
We successfully deployed ThreadSanitizer in the Firefox project to eliminate data races in our remaining C/C++ components. In the process, we found several impactful bugs and can safely say that data races are often underestimated in terms of their impact on program correctness. We recommend that all multithreaded C/C++ projects adopt the ThreadSanitizer tool to enhance code quality.
What is ThreadSanitizer?
ThreadSanitizer (TSan) is compile-time instrumentation to detect data races according to the C/C++ memory model on Linux. It is important to note that these data races are considered undefined behavior within the C/C++ specification. As such, the compiler is free to assume that data races do not happen and perform optimizations under that assumption. Detecting bugs resulting from such optimizations can be hard, and data races often have an intermittent nature due to thread scheduling.
Without a tool like ThreadSanitizer, even the most experienced developers can spend hours on locating such a bug. With ThreadSanitizer, you get a comprehensive data race report that often contains all of the information needed to fix the problem.
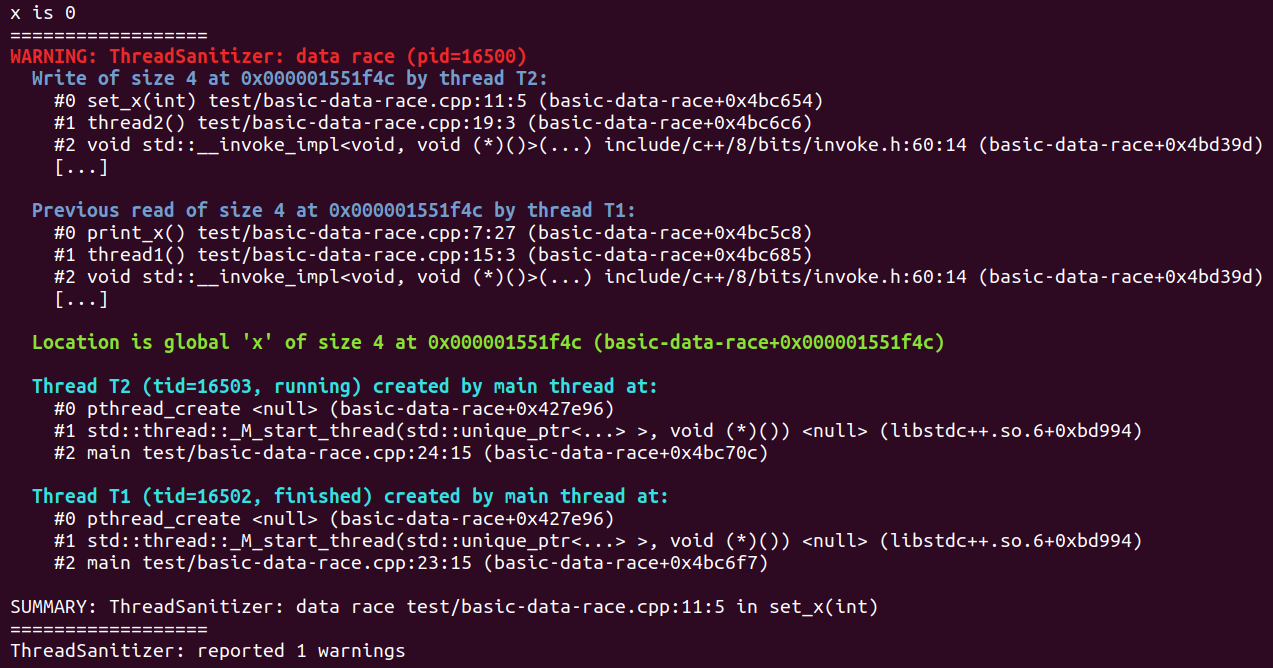 ThreadSanitizer Output for this example program (shortened for article)
ThreadSanitizer Output for this example program (shortened for article)
One important property of TSan is that, when properly deployed, the data race detection does not produce false positives. This is incredibly important for tool adoption, as developers quickly lose faith in tools that produce uncertain results.
Like other sanitizers, TSan is built into Clang and can be used with any recent Clang/LLVM toolchain. If your C/C++ project already uses e.g. AddressSanitizer (which we also highly recommend), deploying ThreadSanitizer will be very straightforward from a toolchain perspective.
Challenges in Deployment
Benign vs. Impactful Bugs
Despite ThreadSanitizer being a very well designed tool, we had to overcome a variety of challenges at Mozilla during the deployment phase. The most significant issue we faced was that it is really difficult to prove that data races are actually harmful at all and that they impact the everyday use of Firefox. In particular, the term “benign” came up often. Benign data races acknowledge that a particular data race is actually a race, but assume that it does not have any negative side effects.
While benign data races do exist, we found (in agreement with previous work on this subject [1] [2]) that data races are very easily misclassified as benign. The reasons for this are clear: It is hard to reason about what compilers can and will optimize, and confirmation for certain “benign” data races requires you to look at the assembler code that the compiler finally produces.
Needless to say, this procedure is often much more time consuming than fixing the actual data race and also not future-proof. As a result, we decided that the ultimate goal should be a “no data races” policy that declares even benign data races as undesirable due to their risk of misclassification, the required time for investigation and the potential risk from future compilers (with better optimizations) or future platforms (e.g. ARM).
However, it was clear that establishing such a policy would require a lot of work, both on the technical side as well as in convincing developers and management. In particular, we could not expect a large amount of resources to be dedicated to fixing data races with no clear product impact. This is where TSan’s suppression list came in handy:
We knew we had to stop the influx of new data races but at the same time get the tool usable without fixing all legacy issues. The suppression list (in particular the version compiled into Firefox) allowed us to temporarily ignore data races once we had them on file and ultimately bring up a TSan build of Firefox in CI that would automatically avoid further regressions. Of course, security bugs required specialized handling, but were usually easy to recognize (e.g. racing on non-thread safe pointers) and were fixed quickly without suppressions.
To help us understand the impact of our work, we maintained an internal list of all the most serious races that TSan detected (ones that had side-effects or could cause crashes). This data helped convince developers that the tool was making their lives easier while also clearly justifying the work to management.
In addition to this qualitative data, we also decided for a more quantitative approach: We looked at all the bugs we found over a year and how they were classified. Of the 64 bugs we looked at, 34% were classified as “benign” and 22% were “impactful” (the rest hadn’t been classified).
We knew there was a certain amount of misclassified benign issues to be expected, but what we really wanted to know was: Do benign issues pose a risk to the project? Assuming that all of these issues truly had no impact on the product, are we wasting a lot of resources on fixing them? Thankfully, we found that the majority of these fixes were trivial and/or improved code quality.
The trivial fixes were mostly turning non-atomic variables into atomics (20%), adding permanent suppressions for upstream issues that we couldn’t address immediately (15%), or removing overly complicated code (20%). Only 45% of the benign fixes actually required some sort of more elaborate patch (as in, the diff was larger than just a few lines of code and did not just remove code).
We concluded that the risk of benign issues being a major resource sink was not an issue and well acceptable for the overall gains that the project provided.
False Positives?
As mentioned in the beginning, TSan does not produce false positive data race reports when properly deployed, which includes instrumenting all code that is loaded into the process and avoiding primitives that TSan doesn’t understand (such as atomic fences). For most projects these conditions are trivial, but larger projects like Firefox require a bit more work. Thankfully this work largely amounted to a few lines in TSan’s robust suppression system.
Instrumenting all code in Firefox isn’t currently possible because it needs to use shared system libraries like GTK and X11. Fortunately, TSan offers the “called_from_lib” feature that can be used in the suppression list to ignore any calls originating from those shared libraries. Our other major source of uninstrumented code was build flags not being properly passed around, which was especially problematic for Rust code (see the Rust section below).
As for unsupported primitives, the only issue we ran into was the lack of support for fences. Most fences were the result of a standard atomic reference counting idiom which could be trivially replaced with an atomic load in TSan builds. Unfortunately, fences are fundamental to the design of the crossbeam crate (a foundational concurrency library in Rust), and the only solution for this was a suppression.
We also found that there is a (well known) false positive in deadlock detection that is however very easy to spot and also does not affect data race detection/reporting at all. In a nutshell, any deadlock report that only involves a single thread is likely this false positive.
The only true false positive we found so far turned out to be a rare bug in TSan and was fixed in the tool itself. However, developers claimed on various occasions that a particular report must be a false positive. In all of these cases, it turned out that TSan was indeed right and the problem was just very subtle and hard to understand. This is again confirming that we need tools like TSan to help us eliminate this class of bugs.
Interesting Bugs
Currently, the TSan bug-o-rama contains around 20 bugs. We’re still working on fixes for some of these bugs and would like to point out several particularly interesting/impactful ones.
Beware Bitfields
Bitfields are a handy little convenience to save space for storing lots of different small values. For instance, rather than having 30 bools taking up 240 bytes, they can all be packed into 4 bytes. For the most part this works fine, but it has one nasty consequence: different pieces of data now alias. This means that accessing “neighboring” bitfields is actually accessing the same memory, and therefore a potential data race.
In practical terms, this means that if two threads are writing to two neighboring bitfields, one of the writes can get lost, as both of those writes are actually read-modify-write operations of all the bitfields:
If you’re familiar with bitfields and actively thinking about them, this might be obvious, but when you’re just saying myVal.isInitialized = true you may not think about or even realize that you’re accessing a bitfield.
We have had many instances of this problem, but let’s look at bug 1601940 and its (trimmed) race report:
When we first saw this report, it was puzzling because the two threads in question touch different fields (mAsyncTransformAppliedToContent vs. mTestAttributeAppliers). However, as it turns out, these two fields are both adjacent bitfields in the class.
This was causing intermittent failures in our CI and cost a maintainer of this code valuable time. We find this bug particularly interesting because it demonstrates how hard it is to diagnose data races without appropriate tooling and we found more instances of this type of bug (racy bitfield write/write) in our codebase. One of the other instances even had the potential to cause network loads to supply invalid cache content, another hard-to-debug situation, especially when it is intermittent and therefore not easily reproducible.
We encountered this enough that we eventually introduced a MOZ_ATOMIC_BITFIELDS macro that generates bitfields with atomic load/store methods. This allowed us to quickly fix problematic bitfields for the maintainers of each component without having to redesign their types.
Oops That Wasn’t Supposed To Be Multithreaded
We also found several instances of components which were explicitly designed to be single-threaded accidentally being used by multiple threads, such as bug 1681950:
The race itself here is rather simple, we are racing on the same file through stat64 and understanding the report was not the problem this time. However, as can be seen from frame 10, this call originates from the PreferencesWriter, which is responsible for writing changes to the prefs.js file, the central storage for Firefox preferences.
It was never intended for this to be called on multiple threads at the same time and we believe that this had the potential to corrupt the prefs.js file. As a result, during the next startup the file would fail to load and be discarded (reset to default prefs). Over the years, we’ve had quite a few bug reports related to this file magically losing its custom preferences but we were never able to find the root cause. We now believe that this bug is at least partially responsible for these losses.
We think this is a particularly good example of a failure for two reasons: it was a race that had more harmful effects than just a crash, and it caught a larger logic error of something being used outside of its original design parameters.
Late-Validated Races
On several occasions we encountered a pattern that lies on the boundary of benign that we think merits some extra attention: intentionally racily reading a value, but then later doing checks that properly validate it. For instance, code like:
See for example, this instance we encountered in SQLite.
Please Don’t Do This. These patterns are really fragile and they’re ultimately undefined behavior, even if they generally work right. Just write proper atomic code — you’ll usually find that the performance is perfectly fine.
What about Rust?
Another difficulty that we had to solve during TSan deployment was due to part of our codebase now being written in Rust, which has much less mature support for sanitizers. This meant that we spent a significant portion of our bringup with all Rust code suppressed while that tooling was still being developed.
We weren’t particularly concerned with our Rust code having a lot of races, but rather races in C++ code being obfuscated by passing through Rust. In fact, we strongly recommend writing new projects entirely in Rust to avoid data races altogether.
The hardest part in particular is the need to rebuild the Rust standard library with TSan instrumentation. On nightly there is an unstable feature, -Zbuild-std, that lets us do exactly that, but it still has a lot of rough edges.
Our biggest hurdle with build-std was that it’s currently incompatible with vendored build environments, which Firefox uses. Fixing this isn’t simple because cargo’s tools for patching in dependencies aren’t designed for affecting only a subgraph (i.e. just std and not your own code). So far, we have mitigated this by maintaining a small set of patches on top of rustc/cargo which implement this well-enough for Firefox but need further work to go upstream.
But with build-std hacked into working for us we were able to instrument our Rust code and were happy to find that there were very few problems! Most of the things we discovered were C++ races that happened to pass through some Rust code and had therefore been hidden by our blanket suppressions.
We did however find two pure Rust races:
The first was bug 1674770, which was a bug in the parking_lot library. This Rust library provides synchronization primitives and other concurrency tools and is written and maintained by experts. We did not investigate the impact but the issue was a couple atomic orderings being too weak and was fixed quickly by the authors. This is yet another example that proves how difficult it is to write bug-free concurrent code.
The second was bug 1686158, which was some code in WebRender’s software OpenGL shim. They were maintaining some hand-rolled shared-mutable state using raw atomics for part of the implementation but forgot to make one of the fields atomic. This was easy enough to fix.
Overall Rust appears to be fulfilling one of its original design goals: allowing us to write more concurrent code safely. Both WebRender and Stylo are very large and pervasively multi-threaded, but have had minimal threading issues. What issues we did find were mistakes in the implementations of low-level and explicitly unsafe multithreading abstractions — and those mistakes were simple to fix.
This is in contrast to many of our C++ races, which often involved things being randomly accessed on different threads with unclear semantics, necessitating non-trivial refactorings of the code.
Conclusion
Data races are an underestimated problem. Due to their complexity and intermittency, we often struggle to identify them, locate their cause and judge their impact correctly. In many cases, this is also a time-consuming process, wasting valuable resources. ThreadSanitizer has proven to be not just effective in locating data races and providing adequate debug information, but also to be practical even on a project as large as Firefox.
Acknowledgements
We would like to thank the authors of ThreadSanitizer for providing the tool and in particular Dmitry Vyukov (Google) for helping us with some complex, Firefox-specific edge cases during deployment.
About Christian Holler
Christian is a Firefox Tech Lead and Principal Engineer at Mozilla.
More articles by Christian Holler…
About Aria Beingessner
More articles by Aria Beingessner…
5 comments