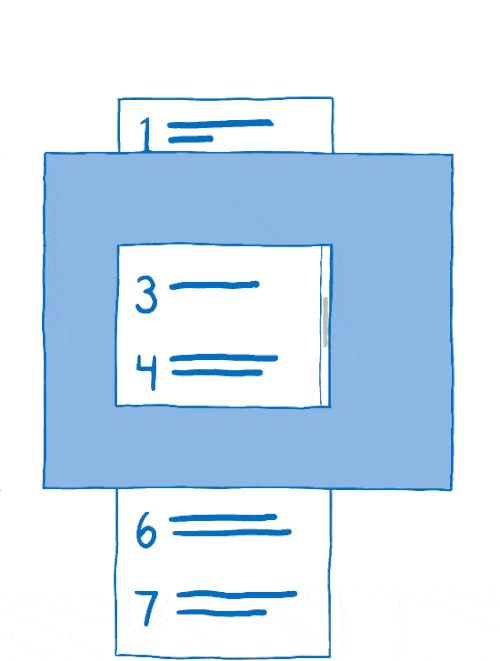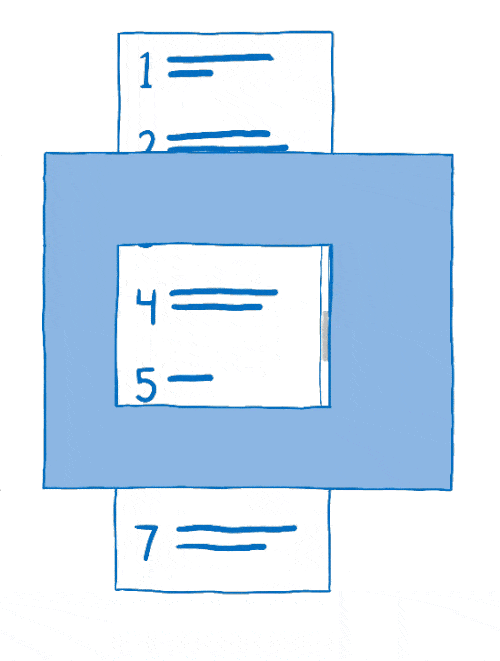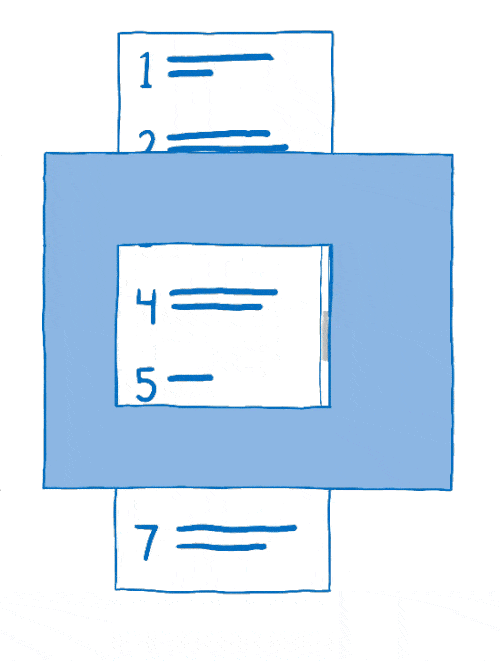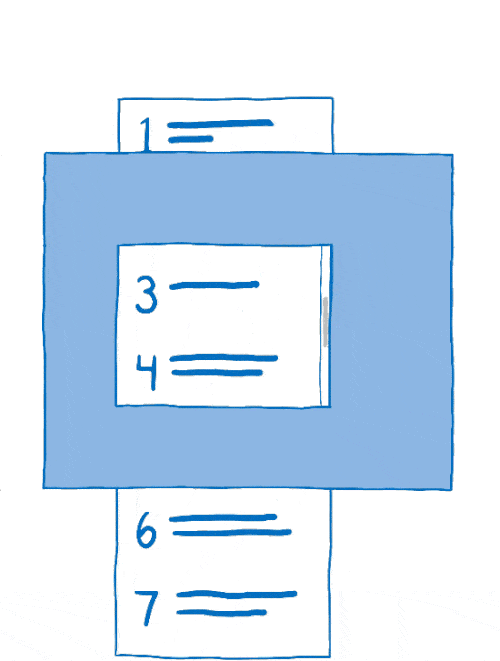
This process of arranging layers together is called compositing. The compositor starts with:
- source bitmaps: the background (including a blank box where the scrollable content should be) and the scrollable content itself
- a destination bitmap, which is what gets displayed on the screen
First, the compositor would copy the background to the destination bitmap.
Then it would figure out what part of the scrollable content should be showing. It would copy that part over to the destination bitmap.
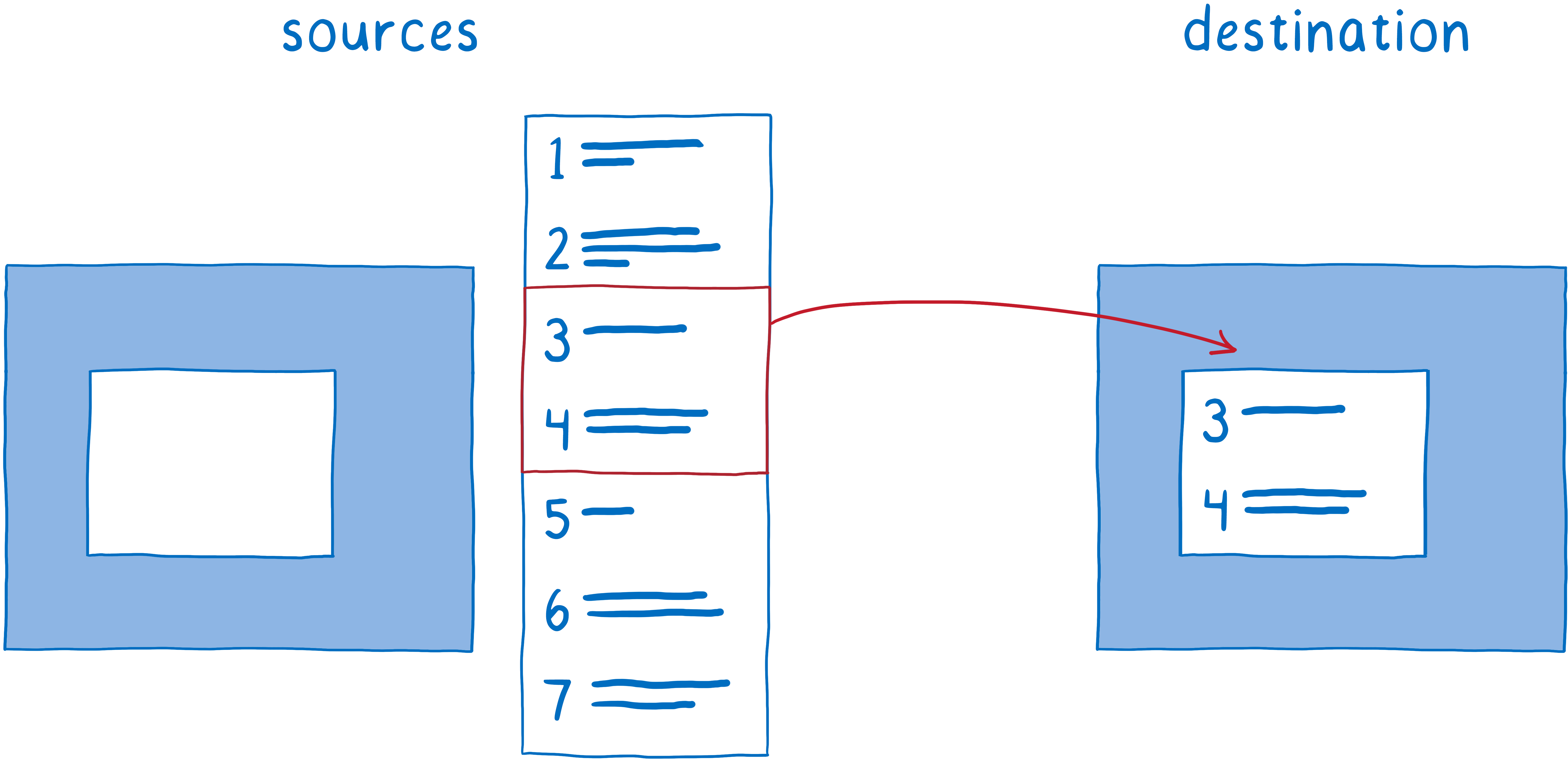
This reduced the amount of painting that the main thread had to do. But it still means that the main thread is spending a lot of time on compositing. And there are lots of things competing for time on the main thread.
I’ve talked about this before, but the main thread is kind of like a full-stack developer. It’s in charge of the DOM, layout, and JavaScript. And it also was in charge of painting and compositing.
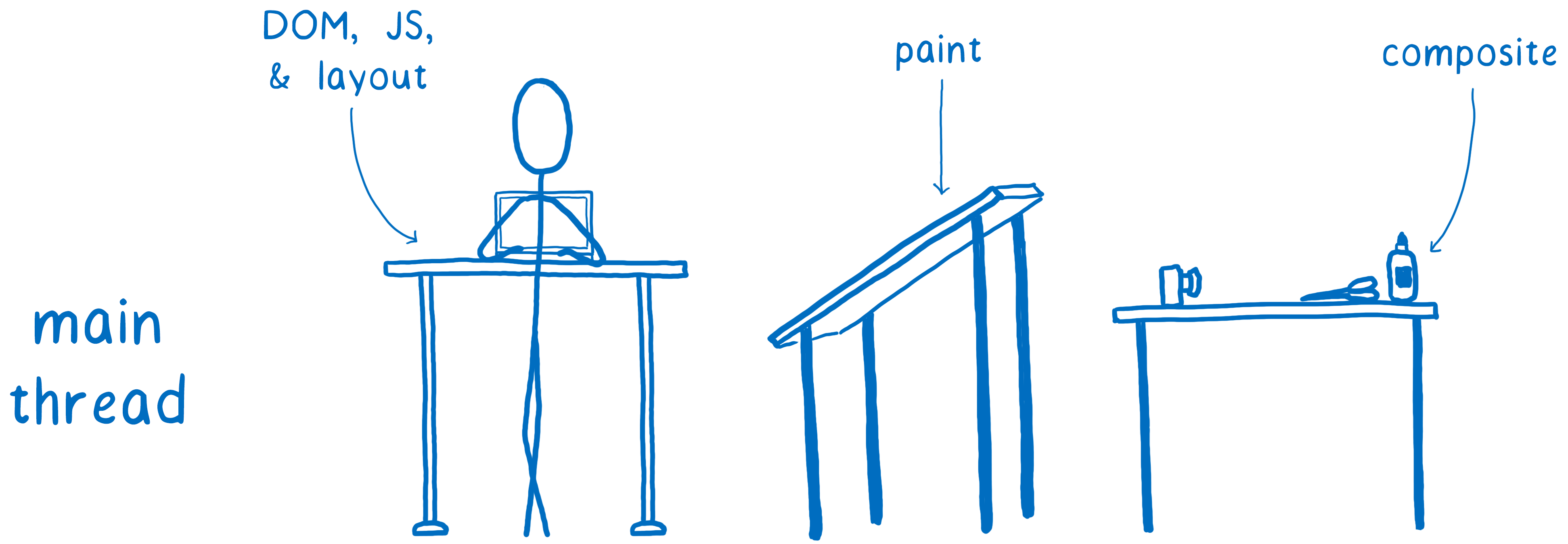
Every millisecond the main thread spends doing paint and composite is time it can’t spend on JavaScript or layout.

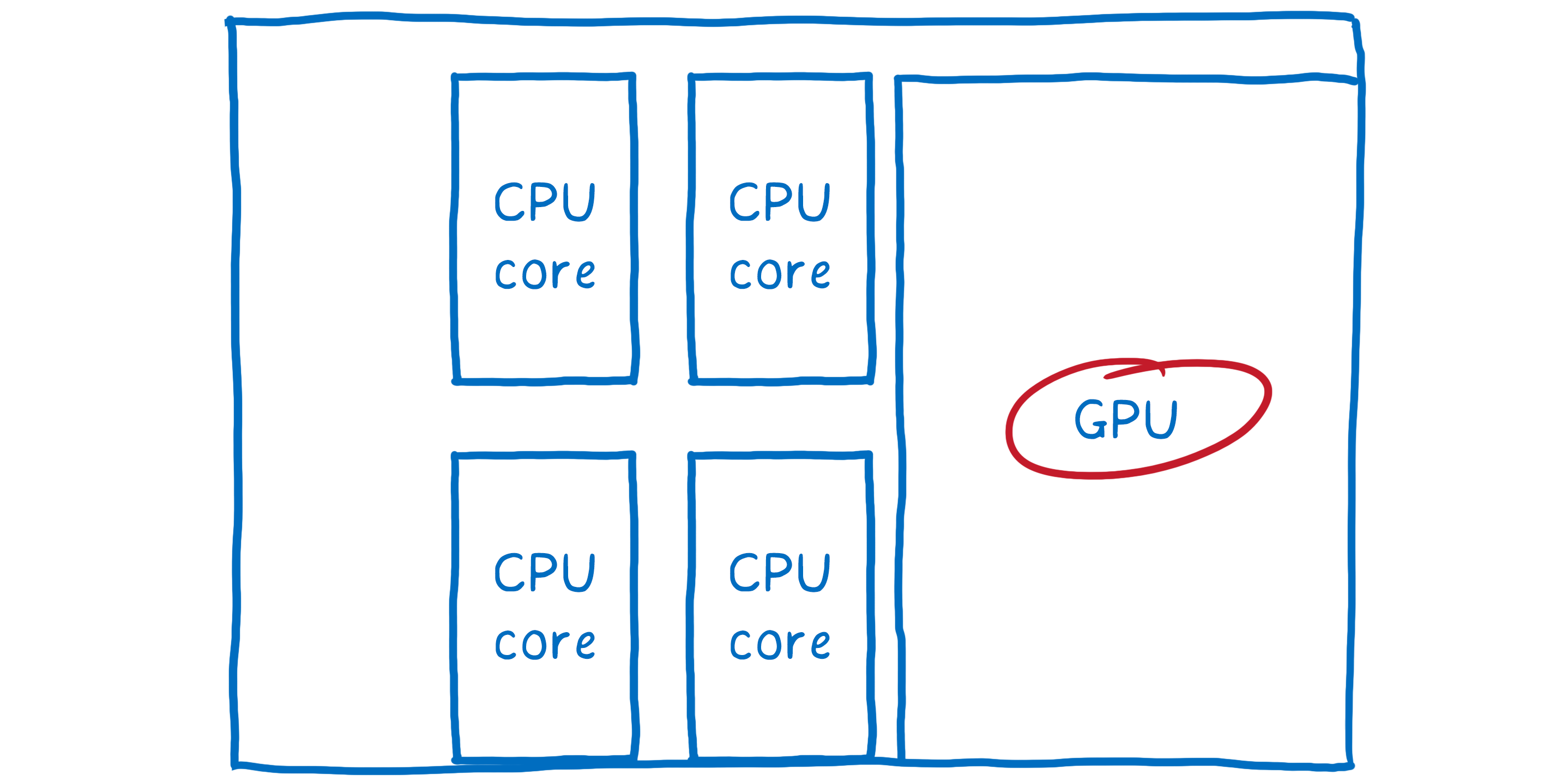
But there was another part of the hardware that was lying around without much work to do. And this hardware was specifically built for graphics. That was the GPU, which games have been using since the late 90s to render frames quickly. And GPUs have been getting bigger and more powerful ever since then.
GPU accelerated compositing
So browser developers started moving things over to the GPU.
There are two tasks that could potentially move over to the GPU:
- Painting the layers
- Compositing them together
It can be hard to move painting to the GPU. So for the most part, multi-platform browsers kept painting on the CPU.
But compositing was something that the GPU could do very quickly, and it was easy to move over to the GPU.
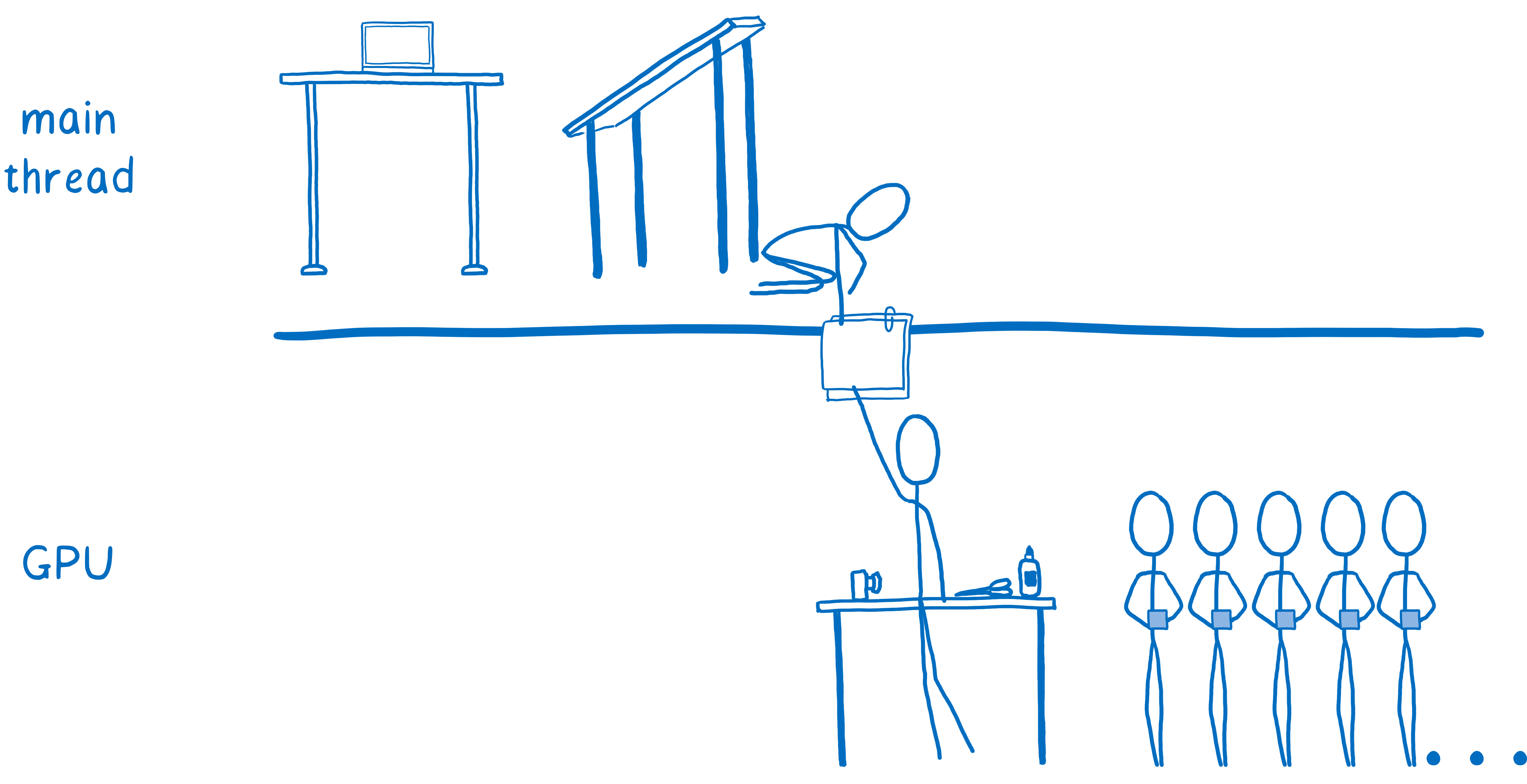
Some browsers took this parallelism even further and added a compositor thread on the CPU. It became a manager for the compositing work that was happening on the GPU. This meant that if the main thread was doing something (like running JavaScript), the compositor thread could still handle things for the user, like scrolling content up when the user scrolled.
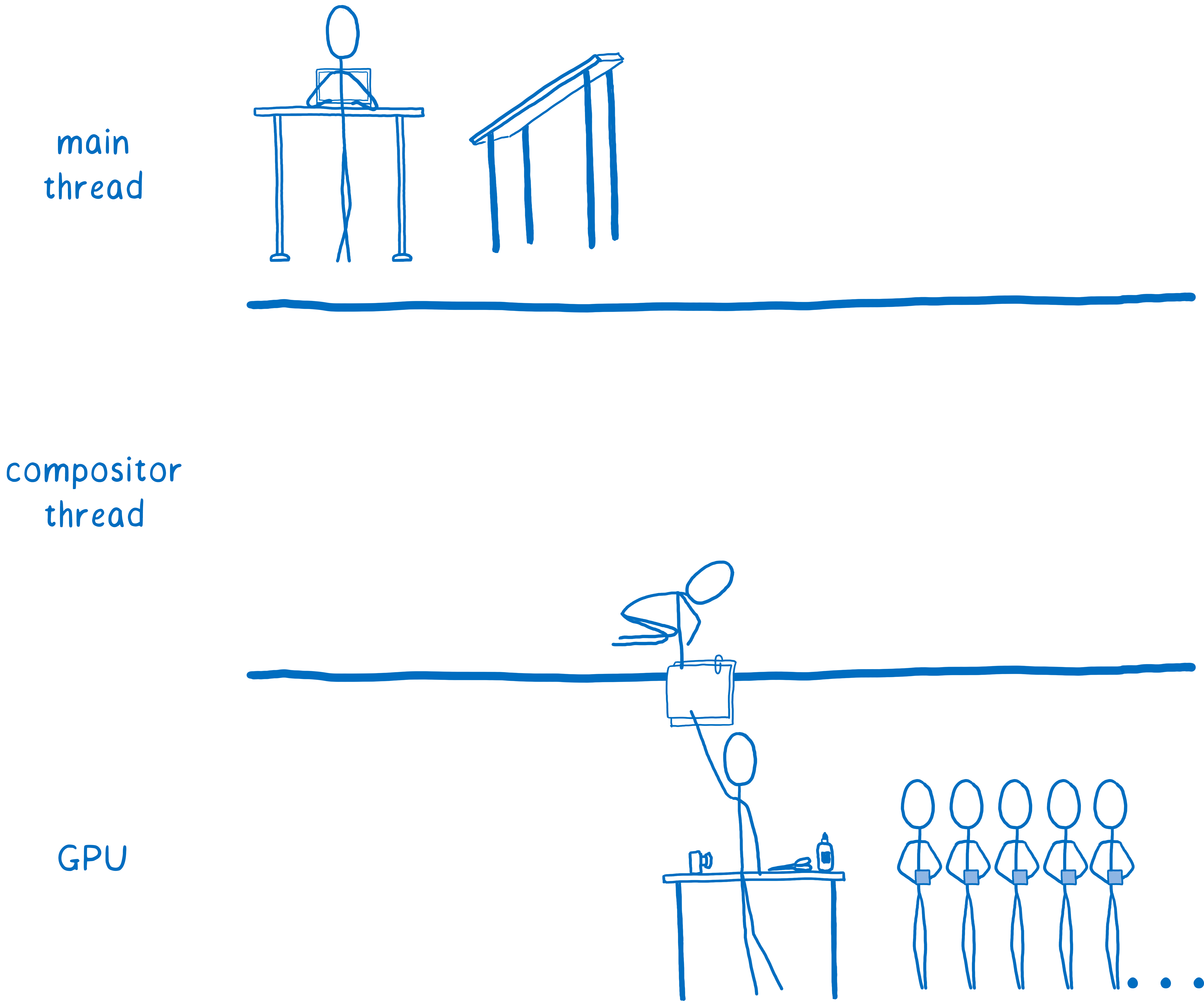
So this moves all of the compositing work off of the main thread. It still leaves a lot of work on the main thread, though. Whenever we need to repaint a layer, the main thread needs to do it, and then transfer that layer over to the GPU.
Some browsers moved painting off to another thread (and we’re working on that in Firefox today). But it’s even faster to move this last little bit of work — painting — to the GPU.
GPU accelerated painting
So browsers started moving painting to the GPU, too.
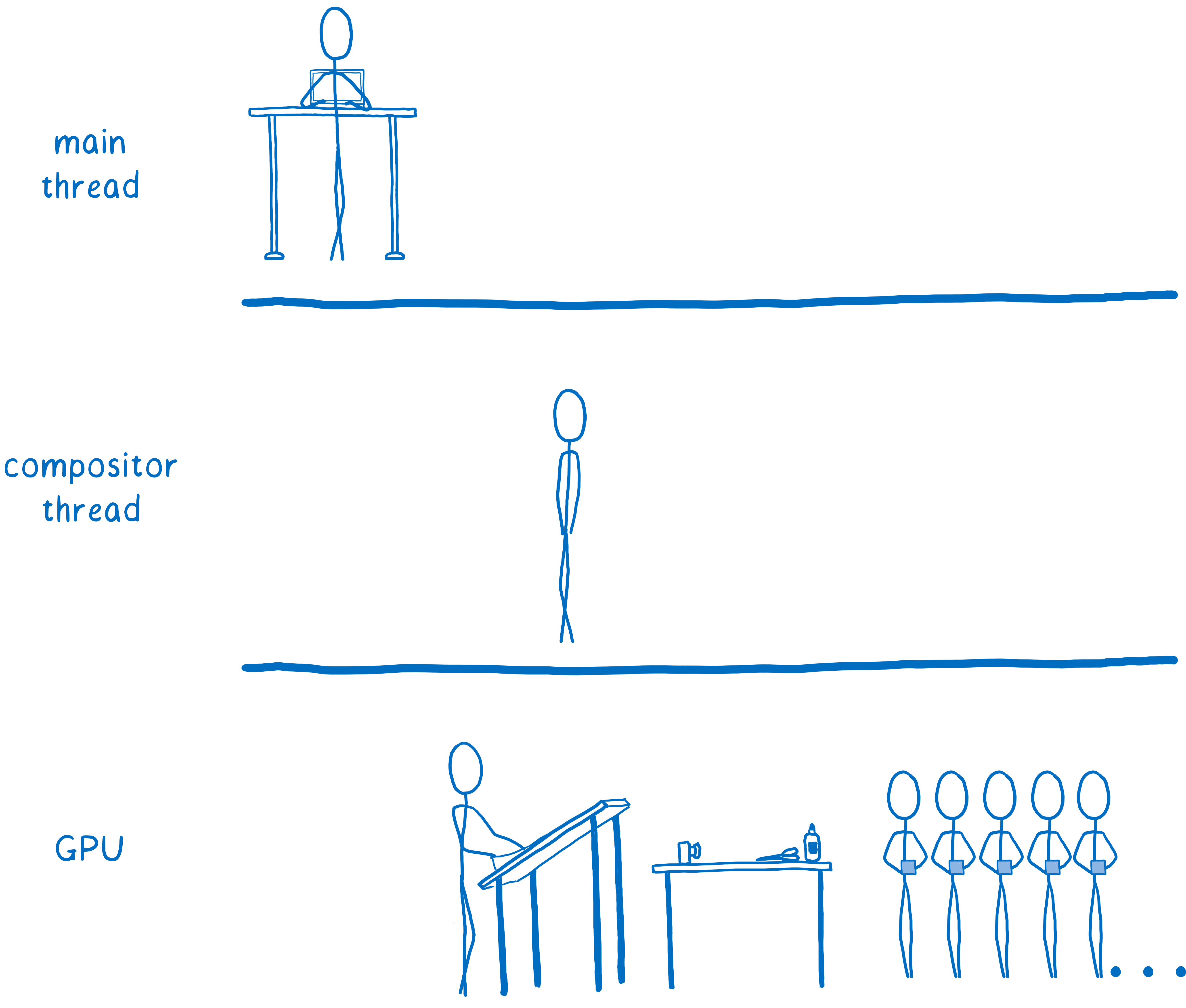
Browsers are still in the process of making this shift. Some browsers paint on the GPU all of the time, while others only do it on certain platforms (like only on Windows, or only on mobile devices).
Painting on the GPU does a few things. It frees up the CPU to spend all of its time doing things like JavaScript and layout. Plus, GPUs are much faster at drawing pixels than CPUs are, so it speeds painting up. It also means less data needs to be copied from the CPU to the GPU.
But maintaining this division between paint and composite still has some costs, even when they are both on the GPU. This division also limits the kinds of optimizations that you can use to make the GPU do its work faster.
This is where WebRender comes in. It fundamentally changes the way we render, removing the distinction between paint and composite. This gives us a way to tailor the performance of our renderer to give you the best user experience on today’s web, and to best support the use cases that you will see on tomorrow’s web.
This means we don’t just want to make frames render faster… we want to make them render more consistently and without jank. And even when there are lots of pixels to draw, like on 4k displays or WebVR headsets, we still want the experience to be just as smooth.
When do current browsers get janky?
The optimizations above have helped pages render faster in certain cases. When not much is changing on a page—for example, when there’s just a single blinking cursor—the browser will do the least amount of work possible.
Breaking up pages into layers has expanded the number of those best-case scenarios. If you can paint a few layers and then just move them around relative to each other, then the painting+compositing architecture works well.
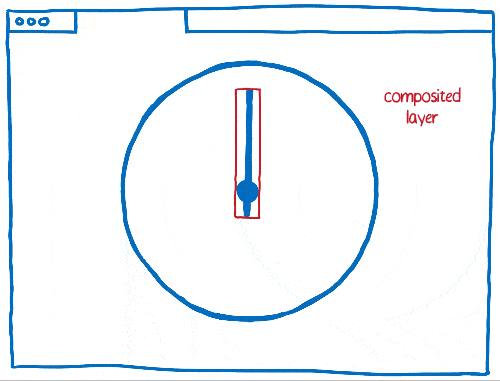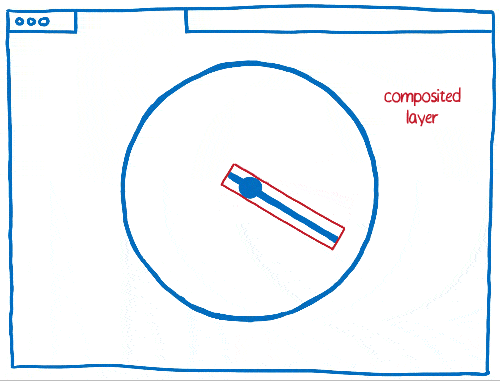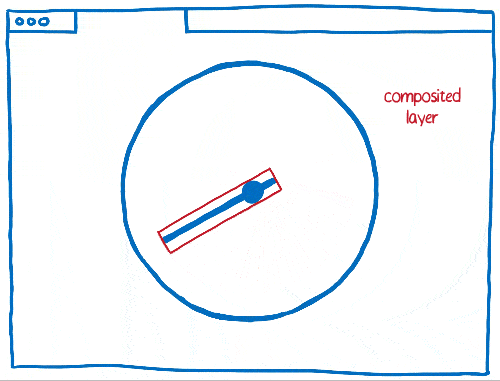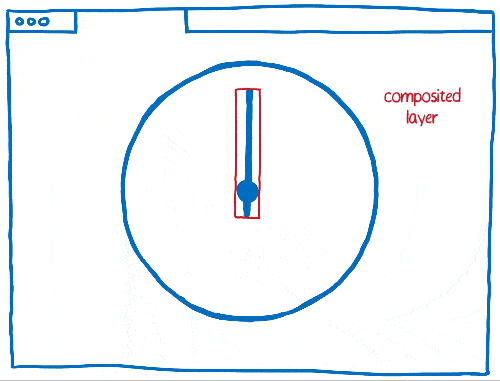
But there are also trade offs to using layers. They take up a lot of memory and can actually make things slower. Browsers need to combine layers where it makes sense… but it’s hard to tell where it makes sense.
This means that if there are a lot of different things moving on the page, you can end up with too many layers. These layers fill up memory and take too long to transfer to the compositor.
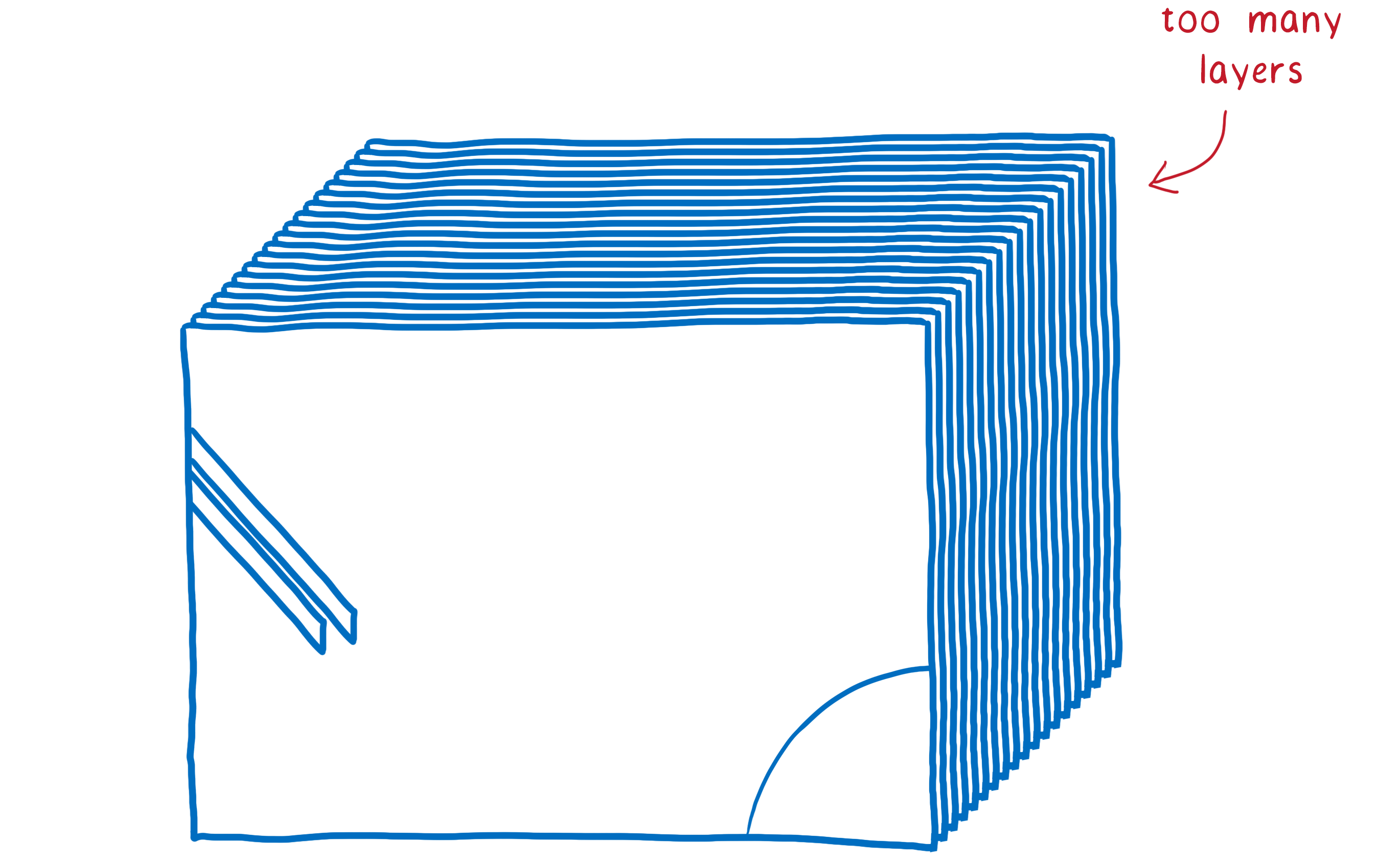
Other times, you’ll end up with one layer when you should have multiple layers. That single layer will be continually repainted and transferred to the compositor, which then composites it without changing anything.
This means you’ve doubled the amount of drawing you have to do, touching each pixel twice without getting any benefit. It would have been faster to simply render the page directly, without the compositing step.
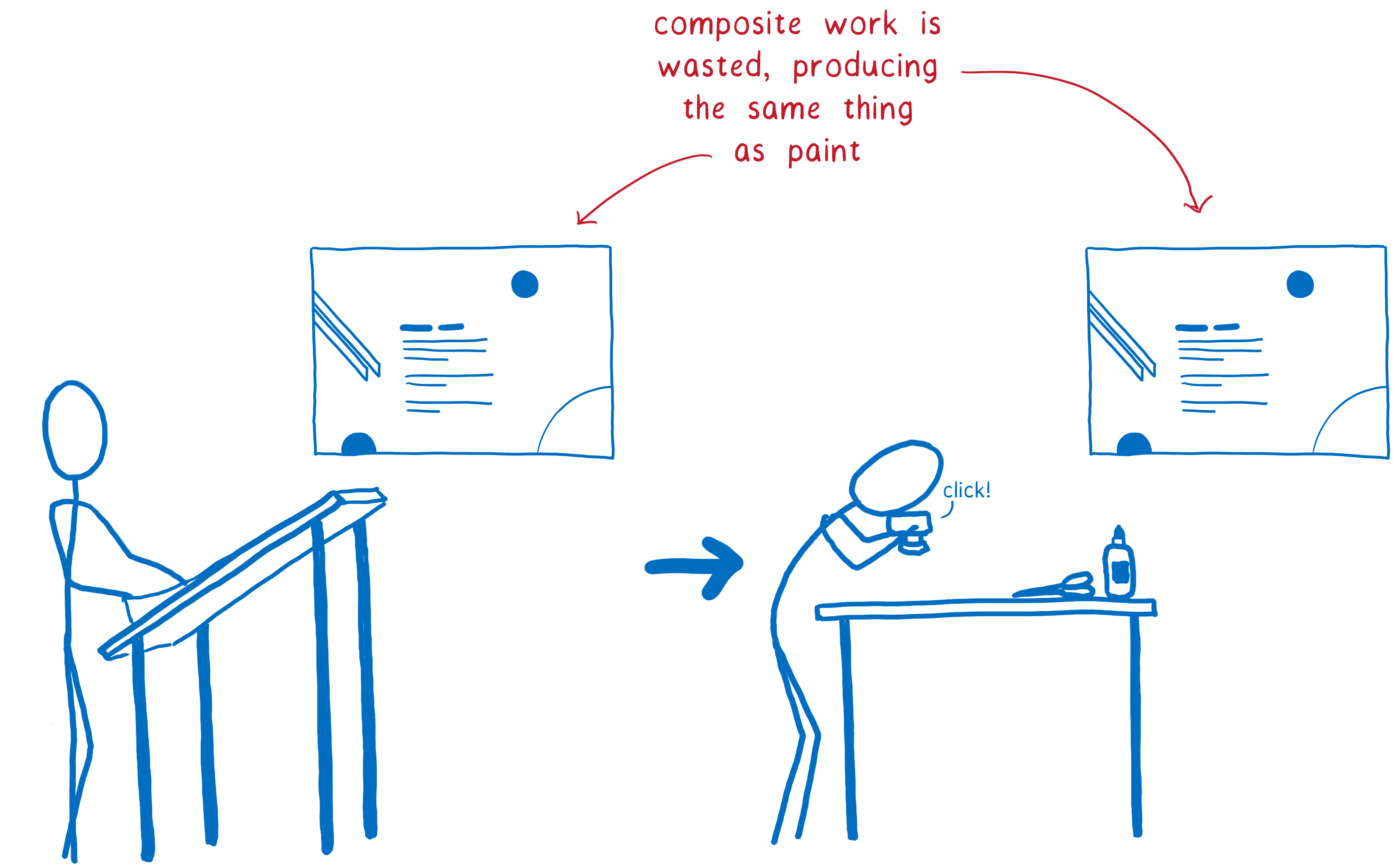
And there are lots of cases where layers just don’t help much. For example, if you animate background color, the whole layer has to be repainted anyway. These layers only help with a small number of CSS properties.
Even if most of your frames are best-case scenarios—that is, they only take up a tiny bit of the frame budget—you can still get choppy motion. For perceptible jank, only a couple of frames need to fall into worst-case scenarios.

These scenarios are called performance cliffs. Your app seems to be moving along fine until it hits one of these worst-case scenarios (like animating background color) and all of the sudden your app’s frame rate topples over the edge.
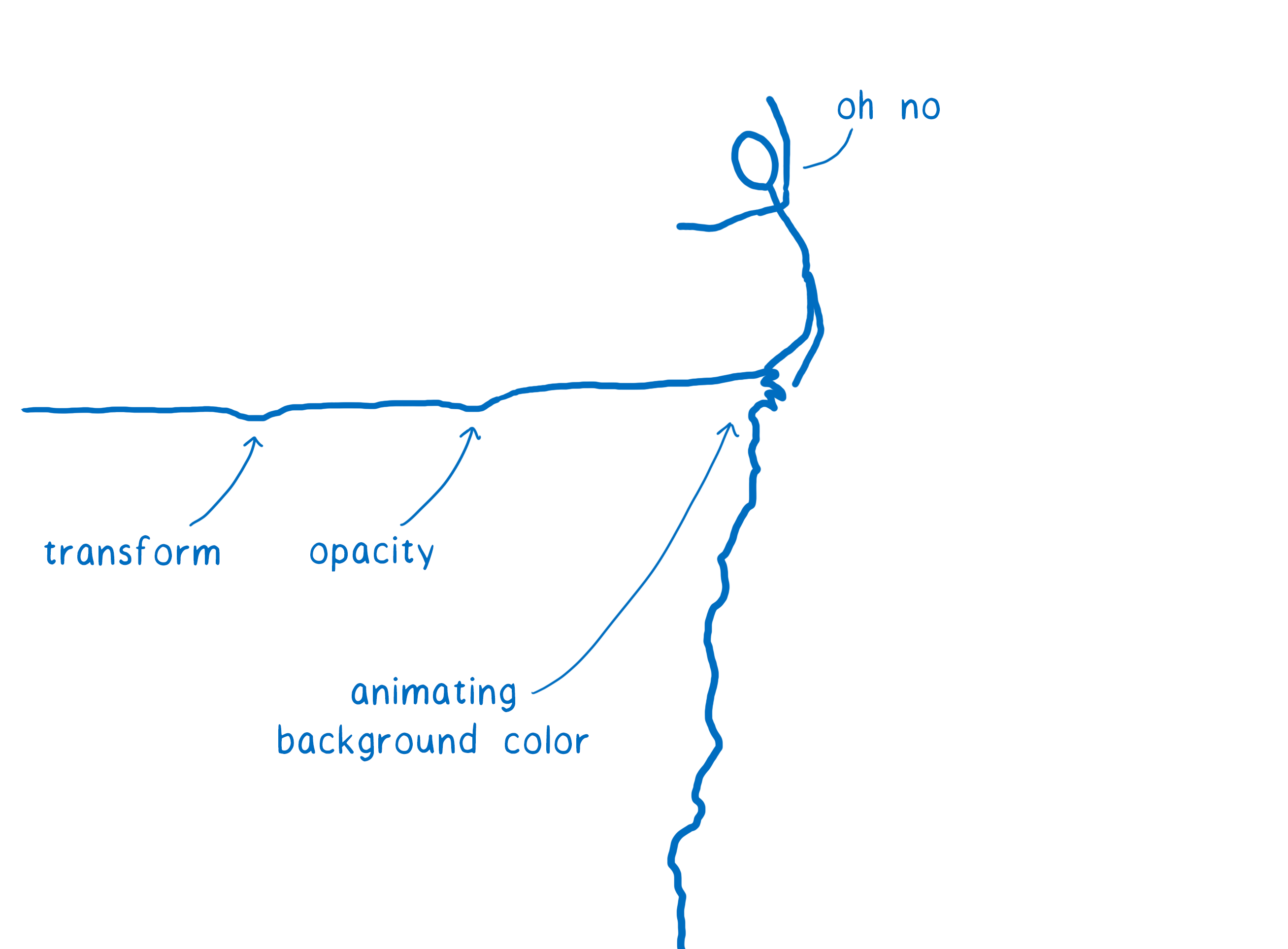
But we can get rid of these performance cliffs.
How do we do this? We follow the lead of 3D game engines.
Using the GPU like a game engine
What if we stopped trying to guess what layers we need? What if we removed this boundary between painting and compositing and just went back to painting every pixel on every frame?
This may sound like a ridiculous idea, but it actually has some precedent. Modern day video games repaint every pixel, and they maintain 60 frames per second more reliably than browsers do. And they do it in an unexpected way… instead of creating these invalidation rectangles and layers to minimize what they need to paint, they just repaint the whole screen.
Wouldn’t rendering a web page like that be way slower?
If we paint on the CPU, it would be. But GPUs are designed to make this work.
GPUs are built for extreme parallelism. I talked about parallelism in my last article about Stylo. With parallelism, the machine can do multiple things at the same time. The number of things it can do at once is limited by the number of cores that it has.
CPUs usually have between 2 and 8 cores. GPUs usually have at least a few hundred cores, and often more than 1,000 cores.
These cores work a little differently, though. They can’t act completely independently like CPU cores can. Instead, they usually work on something together, running the same instruction on different pieces of the data.
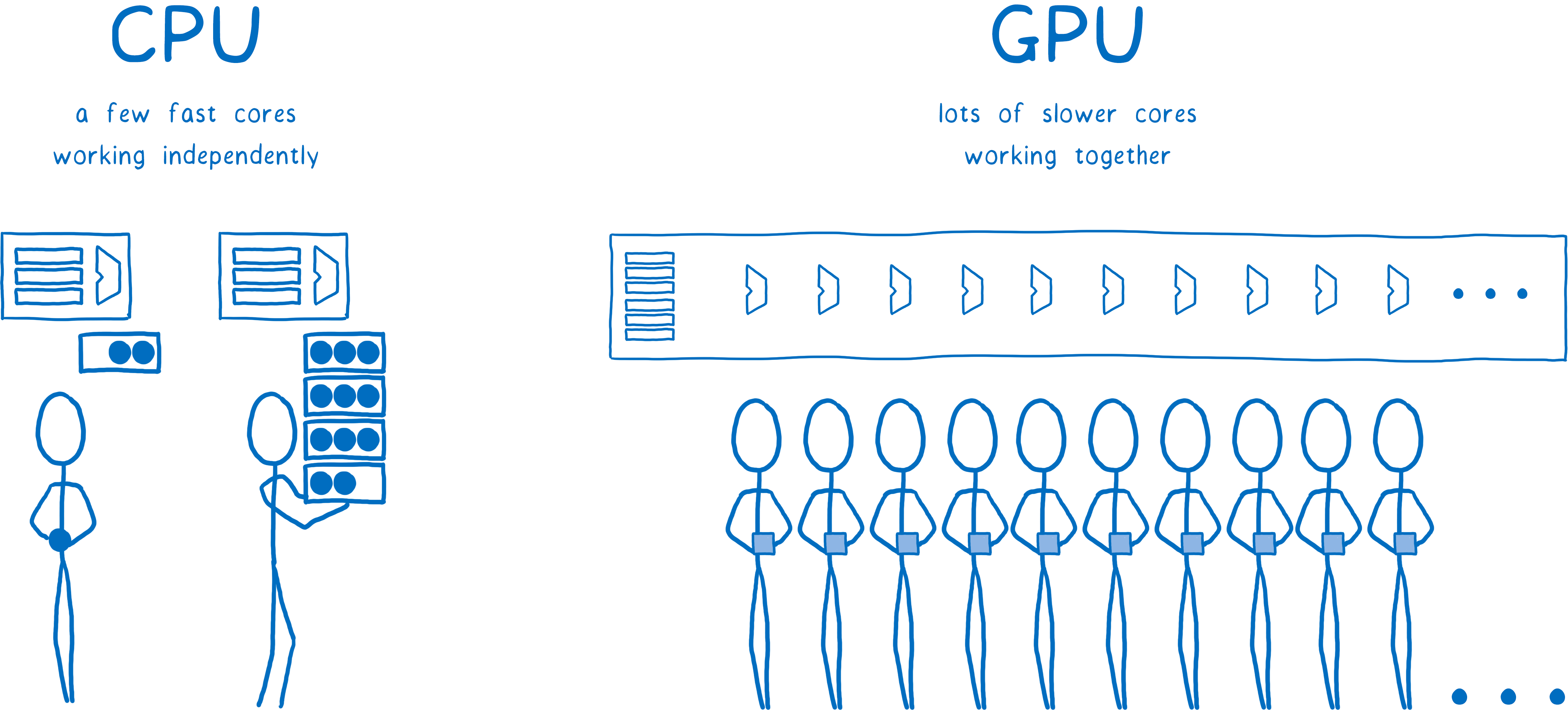
This is exactly what you need when you’re filling in pixels. Each pixel can be filled in by a different core. Because it can work on hundreds of pixels at a time, the GPU is a lot faster at filling in pixels than the CPU… but only if you make sure all of those cores have work to do.
Because cores need to work on the same thing at the same time, GPUs have a pretty rigid set of steps that they go through, and their APIs are pretty constrained. Let’s take a look at how this works.
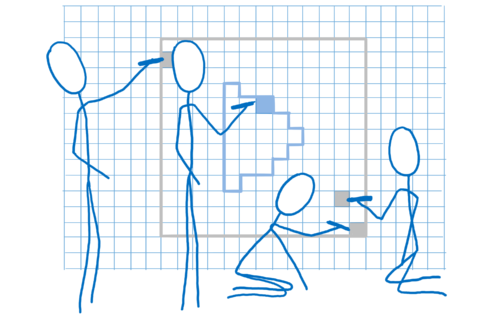
First, you need to tell the GPU what to draw. This means giving it shapes and telling it how to fill them in.
To do this, you break up your drawing into simple shapes (usually triangles). These shapes are in 3D space, so some shapes can be behind others. Then you take all of the corners of those triangles and put their x, y, and z coordinates into an array.
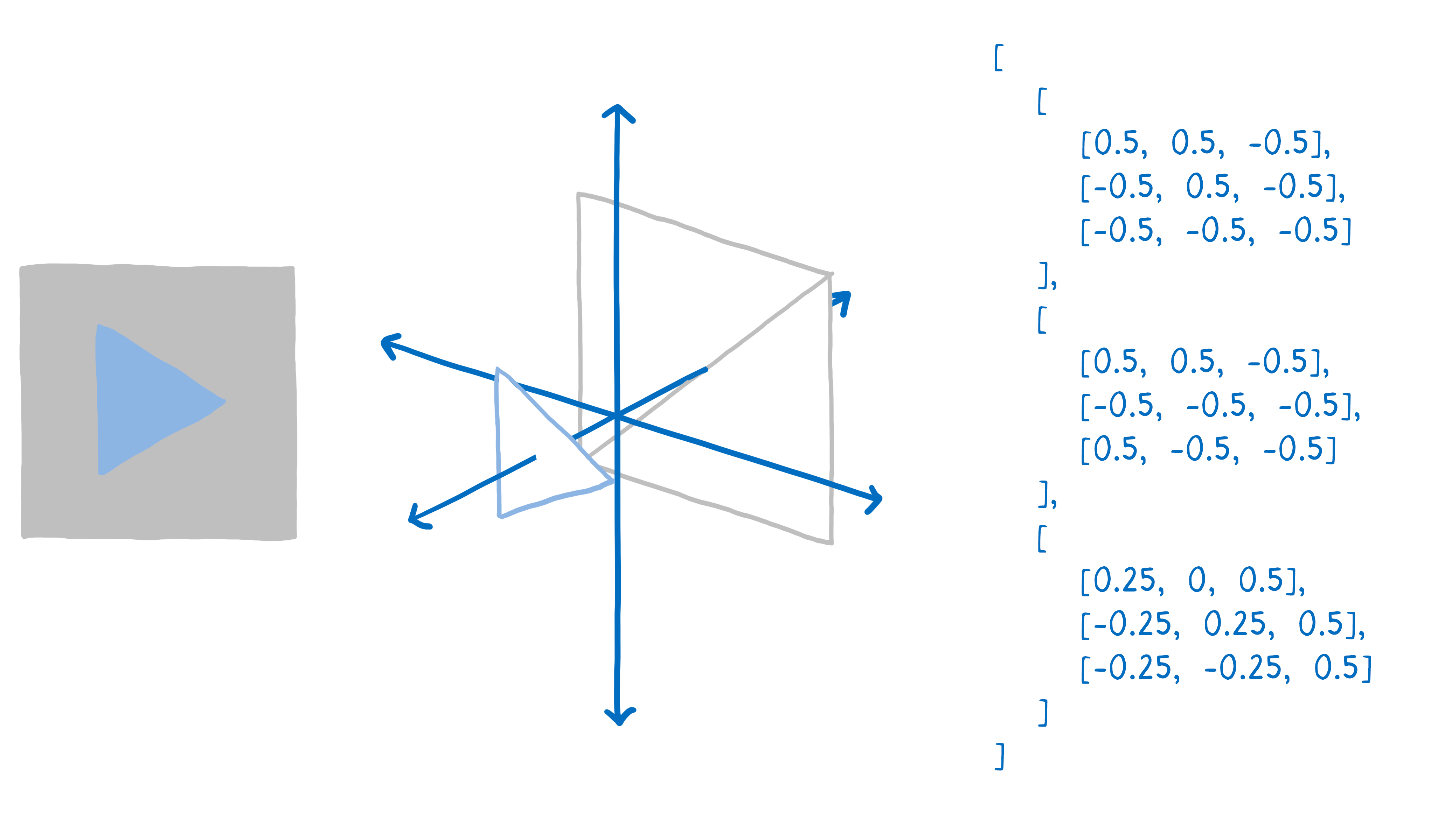
Then you issue a draw call—you tell the GPU to draw those shapes.
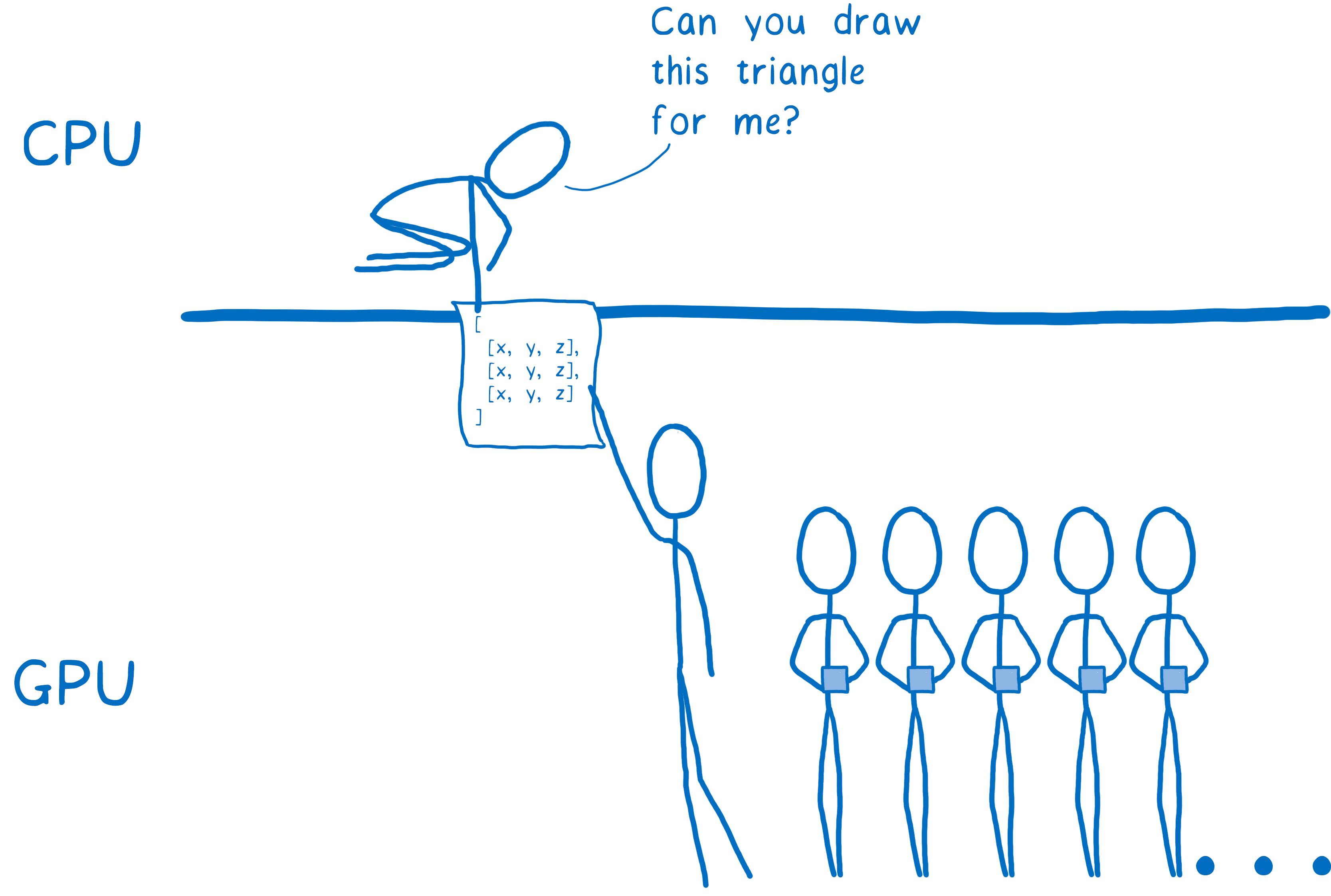
From there, the GPU takes over. All of the cores will work on the same thing at the same time. They will:
- Figure out where all of the corners of the shapes are. This is called vertex shading.
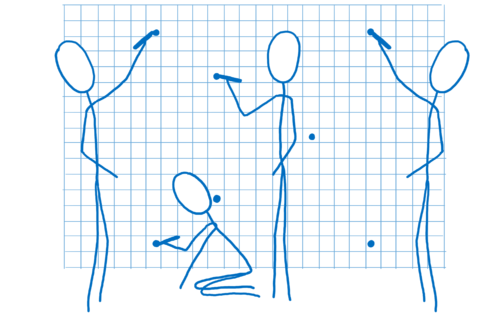
- Figure out the lines that connect those corners. From this, you can figure out which pixels are covered by the shape. That’s called rasterization.
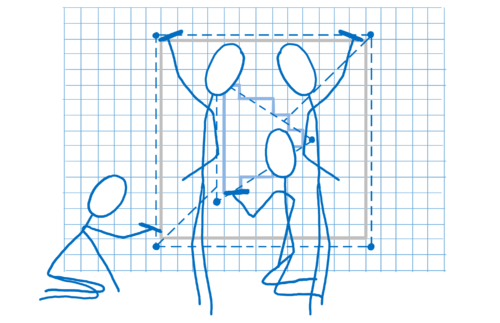
- Now that we know what pixels are covered by a shape, go through each pixel in the shape and figure out what color it should be. This is called pixel shading.
This last step can be done in different ways. To tell the GPU how to do it, you give the GPU a program called a pixel shader. Pixel shading is one of the few parts of the GPU that you can program.
Some pixel shaders are simple. For example, if your shape is a single color, then your shader program just needs to return that color for each pixel in the shape.
Other times, it’s more complex, like when you have a background image. You need to figure out which part of the image corresponds to each pixel. You can do this in the same way an artist scales an image up or down… put a grid on top of the image that corresponds to each pixel. Then, once you know which box corresponds to the pixel, take samples of the colors inside that box and figure out what the color should be. This is called texture mapping because it maps the image (called a texture) to the pixels.
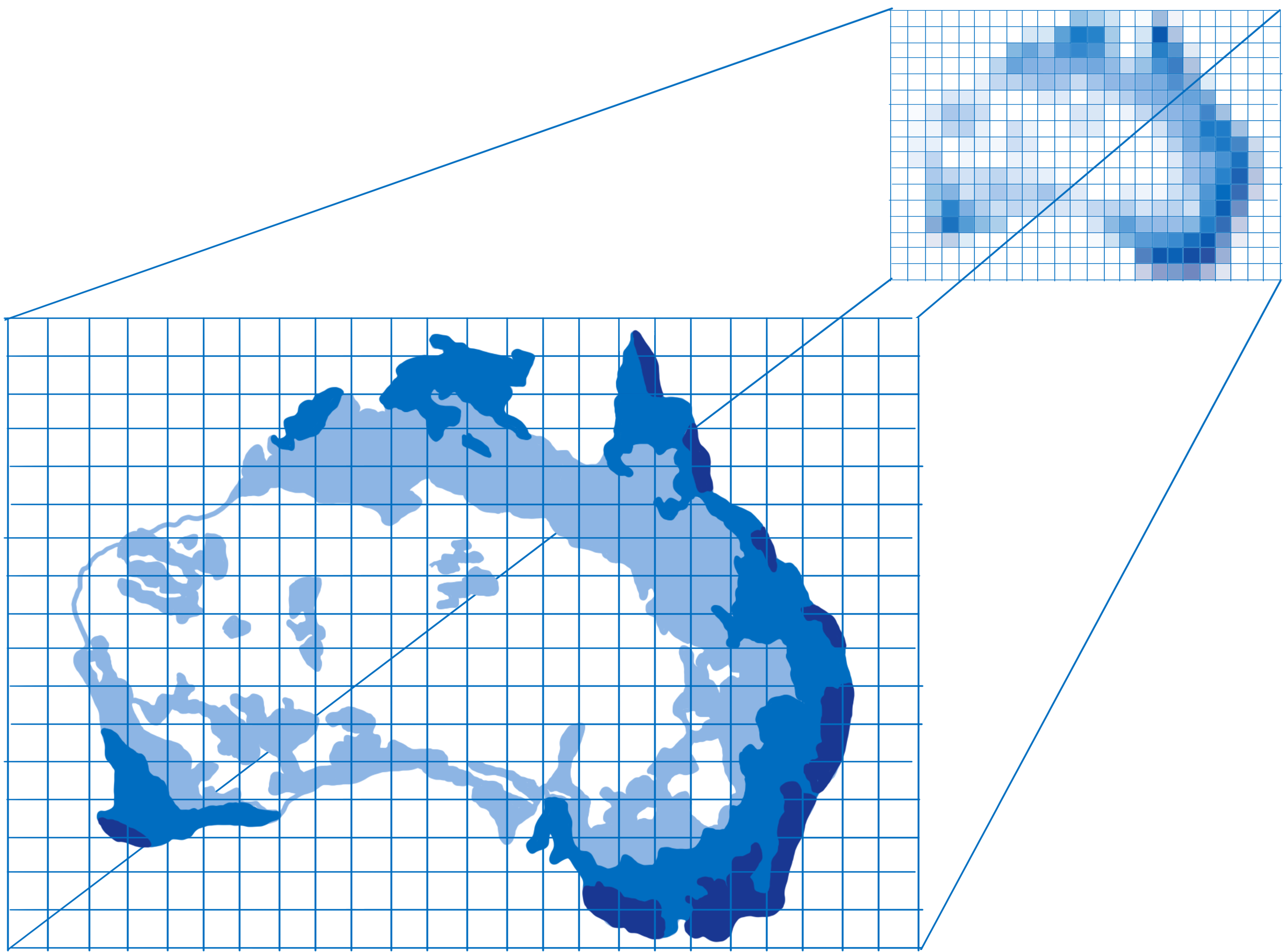
The GPU will call your pixel shader program on each pixel. Different cores will work on different pixels at the same time, in parallel, but they all need to be using the same pixel shader program. When you tell the GPU to draw your shapes, you tell it which pixel shader to use.
For almost any web page, different parts of the page will need to use different pixel shaders.
Because the shader applies to all of the shapes in the draw call, you usually have to break up your draw calls in multiple groups. These are called batches. To keep all of the cores as busy as possible, you want to create a small number of batches which have lots of shapes in them.
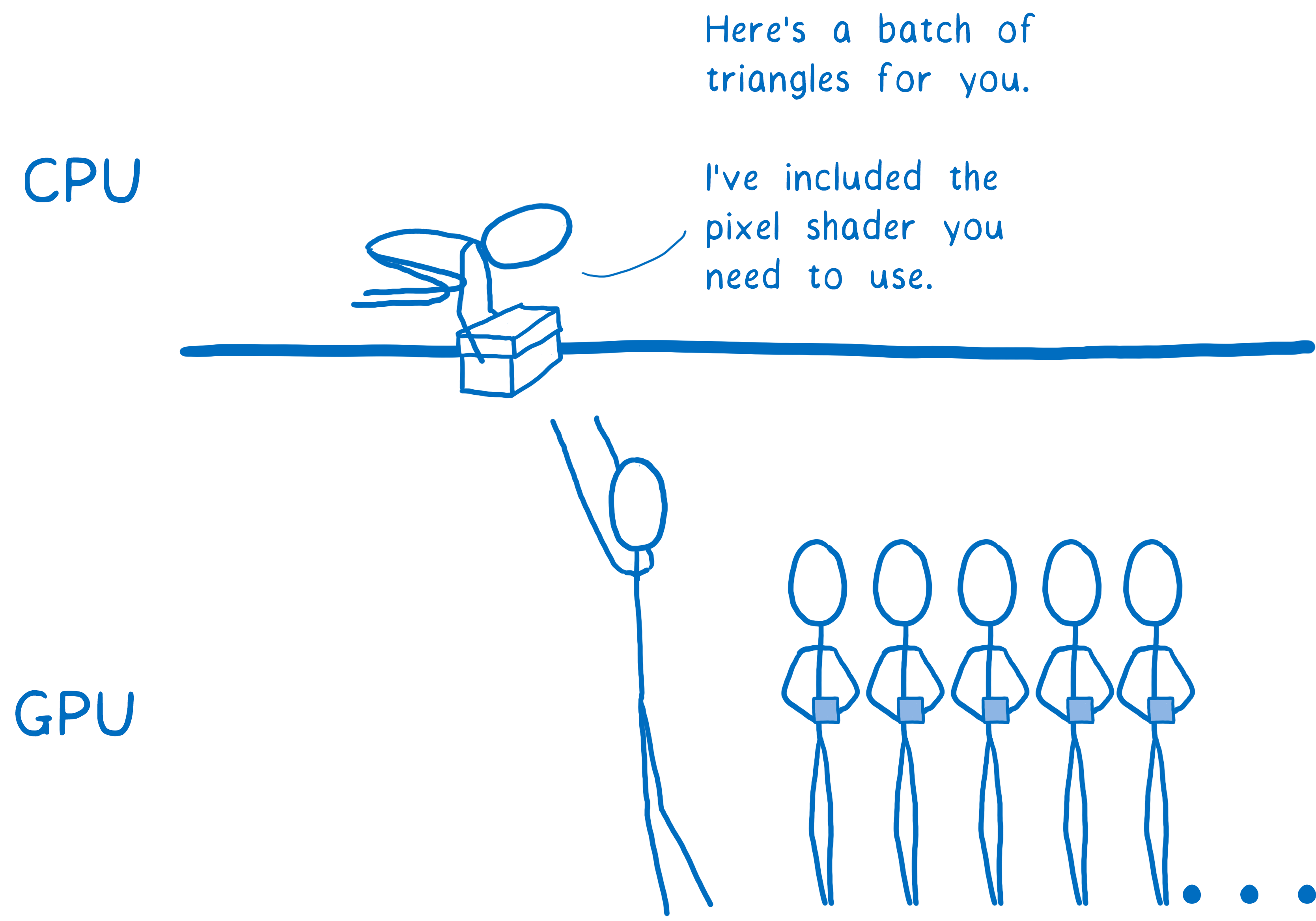
So that’s how the GPU splits up work across hundreds or thousands of cores. It’s only because of this extreme parallelism that we can think of rendering everything on each frame. Even with the extreme parallelism, though, it’s still a lot of work. You still need to be smart about how you do this. Here’s where WebRender comes in…
How WebRender works with the GPU
Let’s go back to look at the steps the browser goes through to render the page. Two things will change here.
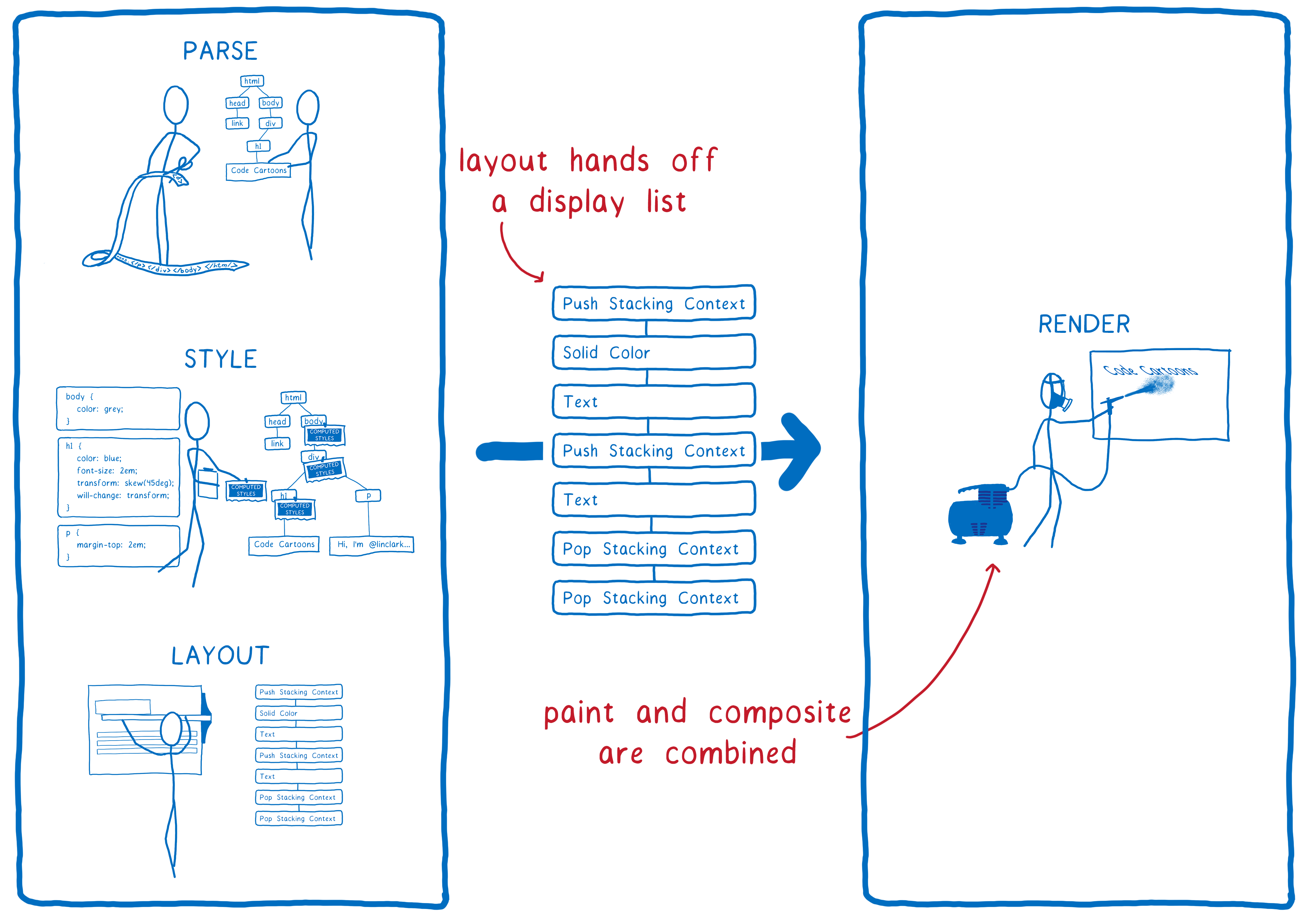
- There’s no longer a distinction between paint and composite… they are both part of the same step. The GPU does them at the same time based on the graphics API commands that were passed to it.
- Layout now gives us a different data structure to render. Before, it was something called a frame tree (or render tree in Chrome). Now, it passes off a display list.
The display list is a set of high-level drawing instructions. It tells us what we need to draw without being specific to any graphics API.
Whenever there’s something new to draw, the main thread gives that display list to the RenderBackend, which is WebRender code that runs on the CPU.
The RenderBackend’s job is to take this list of high-level drawing instructions and convert it to the draw calls that the GPU needs, which are batched together to make them run faster.
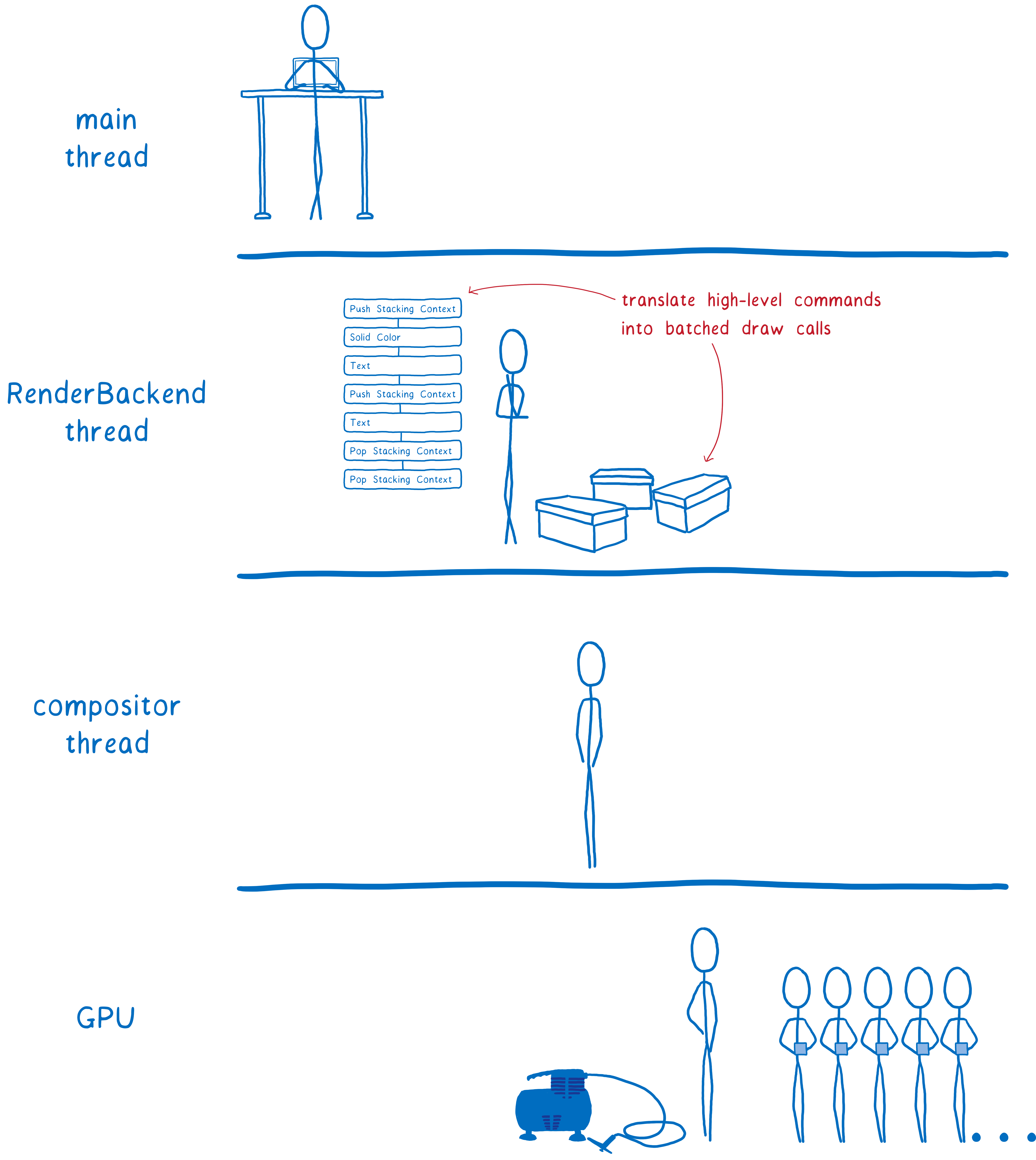
Then the RenderBackend will pass those batches off to the compositor thread, which passes them to the GPU.
The RenderBackend wants to make the draw calls it’s giving to the GPU as fast to run as possible. It uses a few different techniques for this.
Removing any unnecessary shapes from the list (Early culling)
The best way to save time is to not do the work at all.
First, the RenderBackend cuts down the list of display items. It figures out which display items will actually be on the screen. To do this, it looks at things like how far down the scroll is for each scroll box.
If any part of a shape is inside the box, then it is included. If none of the shape would have shown up on the page, though, it’s removed. This process is called early culling.

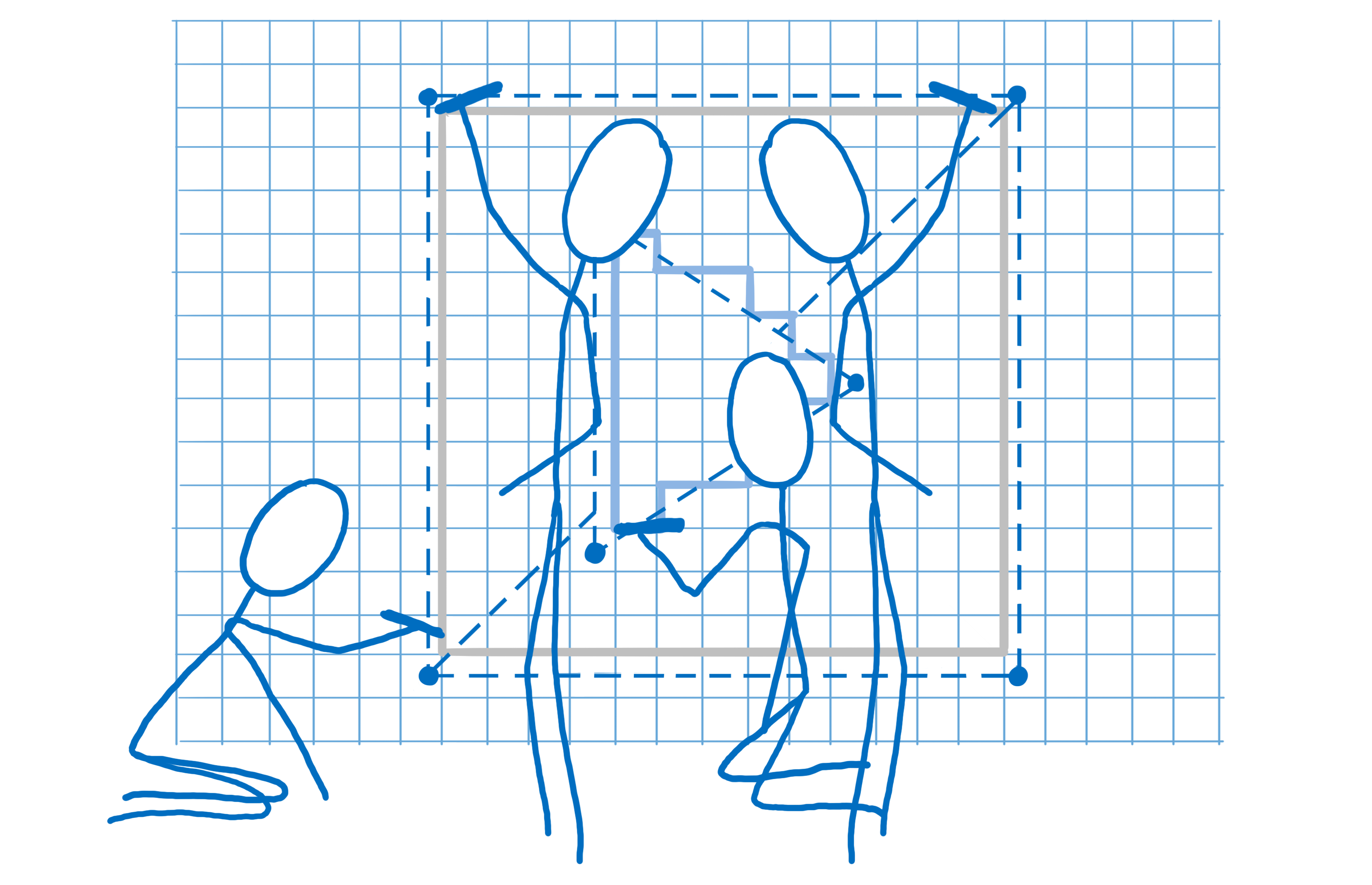
Minimizing the number of intermediate textures (The render task tree)
Now we have a tree that only contains the shapes we’ll use. This tree is organized into those stacking contexts we talked about before.
Effects like CSS filters and stacking contexts make things a little complicated. For example, let’s say you have an element that has an opacity of 0.5 and it has children. You might think that each child is transparent… but it’s actually the whole group that’s transparent.
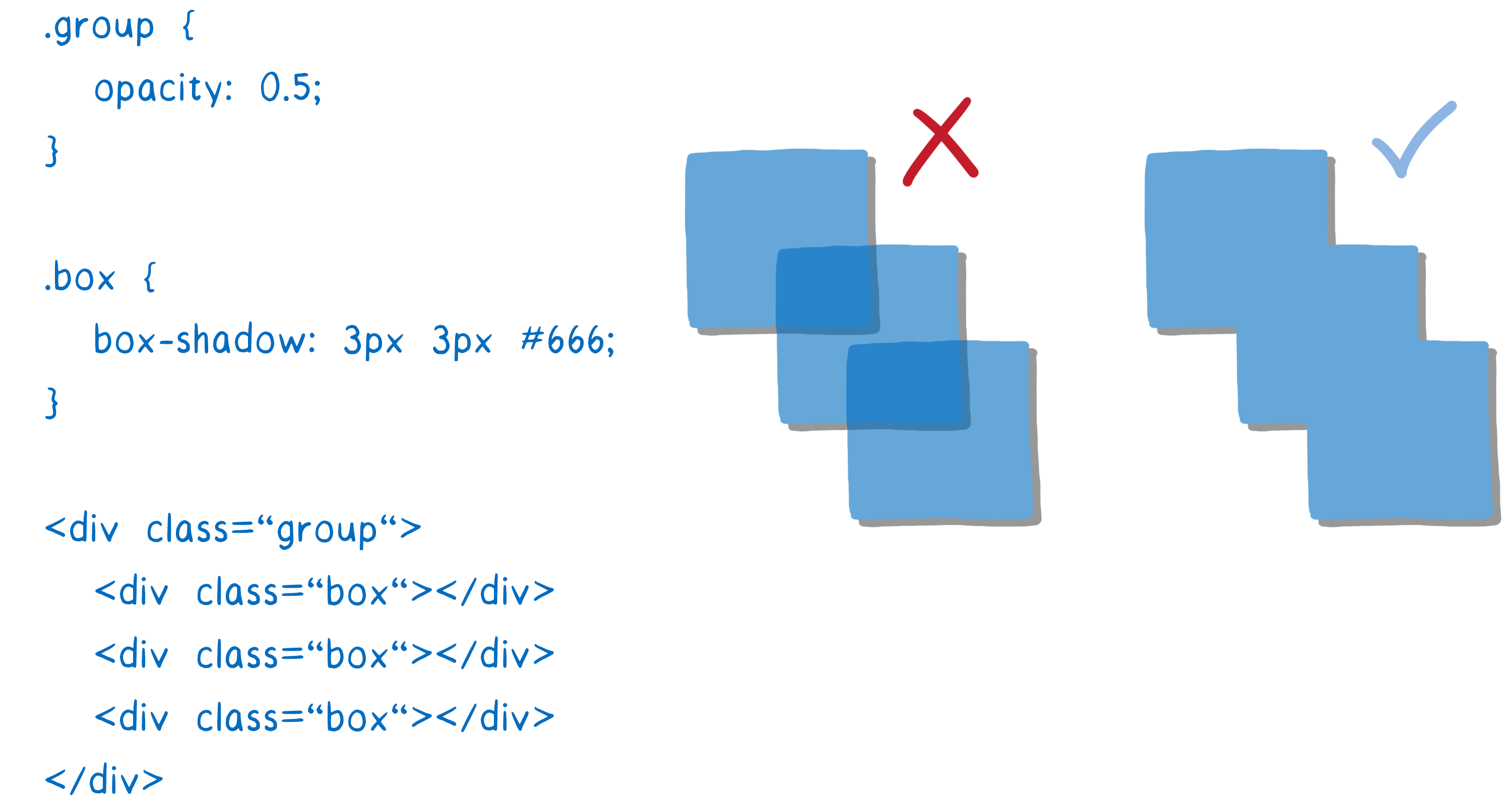
Because of this, you need to render the group out to a texture first, with each box at full opacity. Then, when you’re placing it in the parent, you can change the opacity of the whole texture.
These stacking contexts can be nested… that parent might be part of another stacking context. Which means it has to be rendered out to another intermediate texture, and so on.
Creating the space for these textures is expensive. As much as possible, we want to group things into the same intermediate texture.
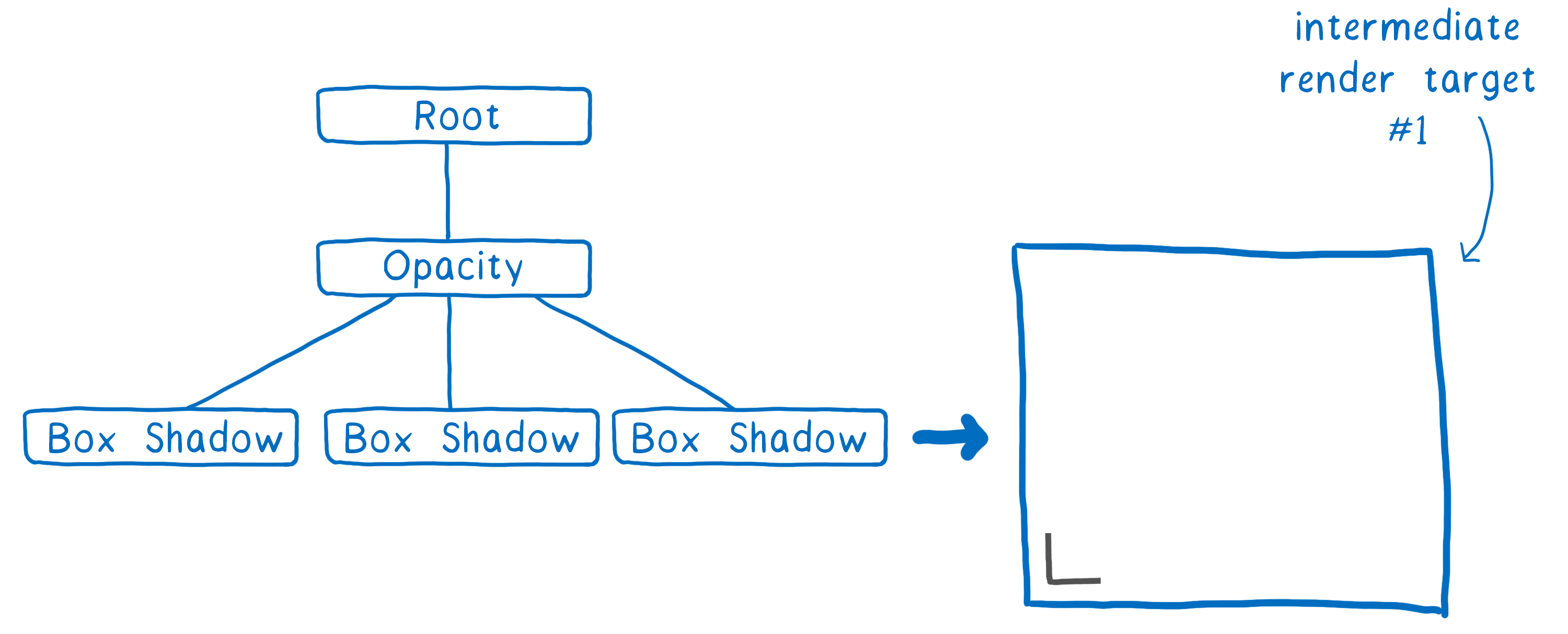
To help the GPU do this, we create a render task tree. With it, we know which textures need to be created before other textures. Any textures that don’t depend on others can be created in the first pass, which means they can be grouped together in the same intermediate texture.
So in the example above, we’d first do a pass to output one corner of a box shadow. (It’s slightly more complicated than this, but this is the gist.)
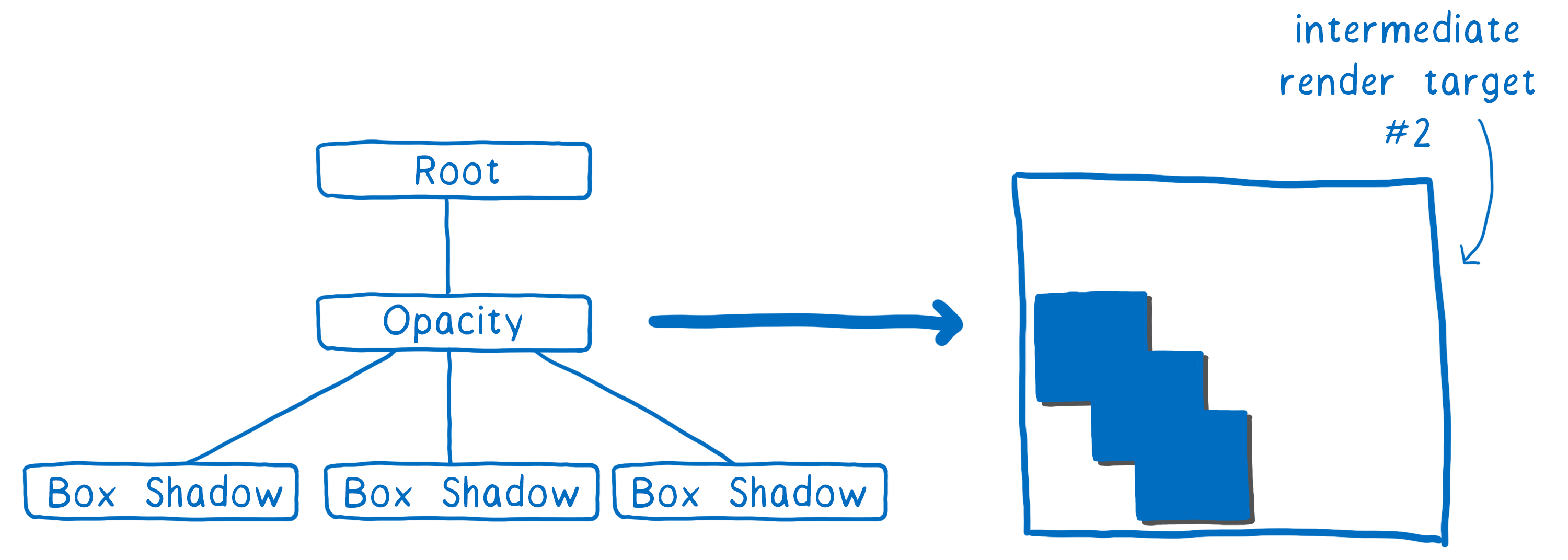
In the second pass, we can mirror this corner all around the box to place the box shadow on the boxes. Then we can render out the group at full opacity.
Next, all we need to do is change the opacity of this texture and place it where it needs to go in the final texture that will be output to the screen.
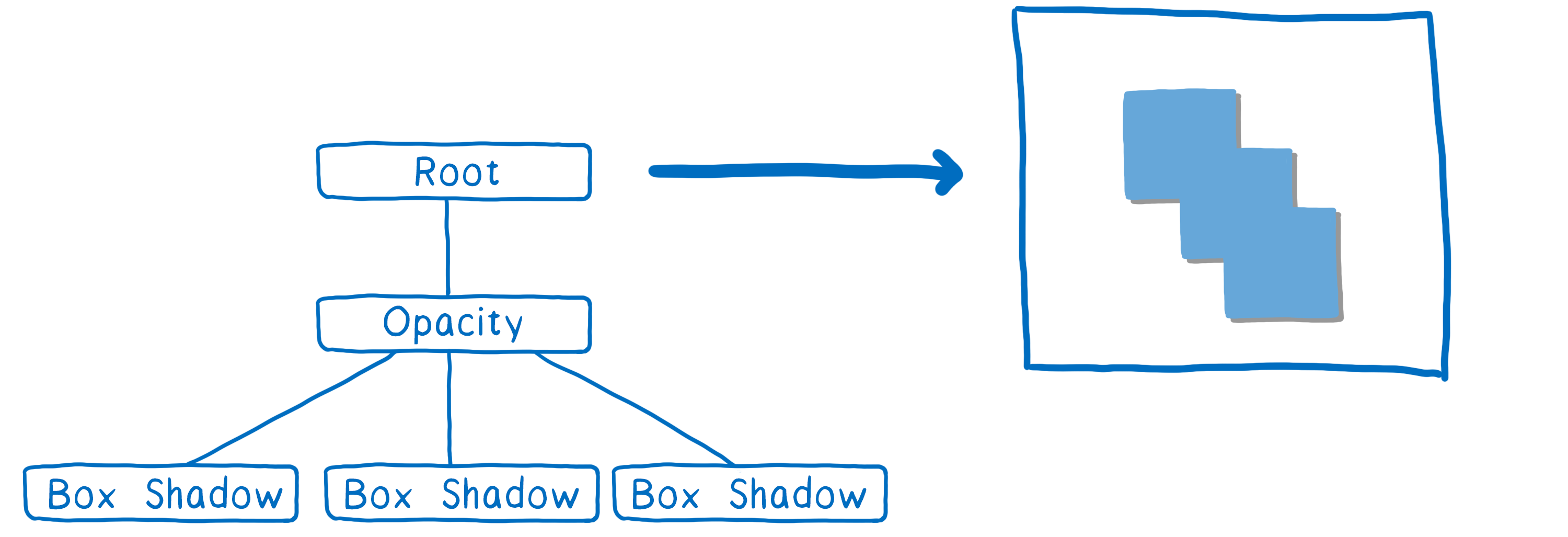
By building up this render task tree, we figure out the minimum number of offscreen render targets we can use. That’s good, because as I mentioned, creating the space for these render target textures is expensive.
It also helps us batch things together.
Grouping draw calls together (Batching)
As we talked about before, we need to create a small number of batches which have lots of shapes in them.
Paying attention to how you create batches can really speed things up. You want to have as many shapes in the same batch as you can. This is for a couple of reasons.
First, whenever the CPU tells the GPU to do a draw call, the CPU has to do a lot of work. It has to do things like set up the GPU, upload the shader program, and test for different hardware bugs. This work adds up, and while the CPU is doing this work, the GPU might be idle.
Second, there’s a cost to changing state. Let’s say that you need to change the shader program between batches. On a typical GPU, you need to wait until all of the cores are done with the current shader. This is called draining the pipeline. Until the pipeline is drained, other cores will be sitting idle.

Because of this, you want to batch as much as possible. For a typical desktop PC, you want to have 100 draw calls or fewer per frame, and you want each call to have thousands of vertices. That way, you’re making the best use of the parallelism.
We look at each pass from the render task tree and figure out what we can batch together.
At the moment, each of the different kinds of primitives requires a different shader. For example, there’s a border shader, and a text shader, and an image shader.
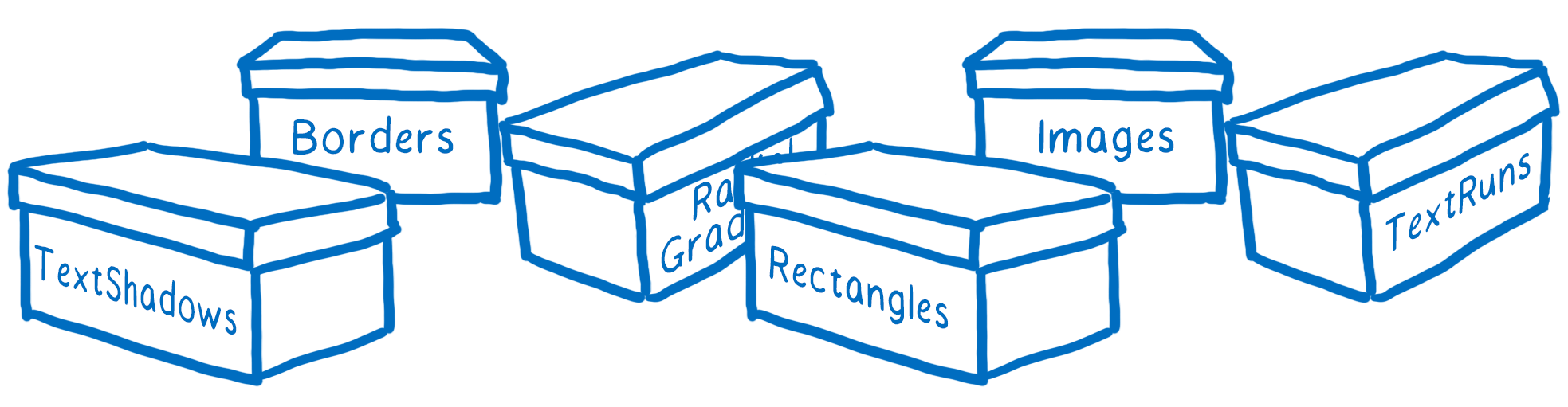
We believe we can combine a lot of these shaders, which will allow us to have even bigger batches, but this is already pretty well batched.
We’re almost ready to send it off to the GPU. But there’s a little bit more work we can eliminate.
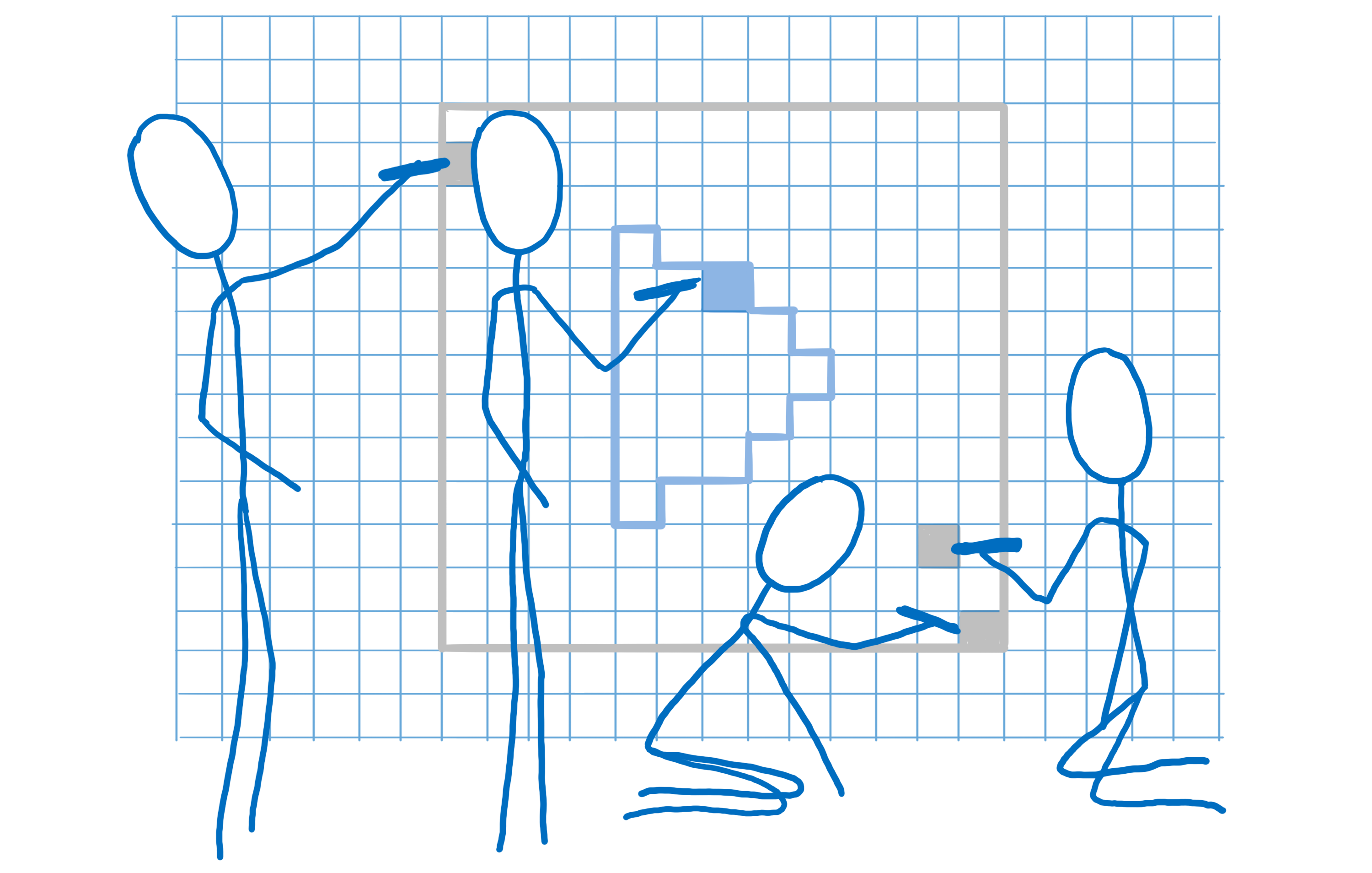
Reducing pixel shading with opaque and alpha passes (Z-culling)
Most web pages have lots of shapes overlapping each other. For example, a text field sits on top of a div (with a background) which sits on top of the body (with another background).
When it’s figuring out the color for a pixel, the GPU could figure out the color of the pixel in each shape. But only the top layer is going to show. This is called overdraw and it wastes GPU time.
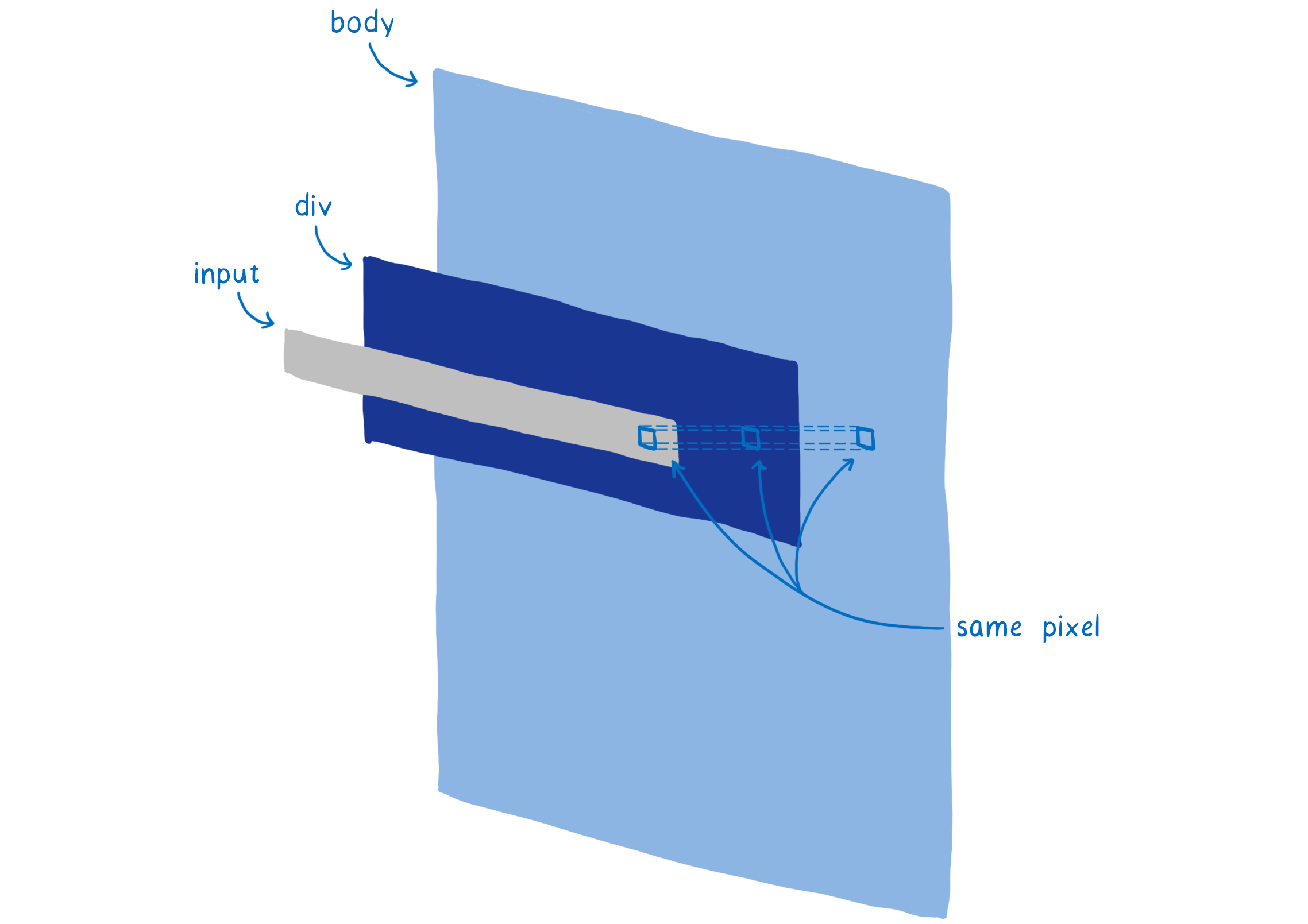
So one thing you could do is render the top shape first. For the next shape, when you get to that same pixel, check whether or not there’s already a value for it. If there is, then don’t do the work.

There’s a little bit of a problem with this, though. Whenever a shape is translucent, you need to blend the colors of the two shapes. And in order for it to look right, that needs to happen back to front.
So what we do is split the work into two passes. First, we do the opaque pass. We go front to back and render all of the opaque shapes. We skip any pixels that are behind others.
Then, we do the translucent shapes. These are rendered back to front. If a translucent pixel falls on top of an opaque one, it gets blended into the opaque one. If it would fall behind an opaque shape, it doesn’t get calculated.
This process of splitting the work into opaque and alpha passes and then skipping pixel calculations that you don’t need is called Z-culling.
While it may seem like a simple optimization, this has produced very big wins for us. On a typical web page, it vastly reduces the number of pixels that we need to touch, and we’re currently looking at ways to move more work to the opaque pass.
At this point, we’ve prepared the frame. We’ve done as much as we can to eliminate work.
… And we’re ready to draw!
We’re ready to setup the GPU and render our batches.

A caveat: not everything is on the GPU yet
The CPU still has to do some painting work. For example, we still render the characters (called glyphs) that are used in blocks of text on the CPU. It’s possible to do this on the GPU, but it’s hard to get a pixel-for-pixel match with the glyphs that the computer renders in other applications. So people can find it disorienting to see GPU-rendered fonts. We are experimenting with moving things like glyphs to the GPU with the Pathfinder project.
For now, these things get painted into bitmaps on the CPU. Then they are uploaded to something called the texture cache on the GPU. This cache is kept around from frame to frame because they usually don’t change.
Even though this painting work is staying on the CPU, we can still make it faster than it is now. For example, when we’re painting the characters in a font, we split up the different characters across all of the cores. We do this using the same technique that Stylo uses to parallelize style computation… work stealing.
What’s next for WebRender?
We look forward to landing WebRender in Firefox as part of Quantum Render in 2018, a few releases after the initial Firefox Quantum release. This will make today’s pages run more smoothly. It also gets Firefox ready for the new wave of high-resolution 4K displays, because rendering performance becomes more critical as you increase the number of pixels on the screen.
But WebRender isn’t just useful for Firefox. It’s also critical to the work we’re doing with WebVR, where you need to render a different frame for each eye at 90 FPS at 4K resolution.
An early version of WebRender is currently available behind a flag in Firefox. Integration work is still in progress, so the performance is currently not as good as it will be when that is complete. If you want to keep up with WebRender development, you can follow the GitHub repo, or follow Firefox Nightly on Twitter for weekly updates on the whole Quantum Render project.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
63 comments