
asm.js is a simple subset of JavaScript that is very easy to optimize, suitable for use as a compiler target from languages like C and C++. Earlier this year Firefox could run asm.js code at about half of native speed – that is, C++ code compiled by emscripten could run at about half the speed that the same C++ code could run when compiled natively – and we thought that through improvements in both emscripten (which generates asm.js code from C++) and JS engines (that run that asm.js code), it would be possible to get much closer to native speed.
Since then many speedups have arrived, lots of them small and specific, but there were also a few large features as well. For example, Firefox has recently gained the ability to optimize some floating-point operations so that they are performed using 32-bit floats instead of 64-bit doubles, which provides substantial speedups in some cases as shown in that link. That optimization work was generic and applied to any JavaScript code that happens to be optimizable in that way. Following that work and the speedups it achieved, there was no reason not to add float32 to the asm.js type system so that asm.js code can benefit from it specifically.
The work to implement that in both emscripten and SpiderMonkey has recently completed, and here are the performance numbers:
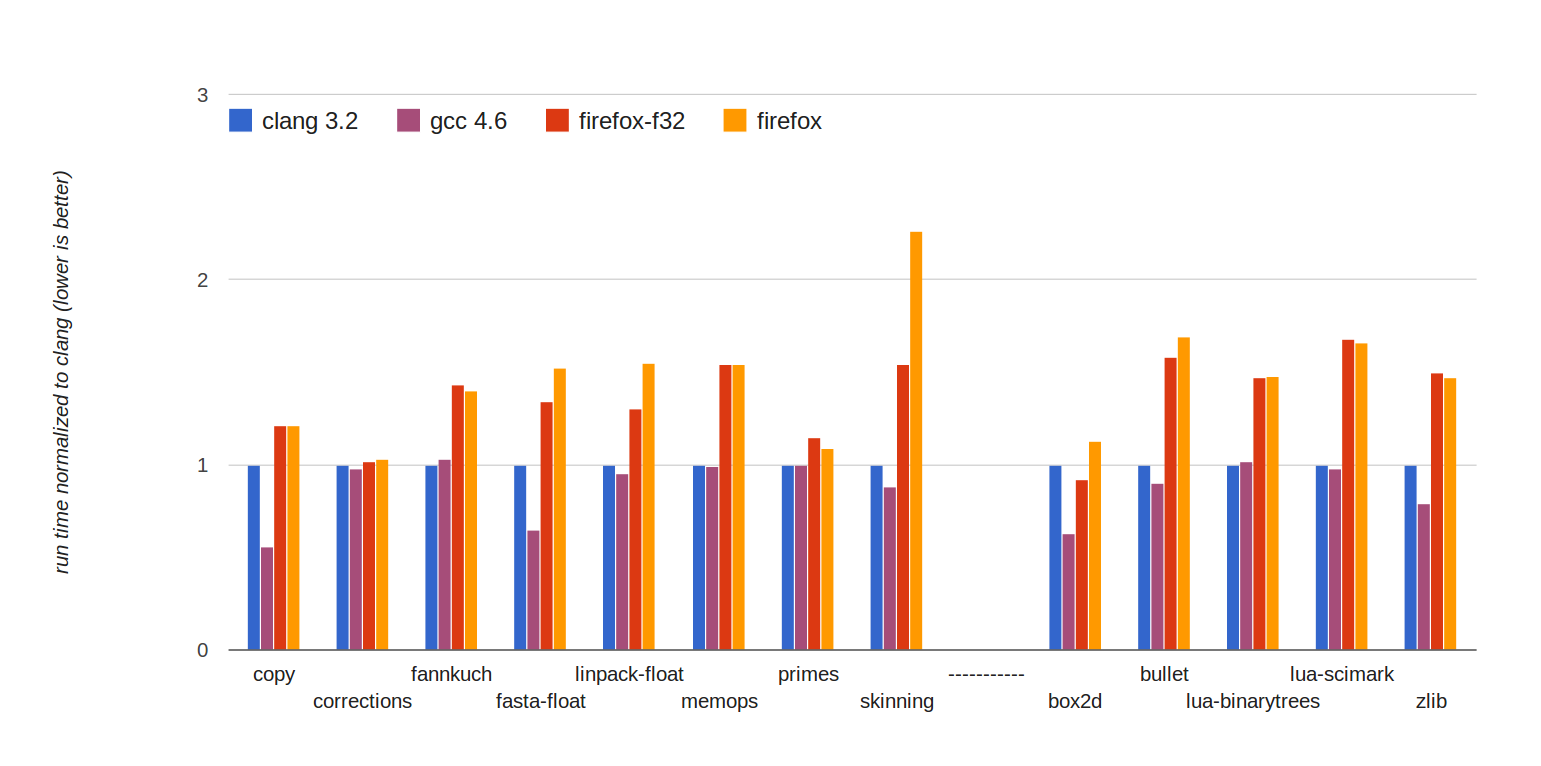
Run times are normalized to clang, so lower is better. The red bars (firefox-f32) represent Firefox running on emscripten-generated code using float32. As the graph shows, Firefox with float32 optimizations can run all those benchmarks at around 1.5x slower than native, or better. That’s a big improvement from earlier this year, when as mentioned before things were closer to 2x slower than native. You can also see the specific improvement thanks to float32 optimizations by comparing to the orange bar (firefox) next to it – in floating-point heavy benchmarks like skinning, linpack and box2d, the speedup is very noticeable.
Another thing to note about those numbers is that not just one native compiler is shown, but two, both clang and gcc. In a few benchmarks, the difference between clang and gcc is significant, showing that while we often talk about “times slower than native speed”, “native speed” is a somewhat loose term, since there are differences between native compilers.
In fact, on some benchmarks, like box2d, fasta and copy, asm.js is as close or closer to clang than clang is to gcc. There is even one case where asm.js beats clang by a slight amount, on box2d (gcc also beats clang on that benchmark, by a larger amount, so probably clang’s backend codegen just happens to be a little unlucky there).
Overall, what this shows is that “native speed” is not a single number, but a range. It looks like asm.js on Firefox is very close to that range – that is, while it’s on average slower than clang and gcc, the amount it is slower by is not far off from how much native compilers differ amongst themselves.
Note that float32 code generation is off by default in emscripten. This is intentional, as while it can both improve performance as well as ensure the proper C++ float semantics, it also increases code size – due to adding Math.fround calls – which can be detrimental in some cases, especially in JavaScript engines not yet supporting Math.fround.
There are some ways to work around that issue, such as the outlining option which reduces maximum function size. We have some other ideas on ways to improve code generation in emscripten as well, so we’ll be experimenting with those for a while as well as following when Math.fround gets supported in browsers (so far Firefox and Safari do). Hopefully in the not so far future we can enable float32 optimizations by default in emscripten.
Summary
In summary, the graph above shows asm.js performance getting yet closer to native speed. While for the reasons just mentioned I don’t recommend that people build with float32 optimizations quite yet – hopefully soon though! – it’s an exciting increase in performance. And even the current performance numbers – 1.5x slower than native, or better – are not the limit of what can be achieved, as there are still big improvements either under way or in planning, both in emscripten and in JavaScript engines.
About Alon Zakai
Alon is on the research team at Mozilla, where he works primarily on Emscripten, a compiler from C and C++ to JavaScript. Alon founded the Emscripten project in 2010.
About Robert Nyman [Editor emeritus]
Technical Evangelist & Editor of Mozilla Hacks. Gives talks & blogs about HTML5, JavaScript & the Open Web. Robert is a strong believer in HTML5 and the Open Web and has been working since 1999 with Front End development for the web - in Sweden and in New York City. He regularly also blogs at http://robertnyman.com and loves to travel and meet people.
20 comments