
Background: SIMD.js
Single-Instruction-Multiple-Data (SIMD) is a technique used in modern processors to exploit data level parallelism. SIMD introduces wide vectors that can hold multiple data elements. Once loaded, all of the vector’s elements can be processed simultaneously using one vector operation. This brings the advantages of better performance and energy efficiency. The parallelism offered by SIMD can be used in a range of applications including scientific computing, signal processing, and 3D graphics. As the web has evolved to become a platform capable of supporting these applications, SIMD has become a very desirable feature.
SIMD.js is a JavaScript API which exposes web applications to the SIMD capabilities found in processors. It is being developed by Google, Intel, Mozilla, and Microsoft. Introducing SIMD.js is a good read for more information.
glMatrix Vectorization
Vectorization is the process of preparing programs to use SIMD vector operations. Matrix computations are a type of application that can take advantage of vectorization. Matrix math is extensively used in JavaScript to support WebGL apps and high performance applications such as physics simulation and image processing. gl-matrix is a fast matrix and vector math library for JavaScript. It offers numerous functions for processing square matrices and vectors.
In our work at Mozilla Research, we contributed to the gl-matrix by vectorizing mat4 functions which operate on four-by-four matrices. Mat4 functions are the right choice for vectorization, because they are among the most computationally intensive functions and are being heavily used in 3D graphics applications, in which computations have to be done repeatedly per frame. Furthermore, for majority of the functions we are able to fully utilize the SIMD vectors and achieve good speedup. So far we have vectorized several mat4 functions using the SIMD.js API: rotation, scaling, translation, multiplication, translation, adjoint, and inverse.
gl-matrix functions expect vector/matrix parameters to be stored in JavaScript typed arrays. The SIMD.js API contains functions to load and store vectors from typed arrays. This means we are able to use the same function signature for a vectorized version of functions. We have packed the original scalar and the vectorized implementations into two classes: mat4.scalar and mat4.SIMD. Here are the signatures for scalar and SIMD versions of the mat4.multiply function:
//Scalar implementation
mat4.scalar.multiply = function (out, a, b) { /* Scalar implementation*/}
//Vectorized implementation
mat4.SIMD.multiply = function (out, a, b) { /* SIMD implementation*/}
gl-matrix checks if the browser supports SIMD.js, and sets the glMatrix.SIMD_AVAIALABLE flag accordingly. If SIMD.js is available, SIMD implementation can be selected by setting the glMatrix.ENABLE_SIMD flag to true. The following code snippets show how different versions of multiply function are selected:
glMatrix.USE_SIMD = glMatrix.ENABLE_SIMD && glMatrix.SIMD_AVAILABLE;//Select the SIMD implementation if SIMD is supported and enabled
mat4.multiply = glMatrix.USE_SIMD ? mat4.SIMD.multiply : mat4.scalar.multiply;
Selection of vectorization-friendly algorithms is critical for vectorization. For instance, there are various ways to calculate the inverse of 4×4 Matrix, but the best results are achieved with a method based on Cramer’s rule. Also, to obtain the theoretical speedup, SIMD instructions should be selected carefully, as some instructions operate sequentially and have longer latencies. We didn’t apply loop unrolling here, but it is a good technique to consider to expose the concurrency and achieve higher speedup.
Experimental Results
SIMD.js has been under standardization for quite a while, but it’s only recently that its API advanced to stage 3, where it will be considered stable. Although there is work in progress to support SIMD.js in major browsers including Chromium and Microsoft Edge, at the moment it is only available in Firefox Nightly builds for the x64 and x86 family of processors.
I developed a small benchmark to evaluate the performance of vectorized gl-matrix using SIMD.js. It measures the average execution time of scalar and vectorized implementations of mat4 functions with random input matrices over a large number of iterations.
Let’s have a glance at how the SpiderMonkey engine executes SIMD.js programs before getting into the results. At the beginning, JavaScript functions start executing in the interpreter. At this point, SIMD objects are stored in sequential arrays, and all the operations on them are performed sequentially. Thus, there is no performance gain at this stage. To benefit from SIMD, a JavaScript program needs to compile to optimized machine code leveraging SIMD instructions. But since compilation is a time-consuming process, the benefits are noticeable only if a considerable amount of time is spent executing the function.
SIMD.js is supposed to be a common subset of SIMD intrinsics available in Intel SSE2 and ARM NEON. Vectors in SIMD.js have a fixed width of 128 bits, which can be utilized, for instance, to store four integers, four single precision floats, or two double precision floats. Since gl-matrix is using single precision floats to represent numbers, vectors can hold up to four data elements. Thus, parallelism is limited by four.
We used Firefox Nightly 44 on a X86-64 machine to launch the gl-matrix benchmark. Figure 1 shows the vectorization speedup reported by the benchmark. The Y axis represent the speedup of vectorized implementation compared to the scalar version. Red bars represent the speedup of assembly code with SIMD instructions compared to the assembly code using only scalar instructions. Both versions are generated by the IonMonkey JIT compiler. They reveal the maximum speedup that we can expect from SIMD.js implementation for each function.
The amount of speedup depends on theoretical parallelization limits of each algorithm, as well as implementation details including compiler optimizations and underlying hardware. However, as mentioned earlier, generating optimized machine code is expensive and only takes place after spending adequate amount of time executing the functions. This fact is reflected by blue bars. Blue bars represent the speedup of vectorized implementations compared to scalar versions, when functions are invoked 5 million times. Those include all stages of JavaScript execution including interpreter mode and JIT compilation. Increasing the number of iterations leads to spending more on execution of the compiled code, hence getting closer to the maximum speedup.
Our measurements show significant performance improvement for multiplication and transposition functions (about 3x speedup), and more than 2x speedup for six other functions: adjoint, inverse, rotation around axes, and scaling. There is limited amount of parallelism available in the translate function, which results in a relatively lower speedup.
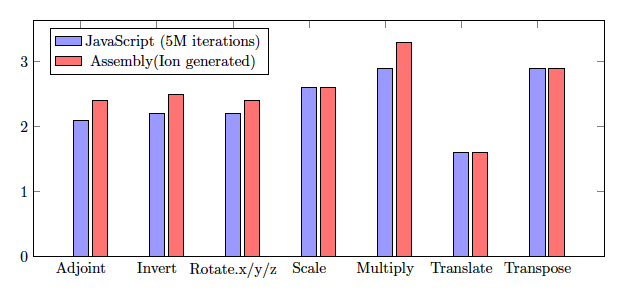
Fig.1. gl-matrix Mat4 Speedup with SIMD.js (higher is better)
Conclusion
In conclusion, SIMD.js can deliver major speedup to many JavaScript programs in high performance computing and the domain of multimedia. We evaluated the SIMD.js performance with gl-matrix and observed significant performance improvement. We’re very excited about the potentials of SIMD.js and are looking forward to other successful deployments of SIMD.js on the open web platform.
About Sajjad Taheri
CS PhD student at UC Irvine and a former Mozilla intern.
2 comments