
My team, the application services team at Mozilla, works on Firefox Sync, Firefox Accounts and WebPush.
These features are currently shipped on Firefox Desktop, Android and iOS browsers. They will soon be available in our new products such as our upcoming Android browser, our password manager Lockbox, and Firefox for Fire TV.
Solving for one too many targets
Until now, for historical reasons, these functionalities have been implemented in widely different fashions. They’ve been tightly coupled to the product they are supporting, which makes them hard to reuse. For example, there are currently three Firefox Sync clients: one in JavaScript, one in Java and another one in Swift.
Considering the size of our team, we quickly realized that our current approach to shipping products would not scale across more products and would lead to quality issues such as bugs or uneven feature-completeness across platform-specific implementations. About a year ago, we decided to plan for the future. As you may know, Mozilla is making a pretty big bet on the new Rust programming language, so it was natural for us to follow suit.
A cross-platform strategy using Rust
Our new strategy is as follows: We will build cross-platforms components, implementing our core business logic using Rust and wrapping it in a thin platform-native layer, such as Kotlin for Android and Swift for iOS.
The biggest and most obvious advantage is that we get one canonical code base, written in a safe and statically typed language, deployable on every platform. Every upstream business logic change becomes available to all our products with a version bump.
How we solved the FFI challenge safely
However, one of the challenges to this new approach is safely passing richly-structured data across the API boundary in a way that’s memory-safe and works well with Rust’s ownership system. We wrote the ffi-support crate to help with this, if you write code that does FFI (Foreign function interface) tasks you should strongly consider using it. Our initial versions were implemented by serializing our data structures as JSON strings and in a few cases returning a C-shaped struct by pointer. The procedure for returning, say, a bookmark from the user’s synced data looked like this:
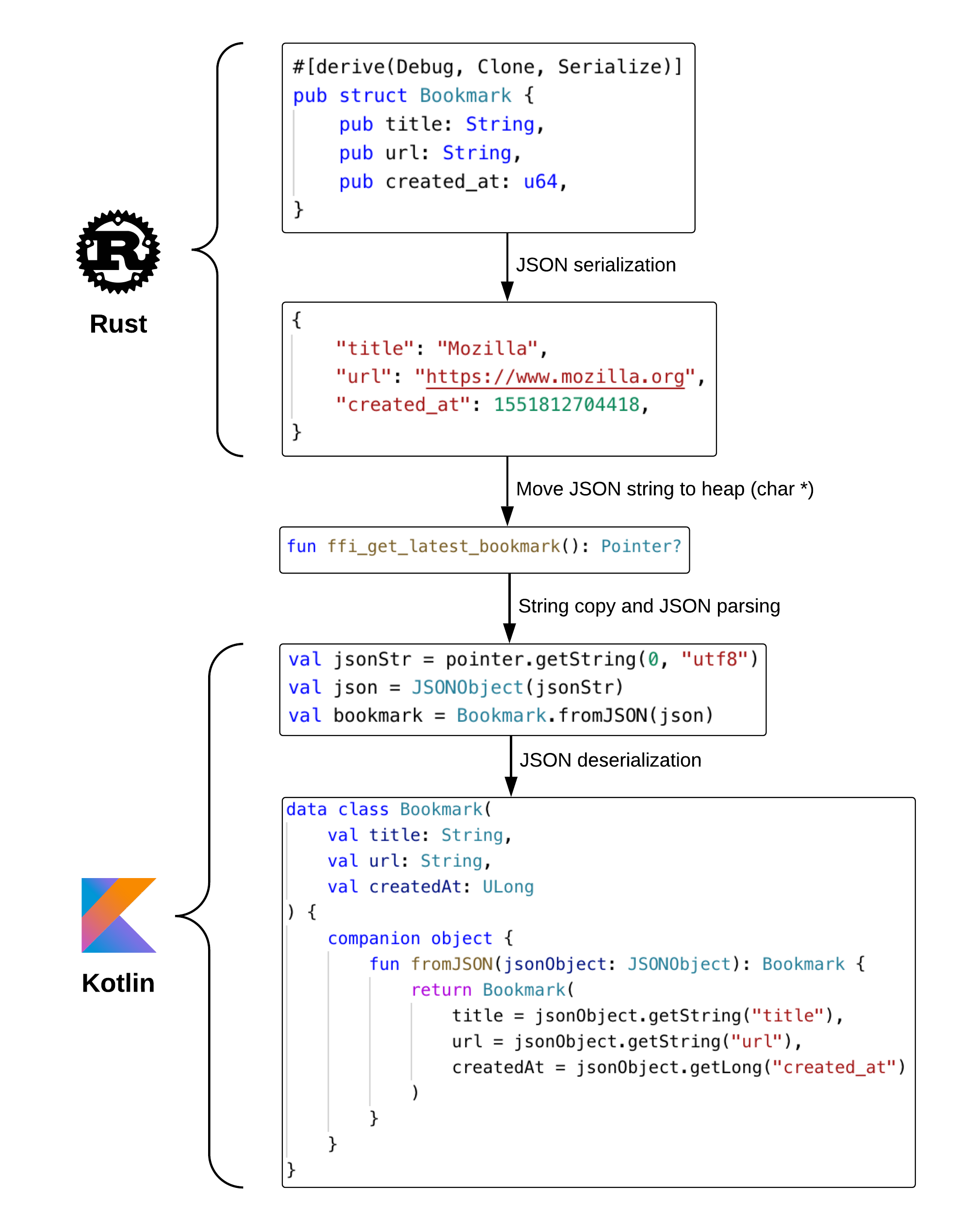
Returning Bookmark data from Rust to Kotlin using JSON (simplified)
So what’s the problem with this approach?
- Performance: JSON serializing and de-serializing is notoriously slow, because performance was not a primary design goal for the format. On top of that, an extra string copy happens on the Java layer since Rust strings are UTF-8 and Java strings are UTF-16-ish. At scale, it can introduce significant overhead.
- Complexity and safety: every data structure is manually parsed and deserialized from JSON strings. A data structure field modification on the Rust side must be reflected on the Kotlin side, or an exception will most likely occur.
- Even worse, in some cases we were not returning JSON strings but C-shaped Rust structs by pointer: forget to update the Structure Kotlin subclass or the Objective-C struct and you have a serious memory corruption on your hands.
We quickly realized there was probably a better and faster way that could be safer than our current solution.
Data serialization with Protocol Buffers v.2
Thankfully, there are many data serialization formats out there that aim to be fast. The ones with a schema language will even auto-generate data structures for you!
After some exploration, we ended up settling on Protocol Buffers version 2.
The —relative— safety comes from the automated generation of data structures in the languages we care about. There is only one source of truth—the .proto schema file—from which all our data classes are generated at build time, both on the Rust and consumer side.
protoc (the Protocol Buffers code generator) can emit code in more than 20 languages! On the Rust side, we use the prost crate which outputs very clean-looking structs by leveraging Rust derive macros.
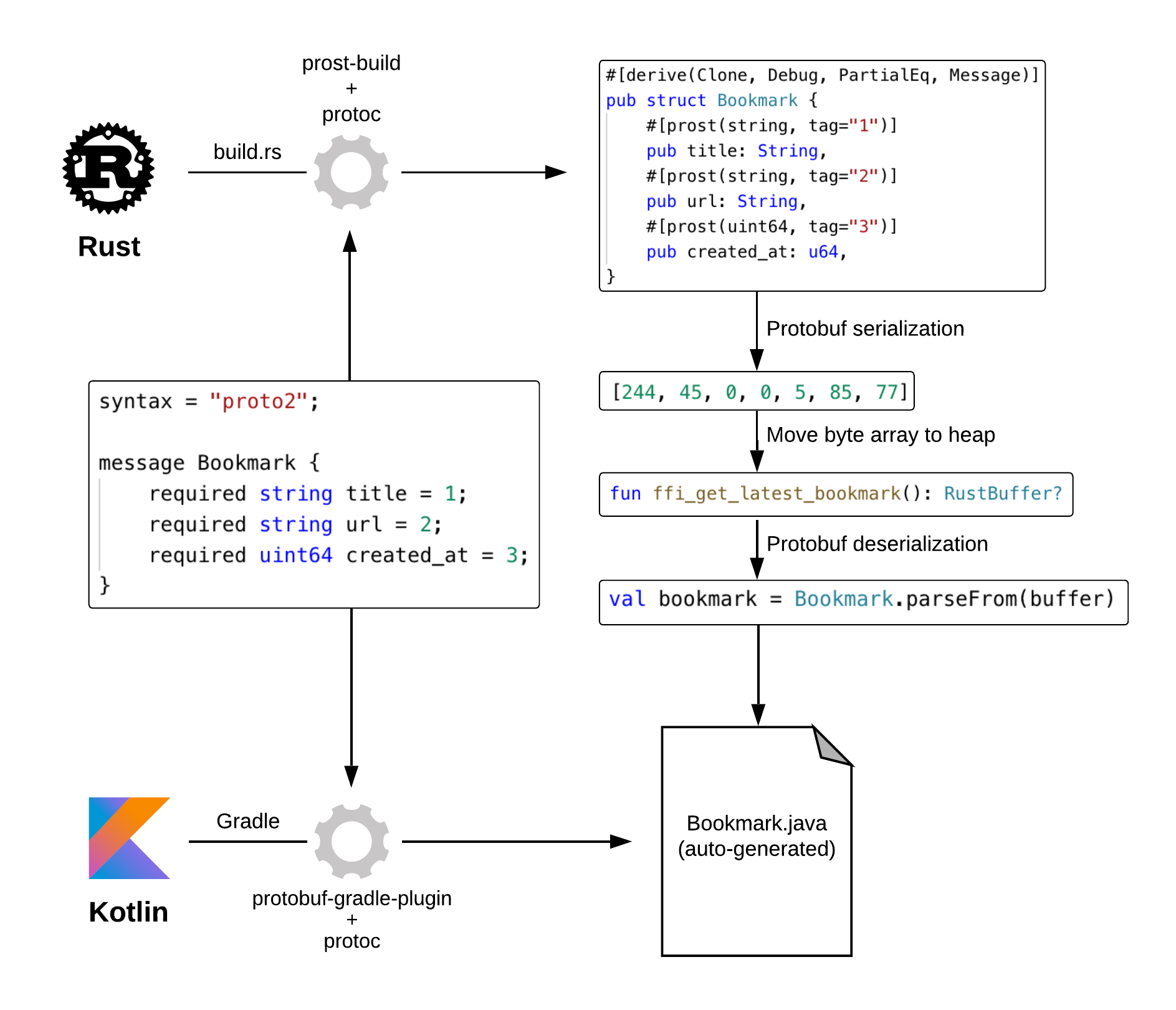
Returning Bookmark data from Rust to Kotlin using Protocol Buffers 2 (simplified)
And of course, on top of that, Protocol Buffers are faster than JSON.
There are a few downsides to this approach: it is more work to convert our internal types to the generated protobuf structs –e.g a url::Url has to be converted to a String first– whereas back when we were using serde-json serialization, any struct implementing serde::Serialize was a line away from being sent over the FFI barrier. It also adds one more step during our build process, although it was pretty easy to integrate.
One thing I ought to mention: Since we ship both the producer and consumer of these binary streams as a unit, we have the freedom to change our data exchange format transparently without affecting our Android and iOS consumers at all.
A look ahead
Looking forward, there’s probably a high-level system that could be used to exchange data over the FFI, maybe based on Rust macros. There’s also been talk about using FlatBuffers to squeeze out even more performance. In our case Protobufs provided the right trade-off between ease-of-use, performance, and relative safety.
So far, our components are present both on iOS, on Firefox and Lockbox, and on Lockbox Android, and will soon be in our new upcoming Android browser.
Firefox iOS has started to oxidize by replacing their password syncing engine with the one we built in Rust. The plan is to eventually do the same on Firefox Desktop as well.
If you are interested in helping us build the future of Firefox Sync and more, or simply following our progress, head to the application services Github repository.
7 comments