
In 2017, the toolbox for making sure your web page loads fast includes everything from minification and asset optimization to caching, CDNs, code splitting and tree shaking. However, you can get big performance boosts with just a few keywords and mindful code structuring, even if you’re not yet familiar with the concepts above and you’re not sure how to get started.
The fresh web standard <link rel="preload">, that allows you to load critical resources faster, is coming to Firefox later this month. You can already try it out in Firefox Nightly or Developer Edition, and in the meantime, this is a great chance to review some fundamentals and dive deeper into performance associated with parsing the DOM.
Understanding what goes on inside a browser is the most powerful tool for every web developer. We’ll look at how browsers interpret your code and how they help you load pages faster with speculative parsing. We’ll break down how defer and async work and how you can leverage the new keyword preload.
Building blocks
HTML describes the structure of a web page. To make any sense of the HTML, browsers first have to convert it into a format they understand – the Document Object Model, or DOM. Browser engines have a special piece of code called a parser that’s used to convert data from one format to another. An HTML parser converts data from HTML into the DOM.
In HTML, nesting defines the parent-child relationships between different tags. In the DOM, objects are linked in a tree data structure capturing those relationships. Each HTML tag is represented by a node of the tree (a DOM node).
The browser builds up the DOM bit by bit. As soon as the first chunks of code come in, it starts parsing the HTML, adding nodes to the tree structure.

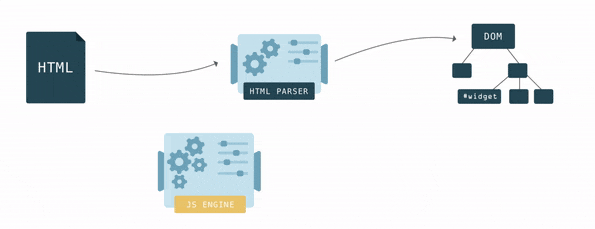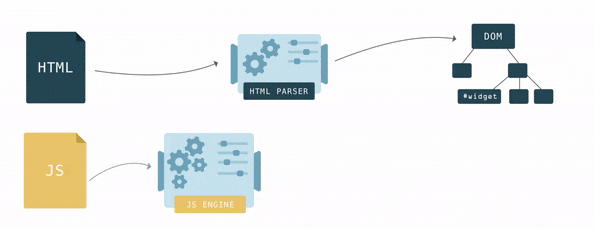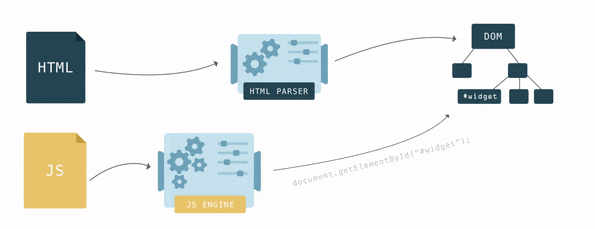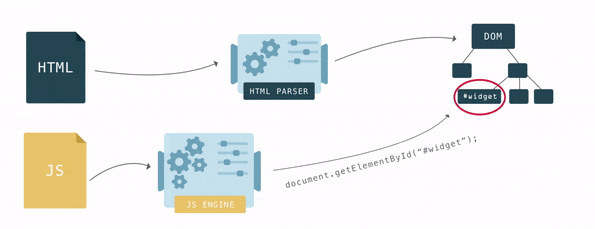
The DOM has two roles: it is the object representation of the HTML document, and it acts as an interface connecting the page to the outside world, like JavaScript. When you call document.getElementById(), the element that is returned is a DOM node. Each DOM node has many functions you can use to access and change it, and what the user sees changes accordingly.
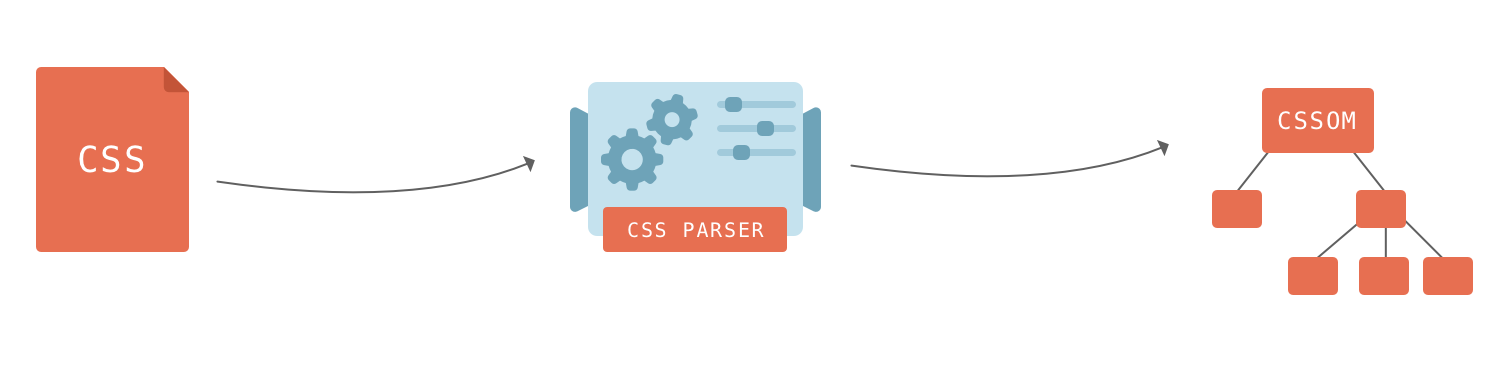
CSS styles found on a web page are mapped onto the CSSOM – the CSS Object Model. It is much like the DOM, but for the CSS rather than the HTML. Unlike the DOM, it cannot be built incrementally. Because CSS rules can override each other, the browser engine has to do complex calculations to figure out how the CSS code applies to the DOM.
The history of the <script> tag
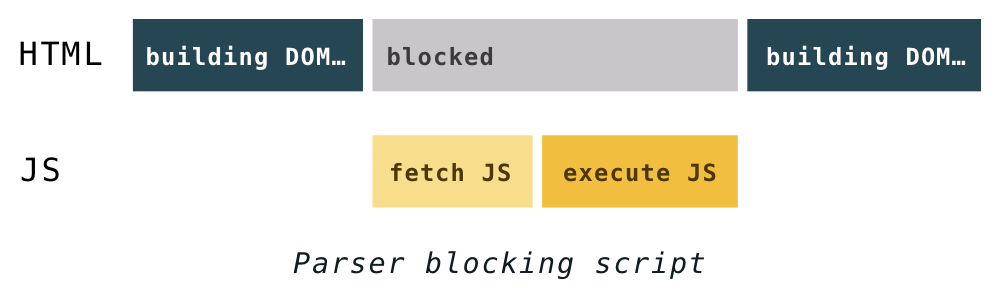
As the browser is constructing the DOM, if it comes across a <script>...</script> tag in the HTML, it must execute it right away. If the script is external, it has to download the script first.
Back in the old days, in order to execute a script, parsing had to be paused. It would only start up again after the JavaScript engine had executed code from a script.
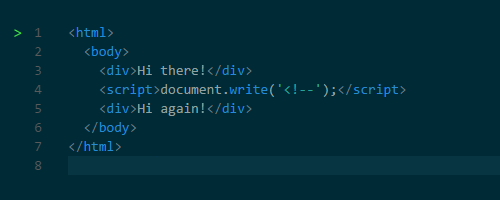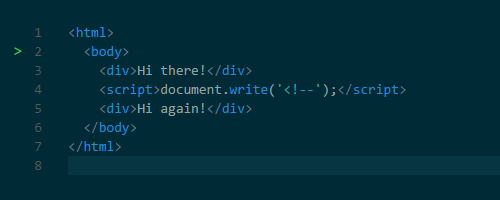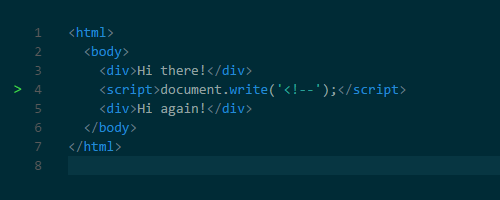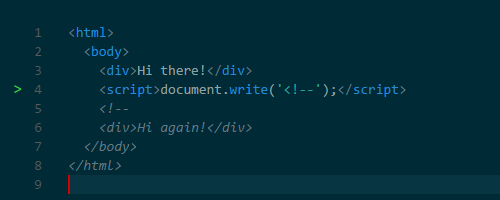
Why did the parsing have to stop? Well, scripts can change both the HTML and its product―the DOM. Scripts can change the DOM structure by adding nodes with document.createElement(). To change the HTML, scripts can add content with the notorious document.write() function. It’s notorious because it can change the HTML in ways that can affect further parsing. For example, the function could insert an opening comment tag making the rest of the HTML invalid.
Scripts can also query something about the DOM, and if that happens while the DOM is still being constructed, it could return unexpected results.
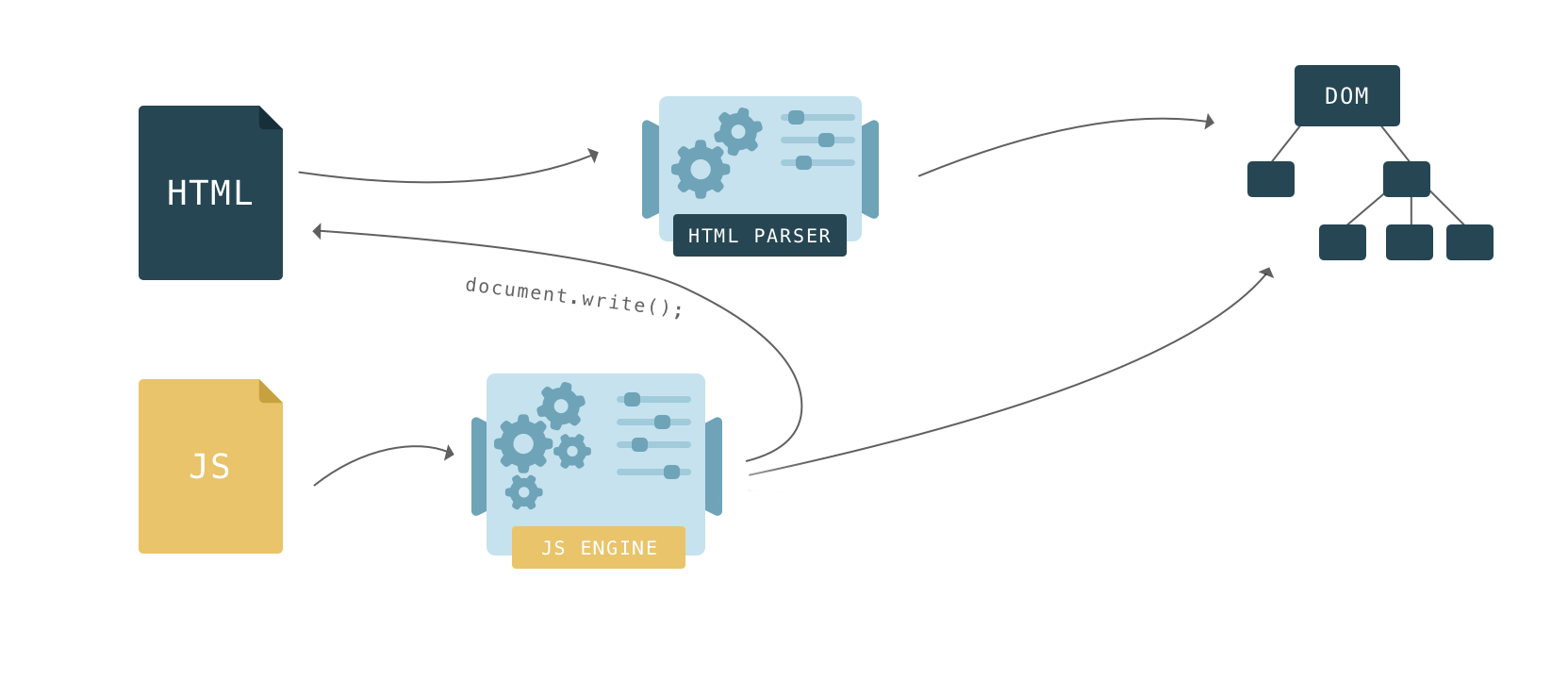
document.write() is a legacy function that can break your page in unexpected ways and you shouldn’t use it, even though browsers still support it. For these reasons, browsers have developed sophisticated techniques to get around the performance issues caused by script blocking that I will explain shortly.
What about CSS?
JavaScript blocks parsing because it can modify the document. CSS can’t modify the document, so it seems like there is no reason for it to block parsing, right?
However, what if a script asks for style information that hasn’t been parsed yet? The browser doesn’t know what the script is about to execute—it may ask for something like the DOM node’s background-color which depends on the style sheet, or it may expect to access the CSSOM directly.
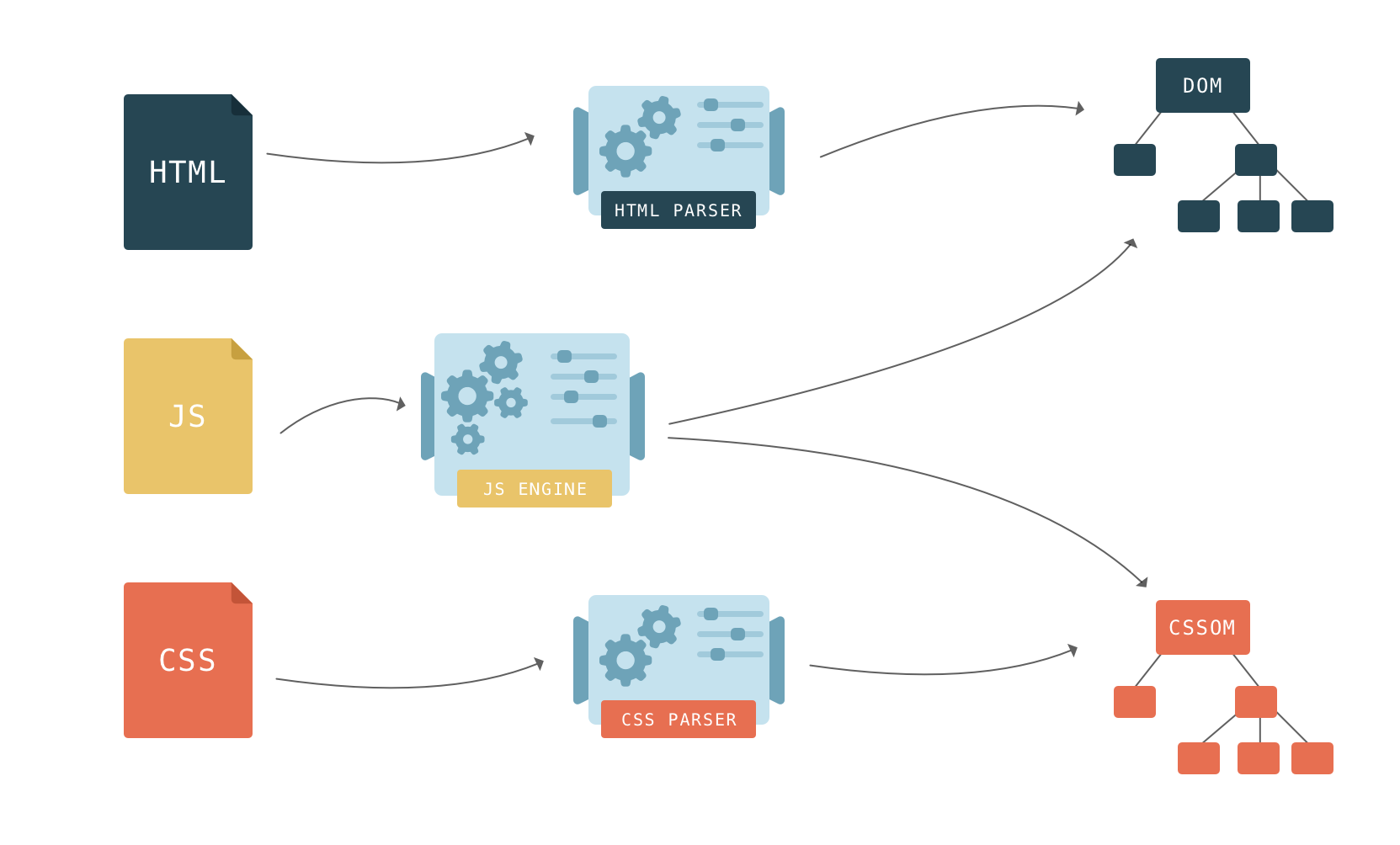
Because of this, CSS may block parsing depending on the order of external style sheets and scripts in the document. If there are external style sheets placed before scripts in the document, the construction of DOM and CSSOM objects can interfere with each other. When the parser gets to a script tag, DOM construction cannot proceed until the JavaScript finishes executing, and the JavaScript cannot be executed until the CSS is downloaded, parsed, and the CSSOM is available.
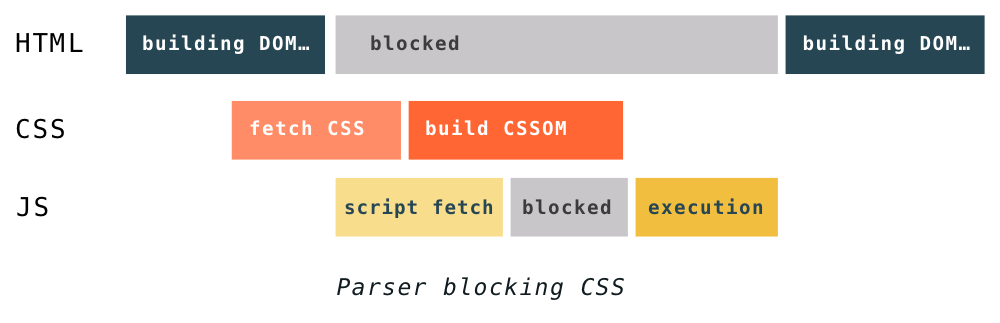
Another thing to keep in mind is that even if the CSS doesn’t block DOM construction, it blocks rendering. The browser won’t display anything until it has both the DOM and the CSSOM. This is because pages without CSS are often unusable. If a browser showed you a messy page without CSS, then a few moments later snapped into a styled page, the shifting content and sudden visual changes would make a turbulent user experience.
That poor user experience has a name – Flash of Unstyled Content or FOUC
To get around these issues, you should aim to deliver the CSS as soon as possible. Recall the popular “styles at the top, scripts at the bottom” best practice? Now you know why it was there!
Back to the future – speculative parsing
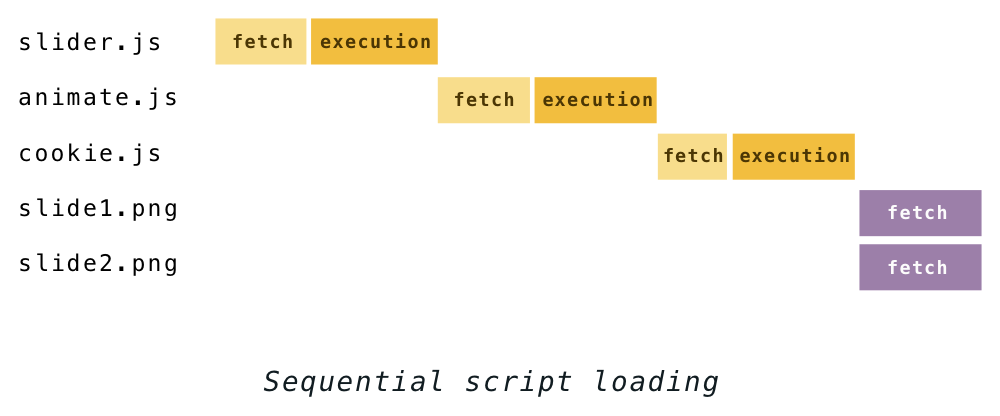
Pausing the parser whenever a script is encountered means that every script you load delays the discovery of the rest of the resources that were linked in the HTML.
If you have a few scripts and images to load, for example–
<script src="slider.js"></script>
<script src="animate.js"></script>
<script src="cookie.js"></script>
<img src="slide1.png">
<img src="slide2.png">–the process used to go like this:
That changed around 2008 when IE introduced something they called “the lookahead downloader”. It was a way to keep downloading the files that were needed while the synchronous script was being executed. Firefox, Chrome and Safari soon followed, and today most browsers use this technique under different names. Chrome and Safari have “the preload scanner” and Firefox – the speculative parser.
The idea is: even though it’s not safe to build the DOM while executing a script, you can still parse the HTML to see what other resources need to be retrieved. Discovered files are added to a list and start downloading in the background on parallel connections. By the time the script finishes executing, the files may have already been downloaded.
The waterfall chart for the example above now looks more like this:
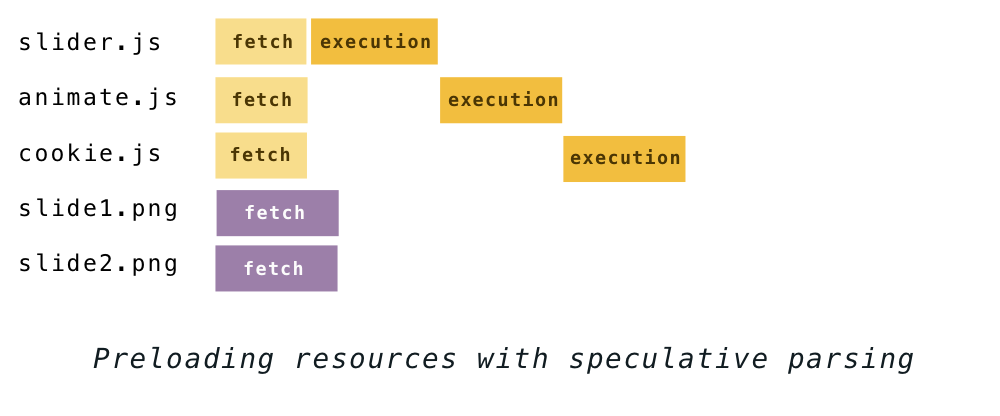
The download requests triggered this way are called “speculative” because it is still possible that the script could change the HTML structure (remember document.write ?), resulting in wasted guesswork. While this is possible, it is not common, and that’s why speculative parsing still gives big performance improvements.
While other browsers only preload linked resources this way, in Firefox the HTML parser also runs the DOM tree construction algorithm speculatively. The upside is that when a speculation succeeds, there’s no need to re-parse a part of the file to actually compose the DOM. The downside is that there’s more work lost if and when the speculation fails.
(Pre)loading stuff
This manner of resource loading delivers a significant performance boost, and you don’t need to do anything special to take advantage of it. However, as a web developer, knowing how speculative parsing works can help you get the most out of it.
The set of things that can be preloaded varies between browsers. All major browsers preload:
- scripts
- external CSS
- and images from the
<img>tag
Firefox also preloads the poster attribute of video elements, while Chrome and Safari preload @import rules from inlined styles.
There are limits to how many files a browser can download in parallel. The limits vary between browsers and depend on many factors, like whether you’re downloading all files from one or from several different servers and whether you are using HTTP/1.1 or HTTP/2 protocol. To render the page as quickly as possible, browsers optimize downloads by assigning priority to each file. To figure out these priorities, they follow complex schemes based on resource type, position in the markup, and progress of the page rendering.
While doing speculative parsing, the browser does not execute inline JavaScript blocks. This means that it won’t discover any script-injected resources, and those will likely be last in line in the fetching queue.
var script = document.createElement('script');
script.src = "//somehost.com/widget.js";
document.getElementsByTagName('head')[0].appendChild(script);You should make it easy for the browser to access important resources as soon as possible. You can either put them in HTML tags or include the loading script inline and early in the document. However, sometimes you want some resources to load later because they are less important. In that case, you can hide them from the speculative parser by loading them with JavaScript late in the document.
You can also check out this MDN guide on how to optimize your pages for speculative parsing.
defer and async
Still, synchronous scripts blocking the parser remains an issue. And not all scripts are equally important for the user experience, such as those for tracking and analytics. Solution? Make it possible to load these less important scripts asynchronously.
The defer and async attributes were introduced to give developers a way to tell the browser which scripts to handle asynchronously.
Both of these attributes tell the browser that it may go on parsing the HTML while loading the script “in background”, and then execute the script after it loads. This way, script downloads don’t block DOM construction and page rendering. Result: the user can see the page before all scripts have finished loading.
The difference between defer and async is which moment they start executing the scripts.
defer was introduced before async. Its execution starts after parsing is completely finished, but before the DOMContentLoaded event. It guarantees scripts will be executed in the order they appear in the HTML and will not block the parser.

async scripts execute at the first opportunity after they finish downloading and before the window’s load event. This means it’s possible (and likely) that async scripts are not executed in the order in which they appear in the HTML. It also means they can interrupt DOM building.
Wherever they are specified, async scripts load at a low priority. They often load after all other scripts, without blocking DOM building. However, if an async script finishes downloading sooner, its execution can block DOM building and all synchronous scripts that finish downloading afterwards.

Note: Attributes async and defer work only for external scripts. They are ignored if there’s no src.
preload
async and defer are great if you want to put off handling some scripts, but what about stuff on your web page that’s critical for user experience? Speculative parsers are handy, but they preload only a handful of resource types and follow their own logic. The general goal is to deliver CSS first because it blocks rendering. Synchronous scripts will always have higher priority than asynchronous. Images visible within the viewport should be downloaded before those below the fold. And there are also fonts, videos, SVGs… In short – it’s complicated.
As an author, you know which resources are the most important for rendering your page. Some of them are often buried in CSS or scripts and it can take the browser quite a while before it even discovers them. For those important resources you can now use <link rel="preload"> to communicate to the browser that you want to load them as soon as possible.
All you need to write is:
<link rel="preload" href="very_important.js" as="script">You can link pretty much anything and the as attribute tells the browser what it will be downloading. Some of the possible values are:
scriptstyleimagefontaudiovideo
You can check out the rest of the content types on MDN.
Fonts are probably the most important thing that gets hidden in the CSS. They are critical for rendering the text on the page, but they don’t get loaded until browser is sure that they are going to be used. That check happens only after CSS has been parsed, and applied, and the browser has matched CSS rules to the DOM nodes. This happens fairly late in the page loading process and it often results in an unnecessary delay in text rendering. You can avoid it by using the preload attribute when you link fonts.
One thing to pay attention to when preloading fonts is that you also have to set the <a href="https://developer.mozilla.org/en-US/docs/Web/HTTP/Access_control_CORS" target="_blank" rel="noopener">crossorigin</a> attribute even if the font is on the same domain:
<link rel="preload" href="font.woff" as="font" crossorigin>The preload feature has limited support at the moment as the browsers are still rolling it out, but you can check the progress here.
Conclusion
Browsers are complex beasts that have been evolving since the 90s. We’ve covered some of the quirks from that legacy and some of the newest standards in web development. Writing your code with these guidelines will help you pick the best strategies for delivering a smooth browsing experience.
If you’re excited to learn more about how browsers work here are some other Hacks posts you should check out:
Quantum Up Close: What is a browser engine?
Inside a super fast CSS engine: Quantum CSS (aka Stylo)
30 comments