
You may have heard of Project Quantum… it’s a major rewrite of Firefox’s internals to make Firefox fast. We’re swapping in parts from our experimental browser, Servo, and making massive improvements to other parts of the engine.
The project has been compared to replacing a jet engine while the jet is still in flight. We’re making the changes in place, component by component, so that you can see the effects in Firefox as soon as each component is ready.

And the first major component from Servo—a new CSS engine called Quantum CSS (previously known as Stylo)—is now available for testing in our Nightly version. You can make sure that it’s turned on for you by going to about:config and setting layout.css.servo.enabled to true.
This new engine brings together state-of-the-art innovations from four different browsers to create a new super CSS engine.

It takes advantage of modern hardware, parallelizing the work across all of the cores in your machine. This means it can run up to 2 or 4 or even 18 times faster.
On top of that, it combines existing state-of-the-art optimizations from other browsers. So even if it weren’t running in parallel, it would still be one fast CSS engine.

But what does the CSS engine do? First let’s look at the CSS engine and how it fits into the rest of the browser. Then we can look at how Quantum CSS makes it all faster.
What does the CSS engine do?
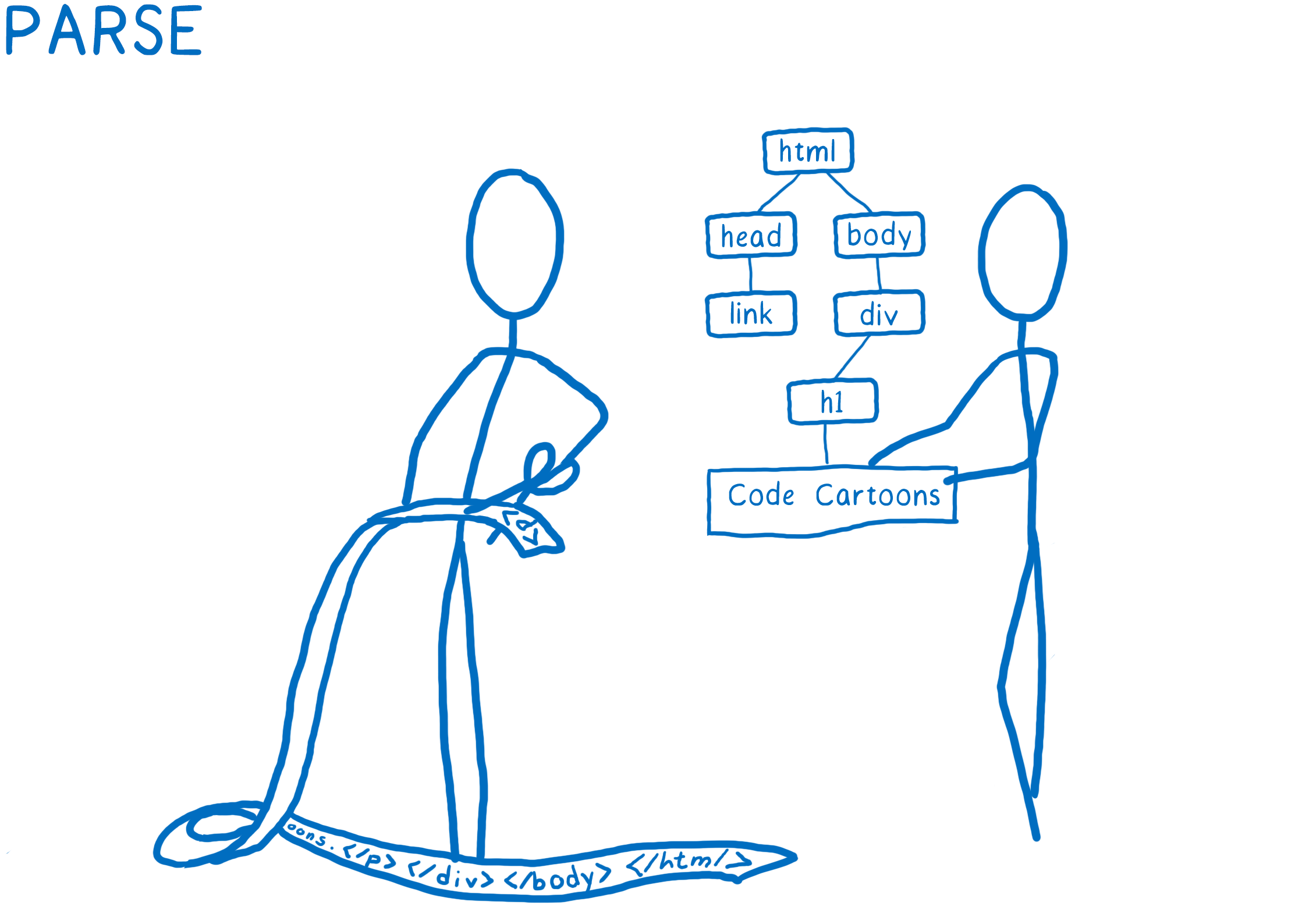
The CSS engine is part of the browser’s rendering engine. The rendering engine takes the website’s HTML and CSS files and turns them into pixels on the screen.

Each browser has a rendering engine. In Chrome, it’s called Blink. In Edge, it’s called EdgeHTML. In Safari, it’s called WebKit. And in Firefox, it’s called Gecko.
To get from files to pixels, all of these rendering engines basically do the same things:
- Parse the files into objects the browser can understand, including the DOM. At this point, the DOM knows about the structure of the page. It knows about parent/child relationships between elements. It doesn’t know what those elements should look like, though.
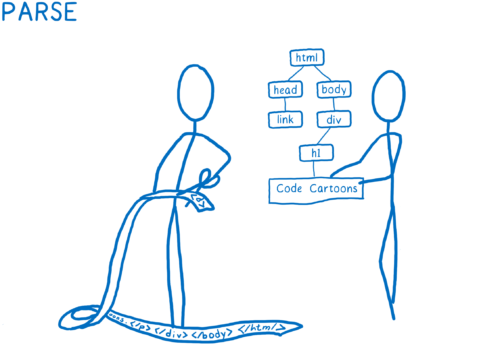
- Figure out what the elements should look like. For each DOM node, the CSS engine figures out which CSS rules apply. Then it figures out values for each CSS property for that DOM node.
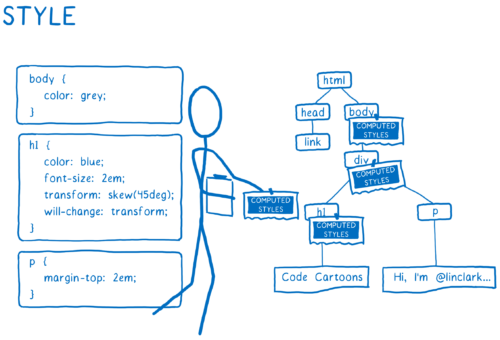
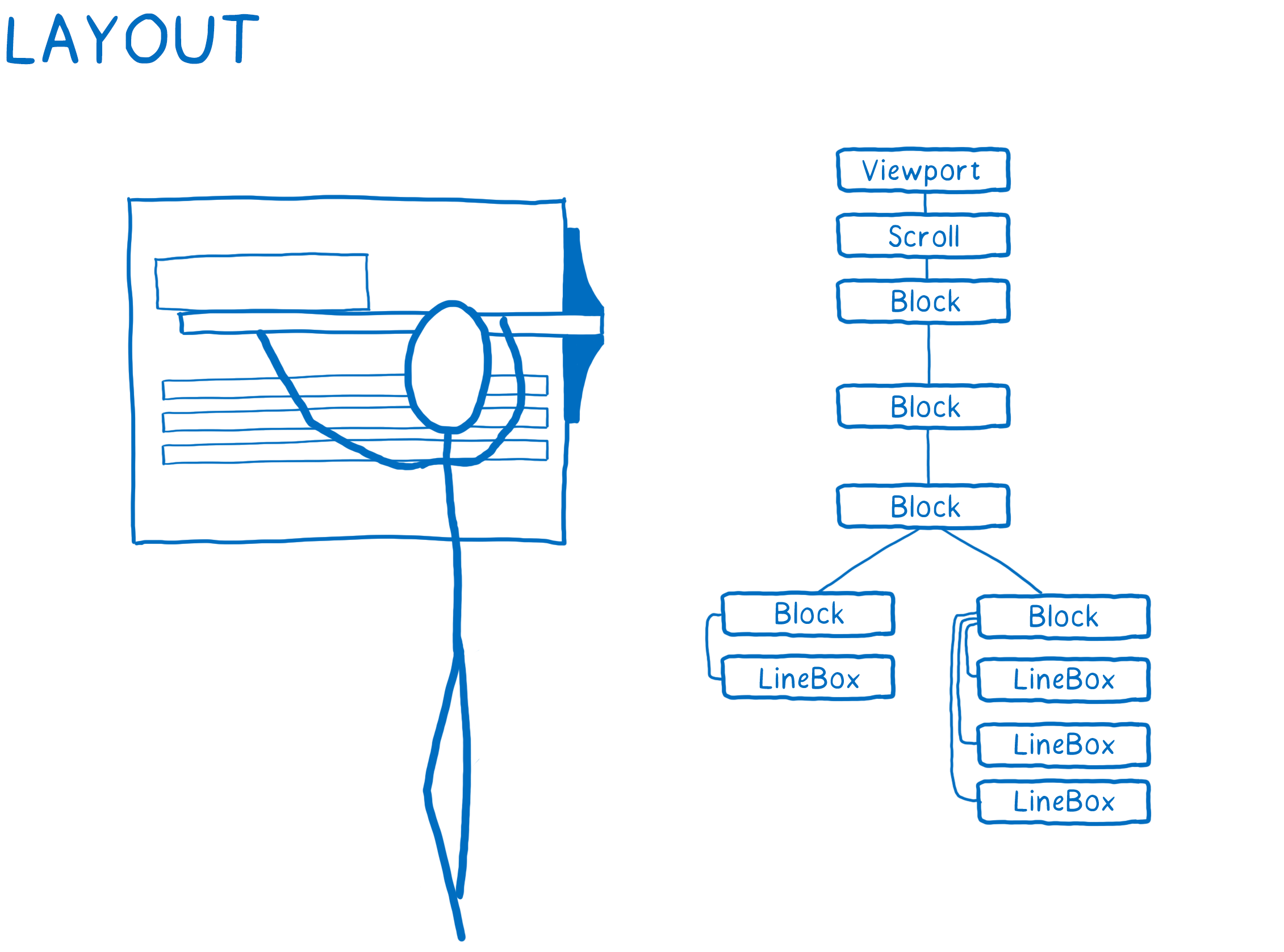
- Figure out dimensions for each node and where it goes on the screen. Boxes are created for each thing that will show up on the screen. The boxes don’t just represent DOM nodes… you will also have boxes for things inside the DOM nodes, like lines of text.
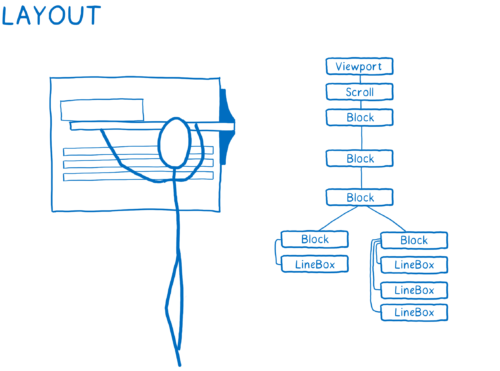
- Paint the different boxes. This can happen on multiple layers. I think of this like old-time hand drawn animation, with onionskin layers of paper. That makes it possible to just change one layer without having to repaint things on other layers.
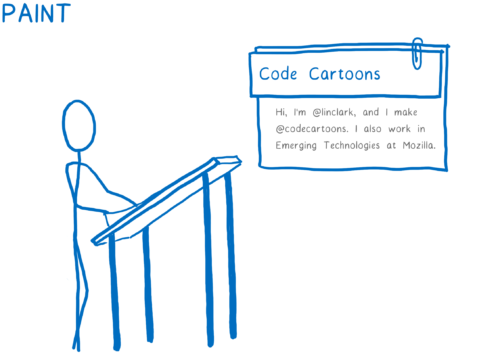
- Take those different painted layers, apply any compositor-only properties like transforms, and turn them into one image. This is basically like taking a picture of the layers stacked together. This image will then be rendered on the screen.



This means when it starts calculating the styles, the CSS engine has two things:
- a DOM tree
- a list of style rules
It goes through each DOM node, one by one, and figures out the styles for that DOM node. As part of this, it gives the DOM node a value for each and every CSS property, even if the stylesheets don’t declare a value for that property.
I think of it kind of like somebody going through and filling out a form. They need to fill out one of these forms for each DOM node. And for each form field, they need to have an answer.

To do this, the CSS engine needs to do two things:
- figure out which rules apply to the node — aka selector matching
- fill in any missing values with values from the parent or a default value—aka the cascade
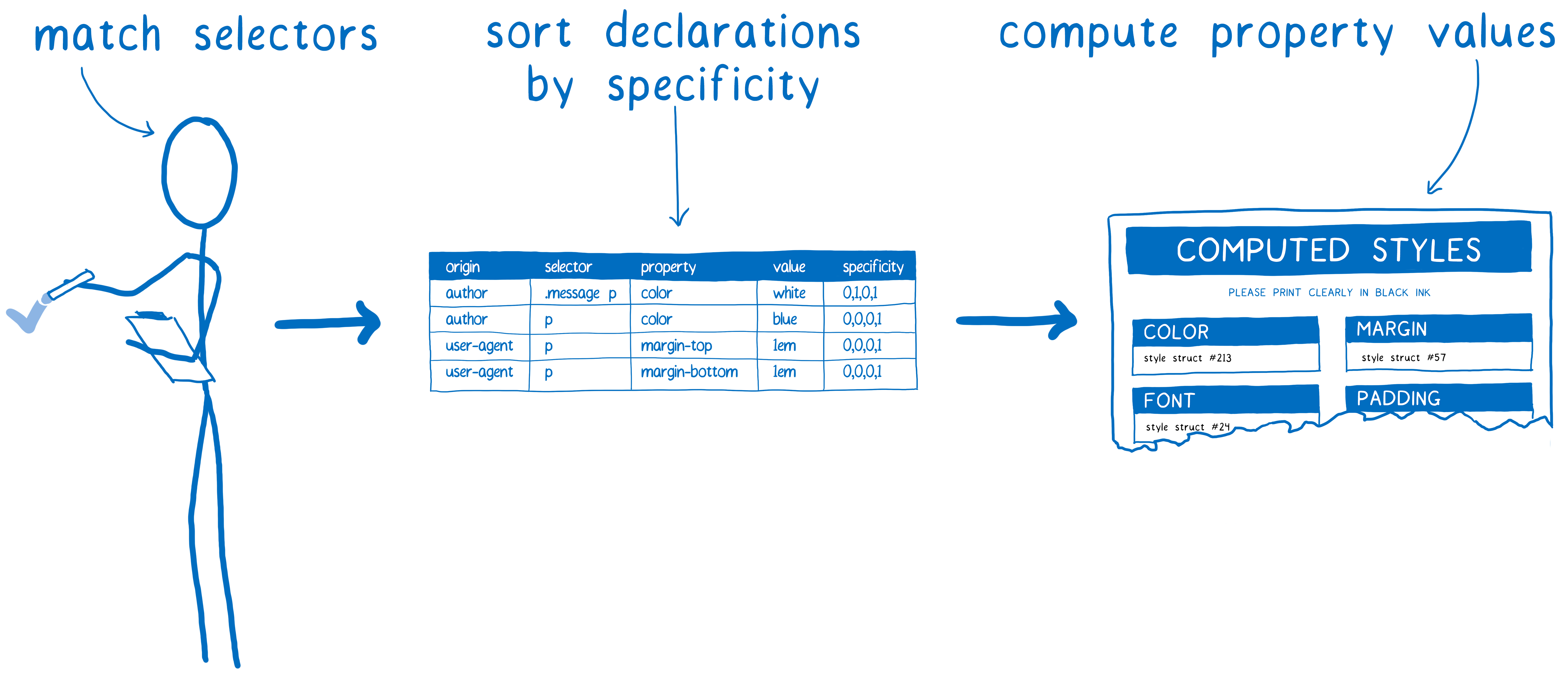
Selector matching
For this step, we’ll add any rule that matches the DOM node to a list. Because multiple rules can match, there may be multiple declarations for the same property.

Plus, the browser itself adds some default CSS (called user agent style sheets). How does the CSS engine know which value to pick?
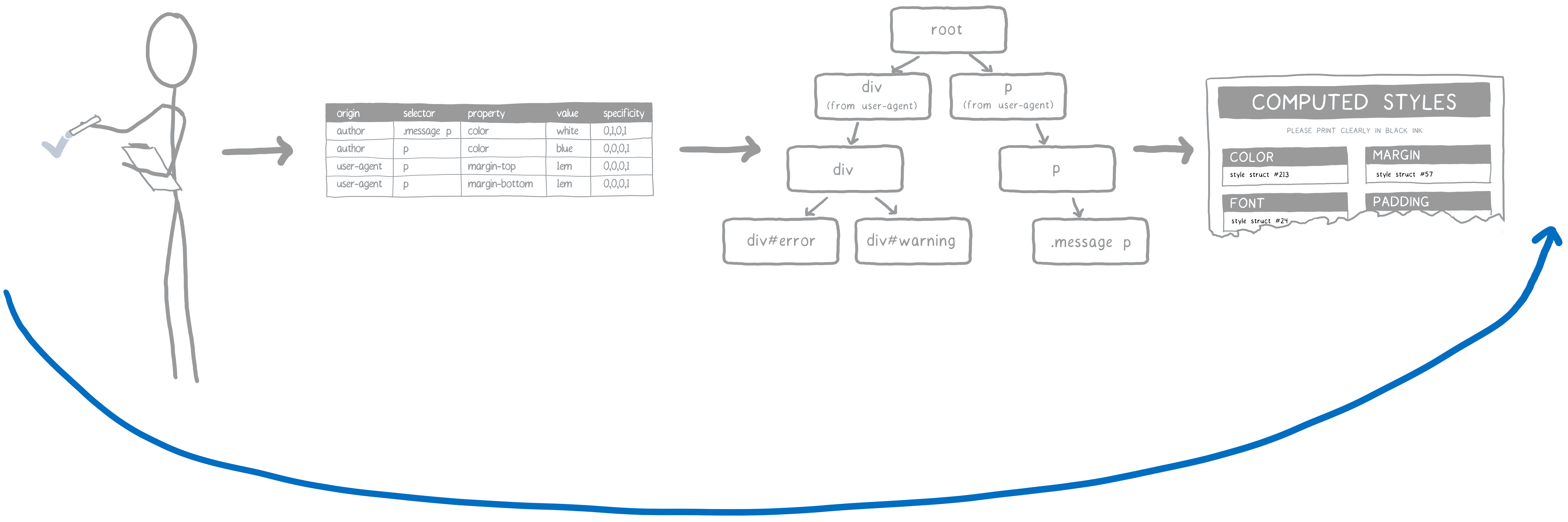
This is where specificity rules come in. The CSS engine basically creates a spreadsheet. Then it sorts the declarations based on different columns.

The rule that has the highest specificity wins. So based on this spreadsheet, the CSS engine fills out the values that it can.

For the rest, we’ll use the cascade.
The cascade
The cascade makes CSS easier to write and maintain. Because of the cascade, you can set the color property on the body and know that text in p, and span, and li elements will all use that color (unless you have a more specific override).
To do this, the CSS engine looks at the blank boxes on its form. If the property inherits by default, then the CSS engine walks up the tree to see if one of the ancestors has a value. If none of the ancestors have a value, or if the property does not inherit, it will get a default value.

So now all of the styles have been computed for this DOM node.
A sidenote: style struct sharing
The form that I’ve been showing you is a little misrepresentative. CSS has hundreds of properties. If the CSS engine held on to a value for each property for each DOM node, it would soon run out of memory.
Instead, engines usually do something called style struct sharing. They store data that usually goes together (like font properties) in a different object called a style struct. Then, instead of having all of the properties in the same object, the computed styles object just has pointers. For each category, there’s a pointer to the style struct that has the right values for this DOM node.

This ends up saving both memory and time. Nodes that have similar properties (like siblings) can just point to the same structs for the properties they share. And because many properties are inherited, an ancestor can share a struct with any descendants that don’t specify their own overrides.
Now, how do we make that fast?
So that is what style computation looks like when you haven’t optimized it.
There’s a lot of work happening here. And it doesn’t just need to happen on the first page load. It happens over and over again as users interact with the page, hovering over elements or making changes to the DOM, triggering a restyle.

This means that CSS style computation is a great candidate for optimization… and browsers have been testing out different strategies to optimize it for the past 20 years. What Quantum CSS does is take the best of these strategies from different engines and combine them to create a superfast new engine.
So let’s look at the details of how these all work together.
Run it all in parallel
The Servo project (which Quantum CSS comes from) is an experimental browser that’s trying to parallelize all of the different parts of rendering a web page. What does that mean?
A computer is like a brain. There’s a part that does the thinking (the ALU). Near that, there’s some short term memory (the registers). These are grouped together on the CPU. Then there’s longer term memory, which is RAM.

Early computers could only think one thing at a time using this CPU. But over the last decade, CPUs have shifted to having multiple ALUs and registers, grouped together in cores. This means that the CPU can think multiple things at once — in parallel.

Quantum CSS makes use of this recent feature of computers by splitting up style computation for the different DOM nodes across the different cores.
This might seem like an easy thing to do… just split up the branches of the tree and do them on different cores. It’s actually much harder than that for a few reasons. One reason is that DOM trees are often uneven. That means that one core will have a lot more work to do than others.

To balance the work more evenly, Quantum CSS uses a technique called work stealing. When a DOM node is being processed, the code takes its direct children and splits them up into 1 or more “work units”. These work units get put into a queue.
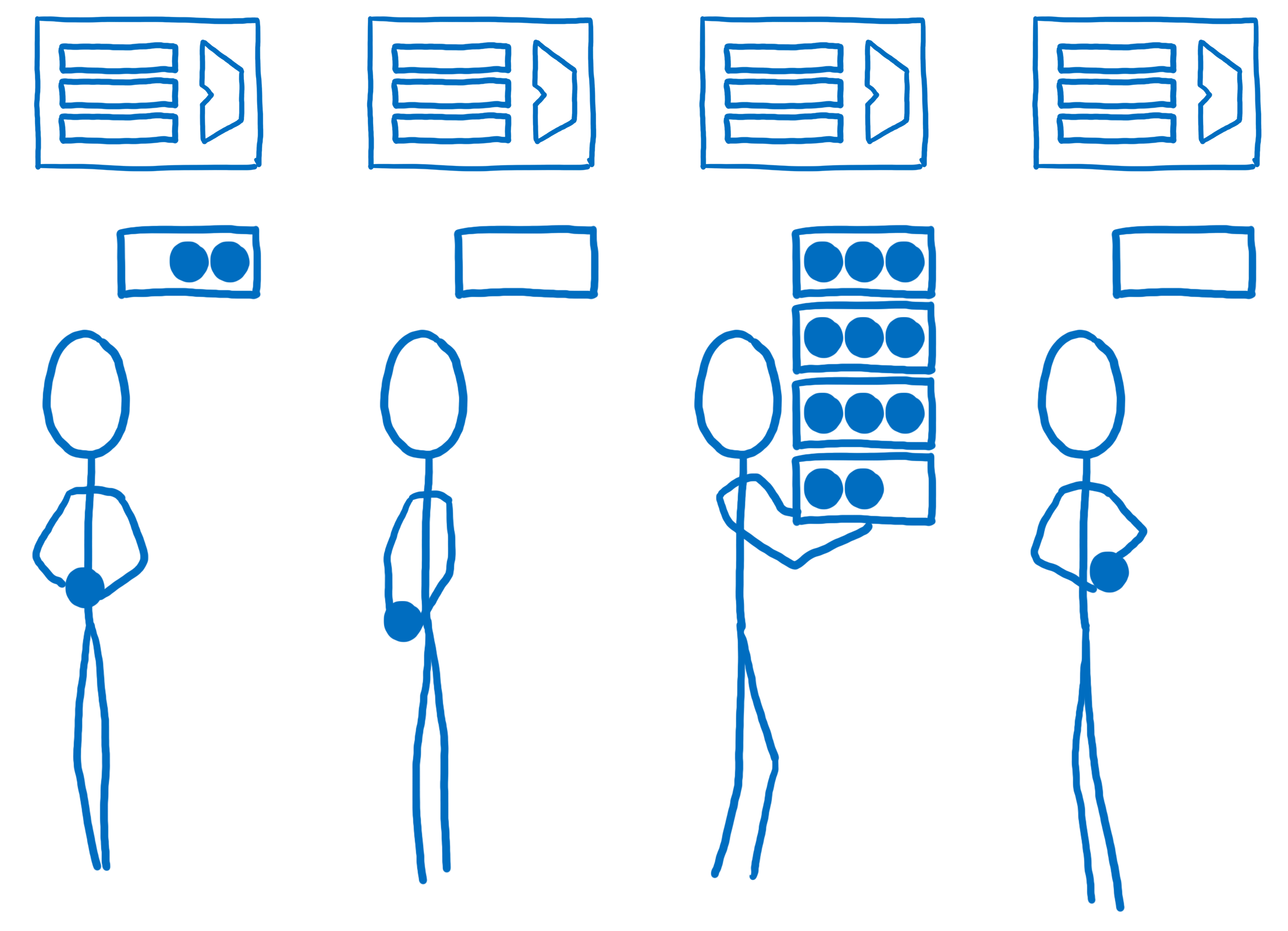
When one core is done with the work in its queue, it can look in the other queues to find more work to do. This means we can evenly divide the work without taking time up front to walk the tree and figure out how to balance it ahead of time.

In most browsers, it would be hard to get this right. Parallelism is a known hard problem, and the CSS engine is very complex. It’s also sitting between the two other most complex parts of the rendering engine — the DOM and layout. So it would be easy to introduce a bug, and parallelism can result in bugs that are very hard to track down, called data races. I explain more about these kinds of bugs in another article.
If you’re accepting contributions from hundreds or thousands of engineers, how can you program in parallel without fear? That’s what we have Rust for.

With Rust, you can statically verify that you don’t have data races. This means you avoid tricky-to-debug bugs by just not letting them into your code in the first place. The compiler won’t let you do it. I’ll be writing more about this in a future article. In the meantime, you can watch this intro video about parallelism in Rust or this more in-depth talk about work stealing.
With this, CSS style computation becomes what’s called an embarrassingly parallel problem — there’s very little keeping you from running it efficiently in parallel. This means that we can get close to linear speed ups. If you have 4 cores on your machine, then it will run close to 4 times faster.
Speed up restyles with the Rule Tree
For each DOM node, the CSS engine needs to go through all of the rules to do selector matching. For most nodes, this matching likely won’t change very often. For example, if the user hovers over a parent, the rules that match it may change. We still need to recompute style for its descendants to handle property inheritance, but the rules that match those descendants probably won’t change.
It would be nice if we could just make a note of which rules match those descendants so we don’t have to do selector matching for them again… and that’s what the rule tree—borrowed from Firefox’s previous CSS engine— does.
The CSS engine will go through the process of figuring out the selectors that match, and then sorting them by specificity. From this, it creates a linked list of rules.
This list is going to be added to the tree.

The CSS engine tries to keep the number of branches in the tree to a minimum. To do this, it will try to reuse a branch wherever it can.
If most of the selectors in the list are the same as an existing branch, then it will follow the same path. But it might reach a point where the next rule in the list isn’t in this branch of the tree. Only at that point will it add a new branch.

The DOM node will get a pointer to the rule that was inserted last (in this example, the div#warning rule). This is the most specific one.
On restyle, the engine does a quick check to see whether the change to the parent could potentially change the rules that match children. If not, then for any descendants, the engine can just follow the pointer on the descendant node to get to that rule. From there, it can follow the tree back up to the root to get the full list of matching rules, from most specific to least specific. This means it can skip selector matching and sorting completely.

So this helps reduce the work needed during restyle. But it’s still a lot of work during initial styling. If you have 10,000 nodes, you still need to do selector matching 10,000 times. But there’s another way to speed that up.
Speed up initial render (and the cascade) with the style sharing cache
Think about a page with thousands of nodes. Many of those nodes will match the same rules. For example, think of a long Wikipedia page… the paragraphs in the main content area should all end up matching the exact same rules, and have the exact same computed styles.
If there’s no optimization, then the CSS engine has to match selectors and compute styles for each paragraph individually. But if there was a way to prove that the styles will be the same from paragraph to paragraph, then the engine could just do that work once and point each paragraph node to the same computed style.
That’s what the style sharing cache—inspired by Safari and Chrome—does. After it’s done processing a node, it puts the computed style into the cache. Then, before it starts computing styles on the next node, it runs a few checks to see whether it can use something from the cache.
Those checks are:
- Do the 2 nodes have the same ids, classes, etc? If so, then they would match the same rules.
- For anything that isn’t selector based—inline styles, for example—do the nodes have the same values? If so, then the rules from above either won’t be overridden, or will be overridden in the same way.
- Do both parents point to the same computed style object? If so, then the inherited values will also be the same.

Those checks have been in earlier style sharing caches since the beginning. But there are a lot of other little cases where styles might not match. For example, if a CSS rule uses the :first-child selector, then two paragraphs might not match, even though the checks above suggest that they should.
In WebKit and Blink, the style sharing cache would give up in these cases and not use the cache. As more sites use these modern selectors, the optimization was becoming less and less useful, so the Blink team recently removed it. But it turns out there is a way for the style sharing cache to keep up with these changes.
In Quantum CSS, we gather up all of those weird selectors and check whether they apply to the DOM node. Then we store the answers as ones and zeros. If the two elements have the same ones and zeros, we know they definitely match.

If a DOM node can share styles that have already been computed, you can skip pretty much all of the work. Because pages often have many DOM nodes with the same styles, this style sharing cache can save on memory and also really speed things up.
Conclusion
This is the first big technology transfer of Servo tech to Firefox. Along the way, we’ve learned a lot about how to bring modern, high-performance code written in Rust into the core of Firefox.
We’re very excited to have this big chunk of Project Quantum ready for users to experience first-hand. We’d be happy to have you try it out, and let us know if you find any issues.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
52 comments