
In 2018, we launched Firefox Extension Workshop, a site for Firefox-specific extension development documentation. The site was originally built using the Ruby-based static site generator Jekyll. We had initially selected Jekyll for this project because we wanted to make it easy for editors to update the site using Markdown, a lightweight markup language.
Once the site had been created and more documentation was added, the build times started to grow. Every time we made a change to the site and wanted to test it locally, it would take ten minutes or longer for the site to build. The builds took so long that we needed to increase the default time limit for CircleCI, our continuous integration and continuous delivery service, because builds were failing when they ran past ten minutes with no output.
Investigating these slow builds using profiling showed that most of the time was being spent in the Liquid template rendering calls.
In addition to problems with build times, there were also issues with cache-busting in local development. This meant that things like a change of images wouldn’t show up in the site without a full rebuild after clearing the local cache.
As we were discussing how to best move forward, Jekyll 4 was released with features expected to improve build performance. However, an early test of porting to this version actually performed worse than the previous version. We then realized that we needed to find an alternative and port the site.
Update: 05-10-2020: A Jekyll developer reached out having investigated the slow builds. The findings were that Jekyll on its own isn’t slow, the high build times in our case were primarily caused by 3rd party plugins.
Looking at the Alternatives
The basic requirements for moving away from Jekyll were as follows:
- Build performance needed to be better than the 10 minutes (600s+) it took to build locally.
- Local changes should be visible as quickly as possible.
- Ideally the solution would be JavaScript based, as the Add-ons Engineering team has a lot of collective JavaScript experience and a JavaScript based infrastructure would make it easier to extend.
- It needed to be flexible, enough to meet the demands of adding more documentation in the future.
Hugo (written in Go), Gatsby (JS), and Eleventy (11ty) (JS) were all considered as options.
In the end, Eleventy was chosen for one main reason: it provided enough similarities to Jekyll that we could migrate the site without a major rewrite. In contrast, both Hugo and Gatsby would have required a significant refactoring. Porting the site also meant less changes up front, which allowed us to focus on maintaining parity with the site already in production.
As Eleventy provides an option to use liquid templates, via LiquidJS, it meant that templates only needed relatively minimal changes to work.
The Current Architecture
There are four main building blocks in the Jekyll site: Liquid templating, Markdown for documentation, Sass for CSS, and JQuery for behaviour.
To migrate to Eleventy we planned to minimize changes to how the site works, and focus on porting all of the existing documentation without changing the CSS or JavaScript.
Getting Started with the Port
The blog post Turning Jekyll up to Eleventy by Paul Lloyd was a great help in describing what would need to be done to get the site working under Eleventy.
The first step was to create the an Eleventy configuration file based on the old Jekyll one.
Data files were moved from YAML to JSON. This was done via a YAML to JSON conversion.
Next, the templates were updated to fix the differences in variables and the includes. The jekyll-assets plugin syntax was removed so that assets were directly served from the assets directory.
Up and Running with Statics
As a minimal fix to replace the Jekyll plugins for CSS and JS, the CSS (Sass) and JS were built with Command Line Interface (CLI) scripts added to the package.json using Uglify and SASS.
For Sass, this required loading paths via the CLI and then just passing the main stylesheet:
sass
--style=compressed
--load-path=node_modules/foundation-sites/scss/
--load-path=node_modules/slick-carousel/slick/
_assets/css/styles.scss _assets/css/styles.css
For JS, every script was passed to uglify in order:
uglifyjs
node_modules/jquery/dist/jquery.js
node_modules/dompurify/dist/purify.js
node_modules/velocity-animate/velocity.js
node_modules/velocity-ui-pack/velocity.ui.js
node_modules/slick-carousel/slick/slick.js
_assets/js/tinypubsub.js
_assets/js/breakpoints.js
_assets/js/parallax.js
_assets/js/parallaxFG.js
_assets/js/inview.js
_assets/js/youtubeplayer.js
_assets/js/main.js
-o _assets/js/bundle.js
This was clearly quite clunky, but it got JS and CSS working in development albeit in a way that required a script to be run manually. However, with the CSS and JS bundles working, this made it possible to focus on getting the homepage up and running without worrying about anything more complicated to start with.
With a few further tweaks the homepage built successfully:
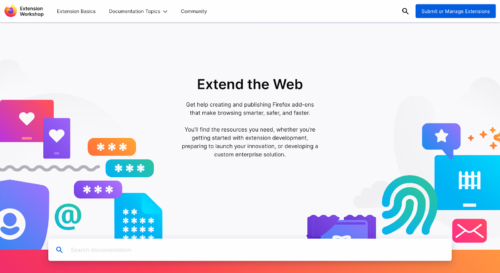
Screenshot of the Extension Workshop Homepage built with Eleventy
Getting the entire site to build
With the homepage looking like it should, the next task was fixing the rest of the syntax. This was a pretty laborious process of updating all the templates and removing or replacing plugins and filters that Eleventy didn’t have.
After some work fixing up the files, finally the entire site could be built without error! 🎉
What was immediately apparent was how fast Eleventy is. The entire site was built in under 3 seconds. That is not a typo; it is 3 seconds not minutes.

Doc from Back to the Future when he first realizes how fast Eleventy is: “Under 3 seconds… Great Scott!”
Improving Static Builds
Building JS and CSS is not part of Eleventy itself. This means it’s up to you to decide how you want to handle statics.
The goals were as follows:
- Keep it fast.
- Keep it simple (especially for content authors)
- Have changes be reflected as quickly as possible.
The first approach moved the CSS and JS to node scripts. These replicated the crude CLI scripts using APIs.
Ultimately we decided to decouple asset building from Eleventy entirely. This meant that Eleventy could worry about building the content, and a separate process would handle the static assets. It also meant that the static asset scripts could write out to the build folder directly.
This made it possible to have the static assets built in parallel with the Eleventy build. The downside was that Eleventy couldn’t tell the browserSync instance (the server Eleventy uses in development) to update as it wasn’t involved with this process. It also meant that watching JS and SASS source files needed to be handled with a separate watching configuration, which in this case was handled via chokidar-cli. Here’s the command used in the package.json script for the CSS build:
chokidar 'src/assets/css/*.scss' -c 'npm run sass:build'
The sass:build script runs bin/build-styles
Telling BrowserSync to update JS and CSS
With the JS and CSS being built correctly, we needed to update the browserSync instance to tell it that the JS and CSS had changed. This way, when you make a CSS change the page will reload without a refresh. Fast updates provide the ideal short feedback loop for iterative changes.
Fortunately, browserSync has a web API. We were able to use this to tell browserSync to update every time the CSS or JS build is built in development.
For the style bundle, the URL called is http://localhost:8081/__browser_sync__?method=reload&args=styles.css
To handle this, the build script fetches this URL whenever new CSS is built.
Cleaning Up
Next, we needed to clean up everything and make sure the site looked right. Missing plugin functionality needed to be replaced and docs and templates needed several adjustments.
Here’s a list of some of the tasks required:
- Build a replacement for the Jekyll SEO plugin in templating and computed data.
- Clean-up syntax-highlighting and move to “code fences.”
- Use the 11ty “edit this page on github” recipe. (A great feature for making it easier to accept contributions to document improvements).
- Clean-up templates to fix some errant markup. This was mainly about looking at whitespace control in liquid as in some cases there were some bad interactions with the markdown which resulted in spurious extra elements.
- Recreate the pages API plugin. Under Jekyll this was used by the search, so we needed to recreate this for parity in order to avoid re-implementing the search from scratch.
- Build tag pages instead of using the search. This was also done for SEO benefits.
Building for Production
With the site looking like it should and a lot of the minor issues tidied up, one of the final steps was to look at how to handle building the static assets for production.
For optimal performance, static assets should not need to be fetched by the browser if that asset (JS, CSS, Image, fonts etc) is in the browser’s cache. To do that you can serve assets with expires headers set into the future (typically one year). This means that if foo.js is cached, when asked to fetch it, the browser won’t re-fetch it unless the cache is removed or the cached asset is older than the expiration date set via the expires header in the original response.
Once you’re caching assets in this way, the URL of the resource needs to be changed to “bust the cache”, otherwise the browser won’t make a request if the cached asset is considered “fresh.”
Cache-busting strategies
Here’s a few standard approaches used for cache-busting URLS:
Whole Site Version Strings
The git revision of the entire site can be used as part of the URL. This means that every time a revision is added and the site is published, every asset would be considered fresh. The downside is that this will cause clients to download every asset even if it hasn’t actually been updated since the last time the site was published.
Query Params
With this approach, a query string is appended to a URL with either a hash of the contents or some other unique string e.g:
foo.css?v=1
foo.css?v=4ab8sbc7
A downside of this approach is that in some cases caching proxies won’t consider the query string. This could result in stale assets being served. Despite this, this approach is pretty common and caching proxies don’t typically default to ignoring query params.
Content Hashes with Server-side Rewrites
In this scenario, you change your asset references to point to files with a hash as part of the URL. The server is configured to rewrite those resources internally to ignore the hash.
For example if your HTML refers to foo.4ab8sbc7.css the server will serve foo.css. This means you don’t need to update the actual filename of foo.css to foo.4ab8sbc7.css.
This requires server config to work, but it’s a pretty neat approach.
Content Hashes in Built Files
In this approach, once you know the hash of your content, you need to update the references to that file, and then you can output the file with that hash as part of the filename.
The upside of this approach is that once the static site is built this way it can be served anywhere and you don’t need any additional server config as per the previous example.
This was the strategy we decided to use.
Building an Asset Pipeline
Eleventy doesn’t have an asset pipeline, though this is something that is being considered for the future.
In order to deploy the Eleventy port, cache-busting would be needed so we could continue to deploy to S3 with far future expires headers.
With the Jekyll assets plugin, you used liquid templating to control the assets building. Ideally, I wanted to avoid content authors needing to know about cache-busting at all.
To make this work, all asset references would need to start with “/assets/” and could not be built with variables. Given the simplicity of the site, this was a reasonable limitation.
With asset references easily found, a solution to implement cache-busting was needed.
First attempt: Using Webpack as an asset pipeline
The first attempt used Webpack. We almost got it working using eleventy-webpack-boilerplate as a guide, however this started to introduce differences in the webpack configs for dev and production since it essentially used the built HTML as an entry point. This was because cache-busting and optimizations were not to be part of the dev process to keep the locale development build as fast as possible. Getting this working became more and more complex, requiring special patched forks of loaders because of limitations in the way HTML extraction worked.
Webpack also didn’t work well for this project because of the way it expects to understand relationships in JS modules in order to build a bundle. The JS for this site was written in an older style where the scripts are concatenated together in a specific order without any special consideration for dependencies (other than script order). This alone required a lot of workarounds to work in Webpack.
Second attempt: AssetGraph
On paper, AssetGraph looked like the perfect solution:
AssetGraph is an extensible, node.js-based framework for manipulating and optimizing web pages and web applications. The main core is a dependency graph model of your entire website, where all assets are treated as first class citizens. It can automatically discover assets based on your declarative code, reducing the configuration needs to a minimum.
The main concept is that the relationship between HTML documents and other resources is essentially a graph problem.
AssetGraph-builder uses AssetGraph, and using your HTML as a starting point it works out all the relationships and optimizes all of your assets along the way.
This sounded ideal. However when I ran it on the built content of the site, node ran out of memory. With no control over what it was doing and minimal feedback as to where it was stuck, this attempt was shelved.
That said, the overall goals of the AssetGraph project are really good, and this looks like it’s something worth keeping an eye on for the future.
Third attempt: Building a pipeline script
In the end, the solution that ended up working best was to build a script that would process the assets after the site build was completed by Eleventy.
The way this works is as follows:
- Process all the binary assets (images, fonts etc), record a content hash for them.
- Process the SVG and record a content hash for them.
- Process the CSS, and rewrite references to resources within them, minify the CSS, and record a content hash for them.
- Process the JS, and rewrite references to resources within them, minify the JS, and record a content hash for them.
- Process the HTML and rewrite the references to assets within them.
- Write anything out that hasn’t already been written to a new directory.
Note: there might be some edge cases not covered here. For example, if a JS file references another JS file, this could break depending on the order of processing. The script could be updated to handle this, but that would mean files would need to be re-processed as changed and anything that referenced them would also need to be updated and so on. Since this isn’t a concern for the current site, this was left out for simplicity. There’s also no circular dependency detection. Again, for this site and most other basic sites this won’t be a concern.
There’s a reason optimizations and cache-busting aren’t part of the development build. This separation helps to ensure the site continues to build really fast when making changes locally.
This is a trade-off, but as long as you check the production build before you release it’s a reasonable compromise. In our case, we have a development site built from master, a staging site built from tags with a -stage suffix, and the production site. All of these deployments run the production deployment processes so there’s plenty of opportunity for catching issues with full builds.
Conclusion
Porting to Eleventy has been a positive change. It certainly took quite a lot of steps to get there, but it was worth the effort.
In the past, long build times with Jekyll made this site really painful for contributors and document authors to work with. We’re already starting to see some additional contributions as a result of lowering the barrier of entry.
With this port complete, it’s now starting to become clear what the next steps should be to minimize the boilerplate for document authors and make the site even easier to use and contribute to.
If you have a site running under Jekyll or are considering using a modern static site generator, then taking a look at Eleventy is highly recommended. It’s fast, flexible, well documented, and a joy to work with. ✨
About Stuart Colville
Stuart is the Engineering Manager for Firefox Add-ons.
One comment