
Hi, my name is Thorben and I work at Opera Software in Oslo, not at Mozilla. So, how did I end up writing for Mozilla Hacks? Maybe you know that there is no default PDF viewer in the Opera Browser, something we would like to change. But how to include one? Buy it from Adobe or Foxit? Start our own?
Introducing PDF.js
While investigating our options we quickly stumbled upon PDF.js. The project aims to create a full-featured PDF viewer in the browser using JavaScript and Canvas. Yeah, it sounds a bit crazy, but it makes sense: browsers need to be good at processing text, images, fonts, and vector graphics — exactly the things a PDF viewer has to be good at. The draw commands in PDFs are a subset of Postscript, and they are not so different from what Canvas offers. Also security is virtually no issue: using PDF.js is as secure as opening any other website.
Working on PDF.js
So Christian Krebs, Mathieu Henri and myself began looking at PDF.js in more detail and were impressed: it’s well designed, seems fast and big parts of the code are just wow!
But we also discovered some problems, mainly with performance on very large or graphics-heavy PDFs. We decided that the best way to get to know PDF.js better and to push the project further, was to help the project and address the major issues we found. This gave us a pretty good understanding of the project and its high potential. We were also very impressed by how much the performance of PDF.js improved while we worked on it. This is an active and well managed project.
Benchmarking PDF.js
Of course, our tests gave us the wrong impression about performance. We tried to find super large, awkward and hard-to-render PDFs, but that is not what most people want to view. Most PDFs you actually want to view in PDF.js are fine. But how to test that?
Well, you could check the most popular PDFs on the Internet – as these are the ones you probably want to view – and benchmark them. A snapshot of 5 to 10k PDFs should be enough … but how do you get them?
I figured that search engines would be my friend. If you tell them to search for PDFs only, they give you the most relevant PDFs for that keyword, which in turn are probably the most popular ones. And if you use the most searched keywords you end up with a good approximation.
Benchmarking that many PDFs is a big task. So I got myself a small cluster of old computers and built a nice server application that supplied them with tasks. The current repository has almost 7000 PDFs and benchmarking one version of PDF.js takes around eight hours.
The results
Let’s skip to the interesting part with the pretty pictures. This graph
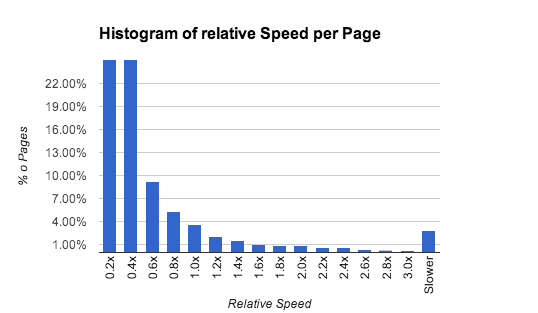
gives us almost all the interesting results at one look. You see a histogram of the time it took to process all the pages in the PDFs in relation to the average time it takes to process the average page of the Tracemonkey Paper (the default PDF you see when opening PDF.js). The User Experience when viewing the Tracemonkey Paper is good and from my tests even 3 to 4 times slower is still okay. That means from all benchmarked pages over 96% (exclude pdfs that crashed) will translate to a good user experience. That is really good news! Or to use a very simple pie chart (in % of pages):
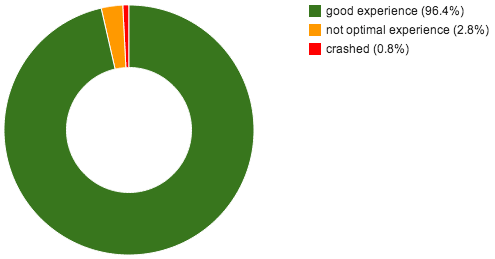
You probably already noticed the small catch: around 0.8% of the PDFs crashed PDF.js when we tested them. We had a closer look at most of them and at least a third are actually so heavily damaged that probably no PDF viewer could ever display them.
And this leads us to another good point: we have to keep in mind that these results just stand here without comparison. There are some PDFs on the Internet that are so complex that there is no hope that even native PDF viewers could display them nice and fast. The slowest tested PDF is an incredibly detailed vector map of the public transport system of Lisbon. Try to open it in Adobe Reader, it’s not fun!
Conclusion
From these results we concluded that PDF.js is a very valid candidate to be used as the default PDF viewer in the Opera Browser. There is still a lot of work to do to integrate PDF.js nicely into it, but we are working right now on integrating it behind an experimental flag (BTW: There is an extension that adds PDF.js with the default Mozilla viewer. The “nice” integration I am talking about would be deeper and include a brand new viewer). Thanks Mozilla! We are looking forward to working on PDF.js together with you guys!
PS: Both the code of the computational system and the results are publicly available. Have a look and tell us if you find them useful!
PPS: If anybody works at a big search engine company and could give me a list with the actual 10k most used PDFs, that would be awesome :)
Appendix: What’s next?
The corpus and the computational framework I described, could be used to do all kinds of interesting things. In the next step, we hope to classify PDFs by used fonts formats, image formats and the like. So you can quickly get PDFs to test a new feature with. We also want to look at which drawing instructions are used with which frequency in the Postscript so we can better optimise for the very common ones, like we did with HTML in browsers. Let’s see what we can actually do ;)
About Thorben Bochenek
JavaScript Engineer at Opera Software in Oslo, Norway. Thorben learned to like the lean nature of JavaScript when he interned and became the only JS-developer in a hardcore Java company in Zurich. He studied computer science at ETH Zurich, loves to travel and only writes blog posts when he is asked to do so.
More articles by Thorben Bochenek…
About Robert Nyman [Editor emeritus]
Technical Evangelist & Editor of Mozilla Hacks. Gives talks & blogs about HTML5, JavaScript & the Open Web. Robert is a strong believer in HTML5 and the Open Web and has been working since 1999 with Front End development for the web - in Sweden and in New York City. He regularly also blogs at http://robertnyman.com and loves to travel and meet people.
37 comments