
If you’re running Firefox on macOS you might have noticed that its responsiveness has improved significantly in version 103, especially if you’ve got a lot of tabs, or when your machine is busy running other applications at the same time. This improvement was achieved via a small change in how locking is implemented within Firefox’s memory allocator.
Firefox uses a highly customized version of the jemalloc memory allocator across all architectures. We’ve diverged significantly from upstream jemalloc in order to guarantee optimal performance and memory usage on Firefox.
Memory allocators have to be thread safe and – in order to be performant – need to be able to serve a large number of concurrent requests from different threads. To achieve this, jemalloc uses locks within its internal structures that are usually only held very briefly.
Locking within the allocator is implemented differently than in the rest of the codebase. Specifically, creating mutexes and using them must not issue new memory allocations because that would lead to infinite recursion within the allocator itself. To achieve this the allocator tends to use thin locks native to the underlying operating system. On macOS we relied for a long time on OSSpinLock locks.
As the name suggests these are not regular mutexes that put threads trying to acquire them to sleep if they’re already taken by another thread. A thread attempting to lock an already locked instance of OSSpinLock will busy-poll the lock instead of waiting for it to be released, which is commonly referred to as spinning on the lock.
This might seem counter-intuitive, as spinning consumes CPU cycles and power and is usually frowned upon in modern codebases. However, putting a thread to sleep has significant performance implications and thus is not always the best option.
In particular, putting a thread to sleep and then waking it up requires two context switches as well as saving and restoring the thread state to/from memory. Depending on the CPU and workload the thread state can range from several hundred bytes to a few kilobytes. Putting a thread to sleep also has indirect performance effects.
For example, the caches associated with the core the thread was running on were likely holding useful data. When a thread is put to sleep another thread from an unrelated workload might then be selected to run in its place, replacing the data in the caches with new data.
When the original thread is restored it might end up on a different core, or on the same core but with cold caches, filled with unrelated data. Either way, the thread will proceed execution more slowly than if it had kept running undisturbed.
Because of all the above, it might be advantageous to let a thread spin briefly if the lock it’s trying to acquire is only held for a brief period of time. It can result in both higher performance and lower power consumption as the cost of spinning is less than sleeping.
However spinning has a significant drawback: if it goes on for too long it can be detrimental, as it will just waste cycles. Worse still, if the machine is heavily loaded, spinning might put additional load on the system, potentially slowing down precisely the thread that owns the lock, increasing the chance of further threads needing the lock, spinning some more.
As you might have guessed by now OSSpinLock offered very good performance on a lightly loaded system, but behaved poorly as load ramped up. More importantly it had two fundamental flaws: it spinned in user-space and never slept.
Spinning in user-space is a bad idea in general, as user-space doesn’t know how much load the system is currently experiencing. In kernel-space a lock might make an informed decision, for example not to spin at all if the load is high, but OSSpinLock had no such provision, nor did it adapt.
But more importantly, when it couldn’t really grab a lock it would yield instead of sleeping. This is particularly bad because the kernel has no clue that the yielding thread is waiting on a lock, so it might wake up another thread that is also fighting for the same lock instead of the one that owns it.
This will lead to more spinning and yielding and the resulting user experience will be terrible. On heavily loaded systems this could lead to a near live-lock and Firefox effectively hanging. This problem with OSSpinLock was known within Apple hence its deprecation.
Enter os_unfair_lock, Apple’s official replacement for OSSpinLock. If you still use OSSpinLock you’ll get explicit warnings to use it instead.
So I went ahead and used it, but the results were terrible. Performance in some of our automated tests degraded by as much as 30%. os_unfair_lock might be better behaved than OSSpinLock, but it sucked.
As it turns out os_unfair_lock doesn’t spin on contention, it makes the calling thread sleep right away when it finds a contended lock.
For the memory allocator this behavior was suboptimal and the performance regression unacceptable. In some ways, os_unfair_lock had the opposite problem of OSSpinLock: it was too willing to sleep when spinning would have been a better choice. At this point, it’s worth mentioning while we’re at it that pthread_mutex locks are even slower on macOS so those weren’t an option either.
However, as I dug into Apple’s libraries and kernel, I noticed that some spin locks were indeed available, and they did the spinning in kernel-space where they could make a more informed choice with regards to load and scheduling. Those would have been an excellent choice for our use-case.
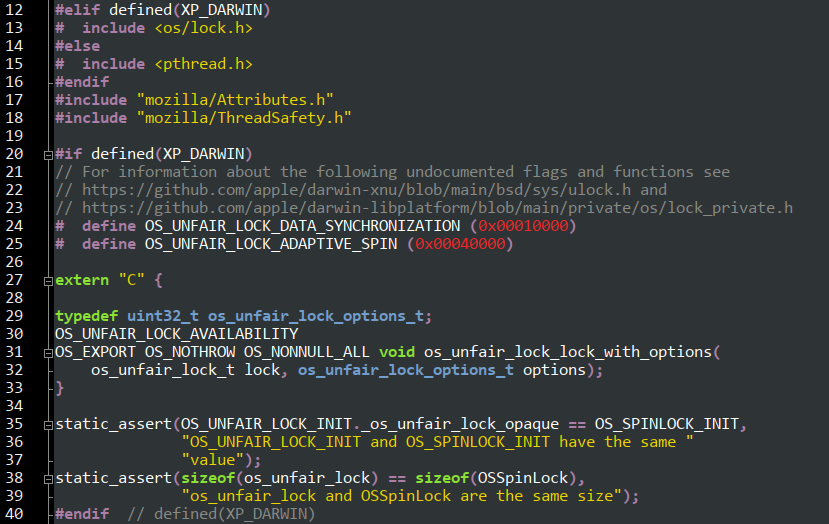
So how do you use them? Well, it turns out they’re not documented. They rely on a non-public function and flags which I had to duplicate in Firefox.
The function is os_unfair_lock_with_options() and the options I used are OS_UNFAIR_LOCK_DATA_SYNCHRONIZATION and OS_UNFAIR_LOCK_ADAPTIVE_SPIN.
The latter asks the kernel to use kernel-space adaptive spinning, and the former prevents it from spawning additional threads in the thread pools used by Apple’s libraries.
Did they work? Yes! Performance on lightly loaded systems was about the same as OSSpinLock but on loaded ones, they provided massively better responsiveness. They also did something extremely useful for laptop users: they cut down power consumption as a lot less cycles were wasted having the CPUs spinning on locks that couldn’t be acquired.
Unfortunately, my woes weren’t over. The OS_UNFAIR_LOCK_ADAPTIVE_SPIN flag is supported only starting with macOS 10.15, but Firefox also runs on older versions (all the way to 10.12).
As an intermediate solution, I initially fell back to OSSpinLock on older systems. Later I managed to get rid of it for good by relying on os_unfair_lock plus manual spinning in user-space.
This isn’t ideal but it’s still better than relying on OSSpinLock, especially because it’s needed only on x86-64 processors, where I can use pause instructions in the loop which should reduce the performance and power impact when a lock can’t be acquired.
When two threads are running on the same physical core, one using pause instructions leaves almost all of the core’s resources available to the other thread. In the unfortunate case of two threads spinning on the same core they’ll still consume very little power.
At this point, you might wonder if os_unfair_lock – possibly coupled with the undocumented flags – would be a good fit for your codebase. My answer is likely yes but you’ll have to be careful when using it.
If you’re using the undocumented flags be sure to routinely test your software on new beta versions of macOS, as they might break in future versions. And even if you’re only using os_unfair_lock public interface beware that it doesn’t play well with fork(). That’s because the lock stores internally the mach thread IDs to ensure consistent acquisition and release.
These IDs change after a call to fork() as the thread creates new ones when copying your process’ threads. This can lead to potential crashes in the child process. If your application uses fork(), or your library needs to be fork()-safe you’ll need to register at-fork handlers using pthread_atfork() to acquire all the locks in the parent before the fork, then release them after the fork (also in the parent), and reset them in the child.
Here’s how we do it in our code.
One comment