
Edit: Further algorithmic improvements yielded additional speedups over what is described here, for total speedups of up to 10.9x faster than the original implementation. Read about these extra gains in Speed Without Wizardry!
Tom Tromey and I have replaced the most performance-sensitive portions of the source-map JavaScript Library’s source map parser with Rust code that is compiled to WebAssembly. The WebAssembly is up to 5.89 times faster than the JavaScript implementation on realistic benchmarks operating on real world source maps. Additionally, performance is also more consistent: relative standard deviations decreased.
We removed JavaScript code that had been written in a convoluted and unidiomatic way in the name of performance, and replaced it with idiomatic Rust code that performs even better.
We hope that, by sharing our experience, we inspire others to follow suit and rewrite performance-sensitive JavaScript in Rust via WebAssembly.
- Background
- Parsing and Querying Source Maps in Rust
- Interfacing with JavaScript
- Benchmarks
- Conclusions and Future Work
Background
The Source Map Format
The source map format provides a bidirectional mapping between locations in some generated JavaScript code that was emitted by a compiler0, minifier, or package bundling tool back to locations in the original sources that a programmer authored. JavaScript developer tools use source maps to symbolicate backtraces, and to implement source-level stepping in debuggers. Source maps encode debug information similar to that found in DWARF’s .debug_line section.
A source map is a JSON object with a handful of fields. The "mappings" field is a string that makes up the bulk of the source map, and contains the bidirectional mappings between source and object locations.
We will describe the "mappings" string’s grammar in extended Backus-Naur form (EBNF).
Mappings are grouped by generated JavaScript line number, which is incremented every time a semicolon lays between individual mappings. When consecutive mappings are on the same generated JavaScript line, they are separated by a comma:
<mappings> = [ <generated-line> ] ';' <mappings>
| ''
;
<generated-line> = <mapping>
| <mapping> ',' <generated-line>
;
Each individual mapping has a location in the generated JavaScript, and optionally a location in the original source text, which might also contain an associated name:
<mapping> = <generated-column> [ <source> <original-line> <original-column> [ <name> ] ] ;
Every component of a mapping is a Variable Length Quantity (VLQ) encoded integer. Filenames and associated names are encoded as indices into side tables stored in other fields of the source map’s JSON object. Every value is relative to the last occurrence of its type, i.e. a given <source> value is the delta since the previous <source> value. These deltas tend to be smaller than their absolute values, which means they are more compact when encoded:
<generated-column> = <vlq> ;
<source> = <vlq> ;
<original-line> = <vlq> ;
<original-column> = <vlq> ;
<name> = <vlq> ;
Each character in a VLQ is drawn from a set of 64 printable ASCII characters comprising the upper- and lower-case letters, the decimal digits, and some symbols. Each character represents a particular 6-bit value. The most significant bit is set on all but the last character in the VLQ; the remaining five bits are prepended to the integer value represented.
Rather than attempting to translate this definition into EBNF, we provide pseudocode for parsing and decoding a single VLQ below:
constant SHIFT = 5
constant CONTINUATION_BIT = 1 << SHIFT
constant MASK = (1 << SHIFT) - 1
decode_vlq(input):
let accumulation = 0
let shift = 0
let next_digit_part_of_this_number = true;
while next_digit_part_of_this_number:
let [character, ...rest] = input
let digit = decode_base_64(character)
accumulation += (digit & MASK) << shift
shift += SHIFT;
next_digit_part_of_this_number = (digit & CONTINUATION_BIT) != 0
input = rest
let is_negative = accumulation & 1
let value = accumulation >> 1
if is_negative:
return (-value, input)
else:
return (value, input)
The source-map JavaScript Library
The source-map library is published on npm and maintained by the Firefox Developer Tools team at Mozilla. It is one of the most transitively depended-upon libraries by the JavaScript community, and is downloaded 10M times per week.
Like many software projects, the source-map library was written first for correctness, and then later modified to improve performance. By this time, it has seen a good amount of performance work.
When consuming source maps, the majority of time is spent parsing the "mappings" string and constructing a pair of arrays: one sorted by generated JavaScript location, the other sorted by original source location. Queries use binary search on the appropriate array. The parsing and sorting both happen lazily, and don’t occur until a particular query requires it. This allows a debugger to list sources, for example, without needing to parse and sort mappings. Once parsed and sorted, querying tends not to be a performance bottleneck.
The VLQ decoding function takes a string as input, parses and decodes a VLQ from the string, and returns a pair of the value and the rest of the input that was not consumed. This function was originally written in an idiomatic, referentially transparent style to return the pair as an Object literal with two properties:
function decodeVlqBefore(input) {
// ...
return { result, rest };
}
Returning a pair that way was found to be costly. JavaScript Just-in-Time (JIT) compilers’ optimized compilation tiers were unable to eliminate this allocation. Because the VLQ decoding routine is called frequently, this allocation was creating undue pressure on the garbage collector, leading to more frequent garbage collection pauses.
To remove the allocation, we modified the procedure to take a second parameter: an Object that gets mutated and serves as an out parameter. Rather than returning a freshly allocated Object, the out parameter’s properties are overwritten. This way, we could reuse the same object for every VLQ parse. This is less idiomatic, but much more performant:
function decodeVlqAfter(input, out) {
// ...
out.result = result;
out.rest = rest;
}
When reaching an unexpected end-of-string or an invalid base 64 character, the VLQ decoding function would throw an Error. We found that JavaScript JITs would emit faster code when we changed the single base 64 digit decoding function to return -1 on failure instead of throwing an Error. This is less idiomatic, but once again it improved performance.
When profiling with SpiderMonkey’s JITCoach prototype, we found that SpiderMonkey’s JIT was using slow-path polymorphic inline caches for Object property gets and sets on our mapping Objects. The JIT was not emitting the desired fast-path code with direct object slot accesses, because it was not detecting a common “shape” (or “hidden class”) shared by all mapping Objects. Some properties would be added in a different order, or omitted completely, for example, when there was no associated name for a mapping. By creating a constructor for mapping Objects that initialized every property we would ever use, we helped the JIT create a common shape for all mapping Objects. This resulted in another performance improvement:
function Mapping() {
this.generatedLine = 0;
this.generatedColumn = 0;
this.lastGeneratedColumn = null;
this.source = null;
this.originalLine = null;
this.originalColumn = null;
this.name = null;
}
When sorting the two mapping arrays, we use custom comparator functions. When the source-map library was first written, SpiderMonkey’s Array.prototype.sort was implemented in C++ for performance1. However, when sort is passed an explicit comparator function and a large array, the sorting code must call the comparator function many times. Calls from C++ to JavaScript are relatively expensive, so passing a custom comparator function made the sorts perform poorly.
To avoid this, we implemented our own Quicksort in JavaScript. This not only avoided the C++-to-JavaScript calls, but also let the JavaScript JITs inline the comparator function into the sorting function, enabling further optimizations. This brought us another large performance boost, and again made the code less idiomatic.
WebAssembly
WebAssembly is a new, low-level, architecture-independent byte code developed for the Web. It is designed for safe and efficient execution and compact binaries, and is developed in the open as a Web standard. It is supported by all major Web browsers.
WebAssembly exposes a stack machine that maps well onto modern processor architectures. Its instructions operate on a large, linear buffer of memory. It does not support garbage collection, although extending it to work with garbage-collected JavaScript objects is planned for the future. Control flow is structured, rather than allowing arbitrary jumps and labels. It is designed to be deterministic and consistent, even where different architectures diverge on edge cases, such as out-of-range shifts, overflows, and canonicalizing NaNs.
WebAssembly aims to match or beat native execution speed. It is currently within 1.5x native execution on most benchmarks.
Because of the lack of a garbage collector, languages that target WebAssembly are currently limited to languages without a runtime or garbage collector to speak of, unless the collector and runtime are also compiled to WebAssembly. That doesn’t happen in practice. Right now, the languages developers are actually compiling to WebAssembly are C, C++, and Rust.
Rust
Rust is a systems programming language that emphasizes safety and speed. It provides memory safety without relying on a garbage collector. Instead, it statically tracks ownership and borrowing of resources to determine where to emit code to run destructors or free memory.
Rust is in a great position for compiling to WebAssembly. Since Rust does not require garbage collection, Rust authors don’t have to jump through extra hoops to target WebAssembly. Rust has many of the goodies that Web developers have come to expect, and which C and C++ lack:
- Easy building, packaging, publishing, sharing, and documenting of libraries. Rust has
rustup,cargo, and the crates.io ecosystem; C and C++ don’t have any widely used equivalent. -
Memory safety. Not having to chase down memory corruption in
gdb. Rust prevents most of these pitfalls at compile time.
Parsing and Querying Source Maps in Rust
When we decided to rewrite the hot portions of source map parsing and querying in Rust, we had to decide where the boundary between JavaScript and the WebAssembly emitted by the Rust compiler would be. Crossing the boundary between JavaScript’s JITed code to WebAssembly and back currently imposes overhead similar to that of the C++-to-JavaScript calls we mentioned earlier.2 So it was important to place this boundary in so as to minimize the number of times we had to cross it.
A poor choice of where to place the boundary between WebAssembly and JavaScript would have been at the VLQ decoding function. The VLQ decoding function is invoked between one and four times for every mapping encoded in the "mappings" string, therefore we would have to cross the JavaScript-to-WebAssembly boundary that many times during parsing.
Instead, we decided to parse the whole "mappings" string in Rust/WebAssembly, and then keep the parsed data there. The WebAssembly heap owns the parsed data in its queryable form. This means that we never have to copy the data out of the WebAssembly heap, which would involve crossing the JavaScript/WebAssembly boundary more often. Instead, we only cross that boundary once each way for every query, plus once each way for every mapping that is a result of that query. Queries tend to produce a single result, or perhaps a handful.
To have confidence that our Rust implementation was correct, not only did we ensure that our new implementation passed the source-map library’s existing test suite, but we also wrote a suite of quickcheck property tests. These tests construct random "mappings" input strings, parse them, and then assert that various properties hold.
Base 64 Variable Length Quantities
The first step to parsing a source map’s mappings is decoding VLQs. We implemented a vlq library in Rust and published it to crates.io.
The decode64 function decodes a single base 64 digit. It uses pattern matching and the idiomatic Result-style error handling.
A Result<T, E> is either Ok(v), indicating that the operation succeeded and produced the value v of type T, or Err(error), indicating that the operation failed, with the value error of type E providing the details. The decode64 function’s return type Result<u8, Error> indicates that it returns a u8 value on success, or a vlq::Error value on failure:
fn decode64(input: u8) -> Result<u8, Error> {
match input {
b'A'...b'Z' => Ok(input - b'A'),
b'a'...b'z' => Ok(input - b'a' + 26),
b'0'...b'9' => Ok(input - b'0' + 52),
b'+' => Ok(62),
b'/' => Ok(63),
_ => Err(Error::InvalidBase64(input)),
}
}
With the decode64 function in hand, we can decode whole VLQ values. The decode function takes a mutable reference to an iterator of bytes as input, consumes as many bytes as it needs to decode the VLQ, and finally returns a Result of the decoded value:
pub fn decode<B>(input: &mut B) -> Result<i64>
where
B: Iterator<Item = u8>,
{
let mut accum: u64 = 0;
let mut shift = 0;
let mut keep_going = true;
while keep_going {
let byte = input.next().ok_or(Error::UnexpectedEof)?;
let digit = decode64(byte)?;
keep_going = (digit & CONTINUED) != 0;
let digit_value = ((digit & MASK) as u64)
.checked_shl(shift as u32)
.ok_or(Error::Overflow)?;
accum = accum.checked_add(digit_value).ok_or(Error::Overflow)?;
shift += SHIFT;
}
let abs_value = accum / 2;
if abs_value > (i64::MAX as u64) {
return Err(Error::Overflow);
}
// The low bit holds the sign.
if (accum & 1) != 0 {
Ok(-(abs_value as i64))
} else {
Ok(abs_value as i64)
}
}
Unlike the JavaScript code it is replacing, this code does not sacrifice idiomatic error handling for performance. Idiomatic error handling is performant, and does not involve boxing values on the heap or unwinding the stack.
The "mappings" String
We begin by defining some small helper functions. The is_mapping_separator predicate function returns true if the given byte is a separator between mappings, and false if it is not. There is a nearly identical JavaScript function:
#[inline]
fn is_mapping_separator(byte: u8) -> bool {
byte == b';' || byte == b','
}
Next, we define a helper function for reading a single VLQ delta value and adding it to the previous value. The JavaScript does not have an equivalent function, and instead repeats this code each time it wants to read a VLQ delta. JavaScript does not let us control how our parameters are represented in memory, but Rust does. We cannot pass a reference to a number in a zero-cost manner with JavaScript. We could pass a reference to an Object with a number property or we could close over the number’s variable in a local closure function, but both of these solutions have associated runtime costs:
#[inline]
fn read_relative_vlq<B>(
previous: &mut u32,
input: &mut B,
) -> Result<(), Error>
where
B: Iterator<Item = u8>,
{
let decoded = vlq::decode(input)?;
let (new, overflowed) = (*previous as i64).overflowing_add(decoded);
if overflowed || new > (u32::MAX as i64) {
return Err(Error::UnexpectedlyBigNumber);
}
if new < 0 {
return Err(Error::UnexpectedNegativeNumber);
}
*previous = new as u32;
Ok(())
}
All in all, the Rust implementation of "mappings" parsing is quite similar to the JavaScript implementation it replaces. However, with the Rust, we have control over what is or isn’t boxed, whereas in the JavaScript, we do not. Every single parsed mapping Object is boxed in the JavaScript implementation. Much of the Rust implementation’s advantage stems from avoiding these allocations and their associated garbage collections:
pub fn parse_mappings(input: &[u8]) -> Result<Mappings, Error> {
let mut generated_line = 0;
let mut generated_column = 0;
let mut original_line = 0;
let mut original_column = 0;
let mut source = 0;
let mut name = 0;
let mut mappings = Mappings::default();
let mut by_generated = vec![];
let mut input = input.iter().cloned().peekable();
while let Some(byte) = input.peek().cloned() {
match byte {
b';' => {
generated_line += 1;
generated_column = 0;
input.next().unwrap();
}
b',' => {
input.next().unwrap();
}
_ => {
let mut mapping = Mapping::default();
mapping.generated_line = generated_line;
read_relative_vlq(&mut generated_column, &mut input)?;
mapping.generated_column = generated_column as u32;
let next_is_sep = input.peek()
.cloned()
.map_or(true, is_mapping_separator);
mapping.original = if next_is_sep {
None
} else {
read_relative_vlq(&mut source, &mut input)?;
read_relative_vlq(&mut original_line, &mut input)?;
read_relative_vlq(&mut original_column, &mut input)?;
let next_is_sep = input.peek()
.cloned()
.map_or(true, is_mapping_separator);
let name = if next_is_sep {
None
} else {
read_relative_vlq(&mut name, &mut input)?;
Some(name)
};
Some(OriginalLocation {
source,
original_line,
original_column,
name,
})
};
by_generated.push(mapping);
}
}
}
quick_sort::<comparators::ByGeneratedLocation, _>(&mut by_generated);
mappings.by_generated = by_generated;
Ok(mappings)
}
Finally, we still use a custom Quicksort implementation in the Rust code, and this is the only unidiomatic thing about the Rust code. We found that although the standard library’s built-in sorting is much faster when targeting native code, our custom Quicksort is faster when targeting WebAssembly. (This is surprising, but we have not investigated why it is so.)
Interfacing with JavaScript
The WebAssembly foreign function interface (FFI) is constrained to scalar values, so any function exposed from Rust to JavaScript via WebAssembly may only use scalar value types as parameters and return types. Therefore, the JavaScript code must ask the Rust to allocate a buffer with space for the "mappings" string and return a pointer to that buffer. Next, the JavaScript must copy the "mappings" string into that buffer, which it can do without crossing the FFI boundary because it has write access to the whole WebAssembly linear memory. After the buffer is initialized, the JavaScript calls the parse_mappings function and is returned a pointer to the parsed mappings. Then, the JavaScript can perform any number of queries through the WebAssembly API, passing in the pointer to the parsed mappings when doing so. Finally, when no more queries will be made, the JavaScript tells the WebAssembly to free the parsed mappings.
Exposing WebAssembly APIs from Rust
All the WebAssembly APIs we expose live in a small glue crate that wraps the source-map-mappings crate. This separation is useful because it allows us to test the source-map-mappings crate with our native host target, and only compile the WebAssembly glue when targeting WebAssembly.
In addition to the constraints of what types can cross the FFI boundary, each exported function requires that
- it has the
#[no_mangle]attribute so that it is not name-mangled, and JavaScript can easily call it, and - it is marked
extern "C"so that it is publicly exported in the final.wasmfile.
Unlike the core library, this glue code that exposes functionality to JavaScript via WebAssembly does, by necessity, frequently use unsafe. Calling extern functions and using pointers received from across an FFI boundary is always unsafe, because the Rust compiler cannot verify the safety of the other side. Ultimately this is less concerning with WebAssembly than it might be with other targets — the worst we can do is trap (which causes an Error to be raised on the JavaScript side) or return an incorrect answer. Much tamer than the worst case scenarios with native binaries where executable memory is in the same address space as writable memory, and an attacker can trick the program into jumping to memory where they’ve inserted some shell code.
The simplest function we export is the function to get the last error that occurred in the library. This provides similar functionality as errno from libc, and is called by JavaScript when some API call fails and the JavaScript would like to know what kind of failure it was. We always maintain the most recent error in a global, and this function retrieves that error value:
static mut LAST_ERROR: Option<Error> = None;
#[no_mangle]
pub extern "C" fn get_last_error() -> u32 {
unsafe {
match LAST_ERROR {
None => 0,
Some(e) => e as u32,
}
}
}
The first interaction between JavaScript and Rust is allocating a buffer with space to hold the "mappings" string. We desire an owned, contiguous chunk of u8s, which suggests using Vec<u8>, but we want to expose a single pointer to JavaScript. A single pointer can cross the FFI boundary, and is easier to wrangle on the JavaScript side. We can either add a layer of indirection with Box<Vec<u8>> or we can save the extra data needed to reconstruct the vector on the side. We choose the latter approach.
A vector is a triple of
- a pointer to the heap-allocated elements,
- the capacity of that allocation, and
- the length of the initialized elements.
Since we are only exposing the pointer to the heap-allocated elements to JavaScript, we need a way to save the length and capacity so we can reconstruct the Vec on demand. We allocate two extra words of space and store the length and capacity in the first two words of the heap elements. Then we give JavaScript a pointer to the space just after those extra words:
#[no_mangle]
pub extern "C" fn allocate_mappings(size: usize) -> *mut u8 {
// Make sure that we don't lose any bytes from size in the remainder.
let size_in_units_of_usize = (size + mem::size_of::<usize>() - 1)
/ mem::size_of::<usize>();
// Make room for two additional `usize`s: we'll stuff capacity and
// length in there.
let mut vec: Vec<usize> = Vec::with_capacity(size_in_units_of_usize + 2);
// And do the stuffing.
let capacity = vec.capacity();
vec.push(capacity);
vec.push(size);
// Leak the vec's elements and get a pointer to them.
let ptr = vec.as_mut_ptr();
debug_assert!(!ptr.is_null());
mem::forget(vec);
// Advance the pointer past our stuffed data and return it to JS,
// so that JS can write the mappings string into it.
let ptr = ptr.wrapping_offset(2) as *mut u8;
assert_pointer_is_word_aligned(ptr);
ptr
}
After initializing the buffer for the "mappings" string, JavaScript passes ownership of the buffer to parse_mappings, which parses the string into a queryable structure. A pointer to the queryable Mappings structure is returned, or NULL if there was some kind of parse failure.
The first thing that parse_mappings must do is recover the Vec‘s length and capacity. Next, it constructs a slice of the "mappings" string data, constrains the lifetime of the slice to the current scope to double check that we don’t access the slice again after its deallocated, and call into our library’s "mappings" string parsing function. Regardless whether parsing succeeded or not, we deallocate the buffer holding the "mappings" string, and return a pointer to the parsed structure or save any error that may have occurred and return NULL.
/// Force the `reference`'s lifetime to match the `scope`'s
/// lifetime. Certain `unsafe` operations, such as dereferencing raw
/// pointers, return references with un-constrained lifetimes, and we
/// use this function to ensure we can't accidentally use the
/// references after they become invalid.
#[inline]
fn constrain<'a, T>(_scope: &'a (), reference: &'a T) -> &'a T
where
T: ?Sized
{
reference
}
#[no_mangle]
pub extern "C" fn parse_mappings(mappings: *mut u8) -> *mut Mappings {
assert_pointer_is_word_aligned(mappings);
let mappings = mappings as *mut usize;
// Unstuff the data we put just before the pointer to the mappings
// string.
let capacity_ptr = mappings.wrapping_offset(-2);
debug_assert!(!capacity_ptr.is_null());
let capacity = unsafe { *capacity_ptr };
let size_ptr = mappings.wrapping_offset(-1);
debug_assert!(!size_ptr.is_null());
let size = unsafe { *size_ptr };
// Construct the input slice from the pointer and parse the mappings.
let result = unsafe {
let input = slice::from_raw_parts(mappings as *const u8, size);
let this_scope = ();
let input = constrain(&this_scope, input);
source_map_mappings::parse_mappings(input)
};
// Deallocate the mappings string and its two prefix words.
let size_in_usizes = (size + mem::size_of::<usize>() - 1) / mem::size_of::<usize>();
unsafe {
Vec::<usize>::from_raw_parts(capacity_ptr, size_in_usizes + 2, capacity);
}
// Return the result, saving any errors on the side for later inspection by
// JS if required.
match result {
Ok(mappings) => Box::into_raw(Box::new(mappings)),
Err(e) => {
unsafe {
LAST_ERROR = Some(e);
}
ptr::null_mut()
}
}
}
When we run queries, we need a way to translate the results across the FFI boundary. The results of a query are either a single Mapping or set of many Mappings, and a Mapping can’t cross the FFI boundary as-is unless we box it. We do not wish to box Mappings since we would also need to provide getters for each of its fields, causing code bloat on top of the costs of allocation and indirection. Our solution is to call an imported function for each Mapping query result.
The mappings_callback is an extern function without definition, which translates to an imported function in WebAssembly that the JavaScript must provide when instantiating the WebAssembly module. The mappings_callback takes a Mapping that is exploded into its member parts: each field in a transitively flattened Mapping is translated into a parameter so that it can cross the FFI boundary. For Option<T> members, we add a bool parameter that serves as a discriminant, determining whether the Option<T> is Some or None, and therefore whether the following T parameter is valid or garbage:
extern "C" {
fn mapping_callback(
// These two parameters are always valid.
generated_line: u32,
generated_column: u32,
// The `last_generated_column` parameter is only valid if
// `has_last_generated_column` is `true`.
has_last_generated_column: bool,
last_generated_column: u32,
// The `source`, `original_line`, and `original_column`
// parameters are only valid if `has_original` is `true`.
has_original: bool,
source: u32,
original_line: u32,
original_column: u32,
// The `name` parameter is only valid if `has_name` is `true`.
has_name: bool,
name: u32,
);
}
#[inline]
unsafe fn invoke_mapping_callback(mapping: &Mapping) {
let generated_line = mapping.generated_line;
let generated_column = mapping.generated_column;
let (
has_last_generated_column,
last_generated_column,
) = if let Some(last_generated_column) = mapping.last_generated_column {
(true, last_generated_column)
} else {
(false, 0)
};
let (
has_original,
source,
original_line,
original_column,
has_name,
name,
) = if let Some(original) = mapping.original.as_ref() {
let (
has_name,
name,
) = if let Some(name) = original.name {
(true, name)
} else {
(false, 0)
};
(
true,
original.source,
original.original_line,
original.original_column,
has_name,
name,
)
} else {
(
false,
0,
0,
0,
false,
0,
)
};
mapping_callback(
generated_line,
generated_column,
has_last_generated_column,
last_generated_column,
has_original,
source,
original_line,
original_column,
has_name,
name,
);
}
All of the exported query functions have a similar structure. They begin by converting a raw *mut Mappings pointer into an &mut Mappings mutable reference. The &mut Mappings lifetime is constrained to the current scope to enforce that it is only used in this function call, and not saved away somewhere where it might be used after it is deallocated. Next, the exported query function forwards the query to the corresponding Mappings method. For each resulting Mapping, the exported function invokes the mapping_callback.
A typical example is the exported all_generated_locations_for query function, which wraps the Mappings::all_generated_locations_for method, and finds all the mappings corresponding to the given original source location:
#[inline]
unsafe fn mappings_mut<'a>(
_scope: &'a (),
mappings: *mut Mappings,
) -> &'a mut Mappings {
mappings.as_mut().unwrap()
}
#[no_mangle]
pub extern "C" fn all_generated_locations_for(
mappings: *mut Mappings,
source: u32,
original_line: u32,
has_original_column: bool,
original_column: u32,
) {
let this_scope = ();
let mappings = unsafe { mappings_mut(&this_scope, mappings) };
let original_column = if has_original_column {
Some(original_column)
} else {
None
};
let results = mappings.all_generated_locations_for(
source,
original_line,
original_column,
);
for m in results {
unsafe {
invoke_mapping_callback(m);
}
}
}
Finally, when the JavaScript is finished querying the Mappings, it must deallocate them with the exported free_mappings function:
#[no_mangle]
pub extern "C" fn free_mappings(mappings: *mut Mappings) {
unsafe {
Box::from_raw(mappings);
}
}
Compiling Rust into .wasm Files
The addition of the wasm32-unknown-unknown target makes compiling Rust into WebAssembly possible, and rustup makes installing a Rust compiler toolchain targeting wasm32-unknown-unknown easy:
$ rustup update
$ rustup target add wasm32-unknown-unknown
Now that we have a wasm32-unknown-unknown compiler, the only difference between building for our host platform and WebAssembly is a --target flag:
$ cargo build --release --target wasm32-unknown-unknown
The resulting .wasm file is at target/wasm32-unknown-unknown/release/source_map_mappings_wasm_api.wasm.
Although we now have a working .wasm file, we are not finished: this .wasm file is still much larger than it needs to be. To produce the smallest .wasm file we can, we leverage the following tools:
wasm-gc, which is like a linker’s--gc-sectionsflag that removes unused object file sections, but for.wasmfiles instead of ELF, Mach-O, etc. object files. It finds all functions that are not transitively reachable from an exported function and removes them from the.wasmfile.-
wasm-snip, which is used to replace a WebAssembly function’s body with a singleunreachableinstruction. This is useful for manually removing functions that will never be called at runtime, but which the compiler andwasm-gccouldn’t statically prove were unreachable. Snipping a function can make other functions statically unreachable, so it makes sense to runwasm-gcagain afterwards. -
wasm-opt, which runsbinaryen‘s optimization passes over a.wasmfile, shrinking its size and improving its runtime performance. Eventually, when LLVM’s WebAssembly backend matures, this may no longer be necessary.
Our post-build pipeline goes wasm-gc → wasm-snip → wasm-gc → wasm-opt.
Using WebAssembly APIs in JavaScript
The first concern when using WebAssembly in JavaScript is how to load the .wasm files. The source-map library is primarily used in three environments:
- Node.js
- The Web
- Inside Firefox Developer Tools
Different environments can have different methods for loading a .wasm file’s bytes into an ArrayBuffer that can then be compiled by the JavaScript runtime. On the Web and inside Firefox, we can use the standard fetch API to make an HTTP request to load the .wasm file. It is the library consumer’s responsibility to provide a URL pointing to the .wasm file before parsing any source maps. When used with Node.js, the library uses the fs.readFile API to read the .wasm file from disk. No initialization is required before parsing any source maps in this scenario. We provide a uniform interface regardless which environment the library is loaded in by using feature detection to select the correct .wasm loading implementation.
When compiling and instantiating the WebAssembly module, we must provide the mapping_callback. This callback cannot change across the lifetime of the instantiated WebAssembly module, but depending on what kind of query we are performing, we want to do different things with the resulting mappings. So the actual mapping_callback we provide is only responsible for translating the exploded mapping members into a structured object and then trampolining that result to a closure function that we set depending on what query we are running.
let currentCallback = null;
// ...
WebAssembly.instantiate(buffer, {
env: {
mapping_callback: function (
generatedLine,
generatedColumn,
hasLastGeneratedColumn,
lastGeneratedColumn,
hasOriginal,
source,
originalLine,
originalColumn,
hasName,
name
) {
const mapping = new Mapping;
mapping.generatedLine = generatedLine;
mapping.generatedColumn = generatedColumn;
if (hasLastGeneratedColumn) {
mapping.lastGeneratedColumn = lastGeneratedColumn;
}
if (hasOriginal) {
mapping.source = source;
mapping.originalLine = originalLine;
mapping.originalColumn = originalColumn;
if (hasName) {
mapping.name = name;
}
}
currentCallback(mapping);
}
}
})
To make setting and unsetting the currentCallback ergonomic, we define a withMappingCallback helper that takes two functions: one to set as the currentCallback, and another to invoke immediately. Once the second function’s execution finishes, we reset the currentCallback to null. This is the JavaScript equivalent of RAII:
function withMappingCallback(mappingCallback, f) {
currentCallback = mappingCallback;
try {
f();
} finally {
currentCallback = null;
}
}
Recall that JavaScript’s first task, when parsing a source map, is to tell the WebAssembly to allocate space for the "mappings" string, and then copy the string into the allocated buffer:
const size = mappingsString.length;
const mappingsBufPtr = this._wasm.exports.allocate_mappings(size);
const mappingsBuf = new Uint8Array(
this._wasm.exports.memory.buffer,
mappingsBufPtr,
size
);
for (let i = 0; i < size; i++) {
mappingsBuf[i] = mappingsString.charCodeAt(i);
}
Once JavaScript has initialized the buffer, it calls the exported parse_mappings WebAssembly function and translates any failures into an Error that gets thrown.
const mappingsPtr = this._wasm.exports.parse_mappings(mappingsBufPtr);
if (!mappingsPtr) {
const error = this._wasm.exports.get_last_error();
let msg = `Error parsing mappings (code ${error}): `;
// XXX: keep these error codes in sync with `fitzgen/source-map-mappings`.
switch (error) {
case 1:
msg += "the mappings contained a negative line, column, source index or name index";
break;
case 2:
msg += "the mappings contained a number larger than 2**32";
break;
case 3:
msg += "reached EOF while in the middle of parsing a VLQ";
break;
case 4:
msg += "invalid base 64 character while parsing a VLQ";
break
default:
msg += "unknown error code";
break;
}
throw new Error(msg);
}
this._mappingsPtr = mappingsPtr;
The various query methods that call into WebAssembly have similar structure, just like the exported functions on the Rust side do. They validate query parameters, set up a temporary mappings callback closure with withMappingCallback that aggregates results, calls into WebAssembly, and then returns the results.
Here is what allGeneratedPositionsFor looks like in JavaScript:
BasicSourceMapConsumer.prototype.allGeneratedPositionsFor = function ({
source,
line,
column,
}) {
const hasColumn = column === undefined;
column = column || 0;
source = this._findSourceIndex(source);
if (source < 0) {
return [];
}
if (originalLine < 1) {
throw new Error("Line numbers must be >= 1");
}
if (originalColumn < 0) {
throw new Error("Column numbers must be >= 0");
}
const results = [];
this._wasm.withMappingCallback(
m => {
let lastColumn = m.lastGeneratedColumn;
if (this._computedColumnSpans && lastColumn === null) {
lastColumn = Infinity;
}
results.push({
line: m.generatedLine,
column: m.generatedColumn,
lastColumn,
});
}, () => {
this._wasm.exports.all_generated_locations_for(
this._getMappingsPtr(),
source,
line,
hasColumn,
column
);
}
);
return results;
};
When JavaScript is done querying the source map, the library consumer should call SourceMapConsumer.prototype.destroy which then calls into the exported free_mappings WebAssembly function:
BasicSourceMapConsumer.prototype.destroy = function () {
if (this._mappingsPtr !== 0) {
this._wasm.exports.free_mappings(this._mappingsPtr);
this._mappingsPtr = 0;
}
};
Benchmarks
All tests were performed on a MacBook Pro from mid 2014 with a 2.8 GHz Intel Core i7 processor and 16 GB 1600 MHz DDR3 memory. The laptop was plugged into power for every test, and the benchmark Webpage was refreshed between tests. The tests were performed in Chrome Canary 65.0.3322.0, Firefox Nightly 59.0a1 (2018-01-15), and Safari 11.0.2 (11604.4.7.1.6)3. For each benchmark, to warm up the browser’s JIT compiler, we performed five iterations before collecting timings. After warm up, we recorded timings for 100 iterations.
We used a variety of input source maps with our benchmarks. We used three source maps found in the wild of varying sizes:
- The source map for the minified-to-unminified versions of the original JavaScript implementation of the
source-maplibrary. This source map is created by UglifyJS and its"mappings"string is 30,081 characters long. -
The latest Angular.JS’s minified-to-unminified source map. This source map’s
"mappings"string is 391,473 characters long. -
The Scala.JS runtime’s Scala-to-JavaScript source map. This source map is the largest, and its
"mappings"string is 14,964,446 characters long.
Additionally, we augmented the input set with two more artificially constructed source maps:
- The Angular.JS source map inflated to ten times its original size. This results in a
"mappings"string of size 3,914,739. -
The Scala.JS source map inflated to twice its original size. This results in a
"mappings"string of size 29,928,893. For this input source map, we only collected 40 iterations on each benchmark.
Astute readers will have noticed an extra 9 and 1 characters in the inflated source maps’ sizes respectively. These are from the ; separator characters between each copy of the original "mappings" string when gluing them together to create the inflated version.
We will pay particular attention to the Scala.JS source map. It is the largest non-artificial source map we tested. Additionally, it is the largest source map for which we have measurements for all combinations of browser and library implementation. There is no data for the largest input (the twice inflated Scala.JS source map) on Chrome. With the JavaScript implementation, we were unable to take any measurements with this combination because none of the benchmarks could complete without the tab’s content process crashing. With the WebAssembly implementation, Chrome would erroneously throw RuntimeError: memory access out of bounds. Using Chrome’s debugger, the supposed out-of-bounds access was happening in an instruction sequence that does not exist in the .wasm file. All other browser’s WebAssembly implementations successfully ran the benchmark with this input, so I am inclined to believe it is a bug in the Chrome implementation.
For all benchmarks, lower values are better.
Setting a Breakpoint for the First Time
The first benchmark simulates a stepping debugger setting a breakpoint on some line in the original source for the first time. This requires that the source map’s "mappings" string is parsed, and that the parsed mappings are sorted by their original source locations so we can binary search to the breakpoint’s line’s mappings. The query returns every generated JavaScript location that corresponds to any mapping on the original source line.
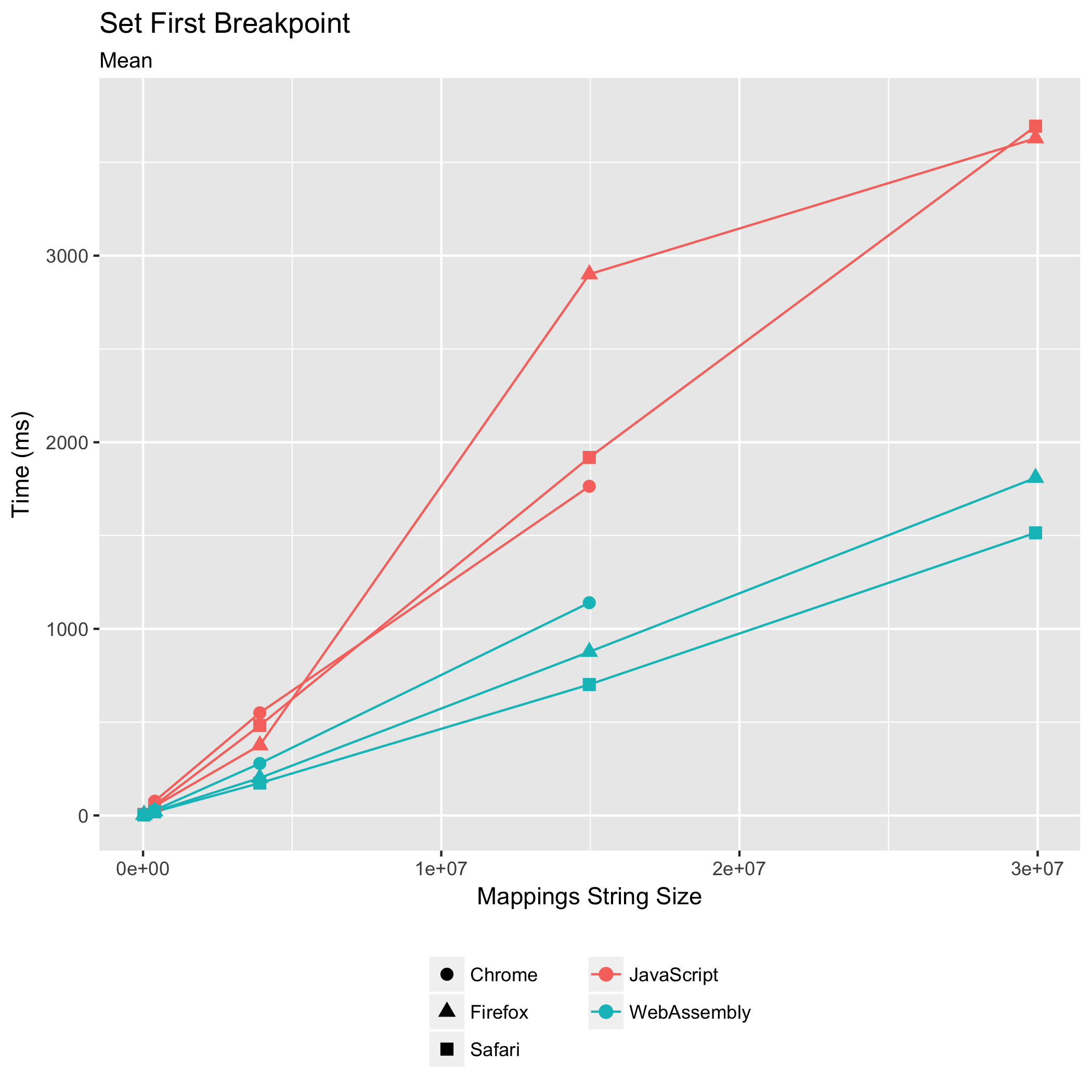
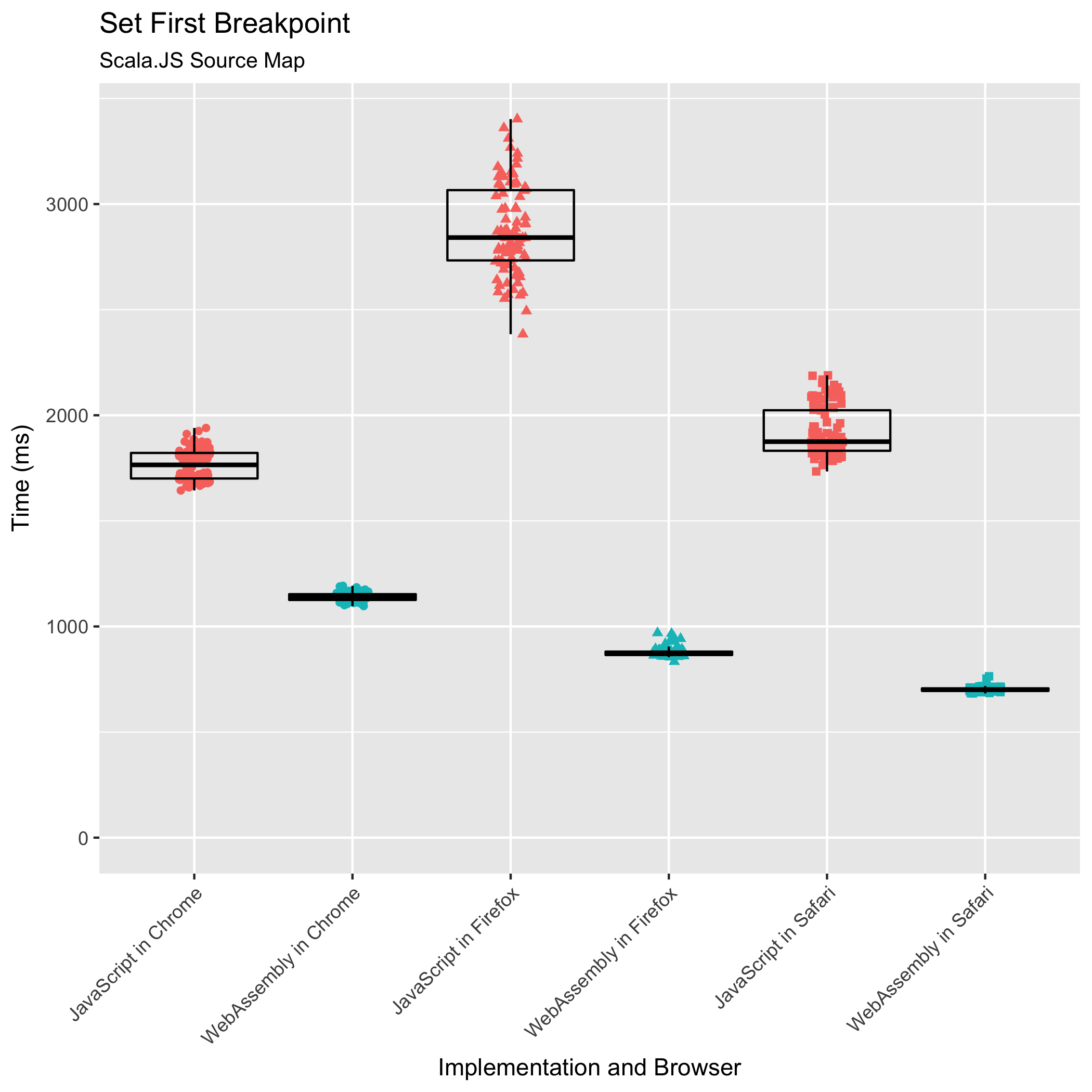
The WebAssembly implementation outperforms its JavaScript counterpart in all browsers. For the Scala.JS source map, the WebAssembly implementation takes 0.65x the amount of time its JavaScript counterpart takes in Chrome, 0.30x in Firefox, and 0.37x in Safari. The WebAssembly implementation is fastest in Safari, taking 702ms on average compared to Chrome’s 1140ms and Firefox’s 877ms.
Furthermore, the relative standard deviation of the WebAssembly implementation is more narrow than the JavaScript implementation, particularly in Firefox. For the Scala.JS source map with the JavaScript implementation, Chrome’s relative standard deviation is ±4.07%, Firefox’s is ±10.52%, and Safari’s is ±6.02%. In WebAssembly, the spreads shrink down to ±1.74% in Chrome, ±2.44% in Firefox, and ±1.58% in Safari.
Pausing at an Exception for the First Time
The second benchmark exercises the code path for the first time that a generated JavaScript location is used to look up its corresponding original source location. This happens when a stepping debugger pauses at an uncaught exception originating from within the generated JavaScript code, when a console message is logged from within the generated JavaScript code, or when stepping into the generated JavaScript code from some other JavaScript source.
To translate a generated JavaScript location into an original source location, the "mappings" string must be parsed. The parsed mappings must then be sorted by generated JavaScript location, so that we can binary search for the closest mapping, and finally that closest mapping’s original source location is returned.
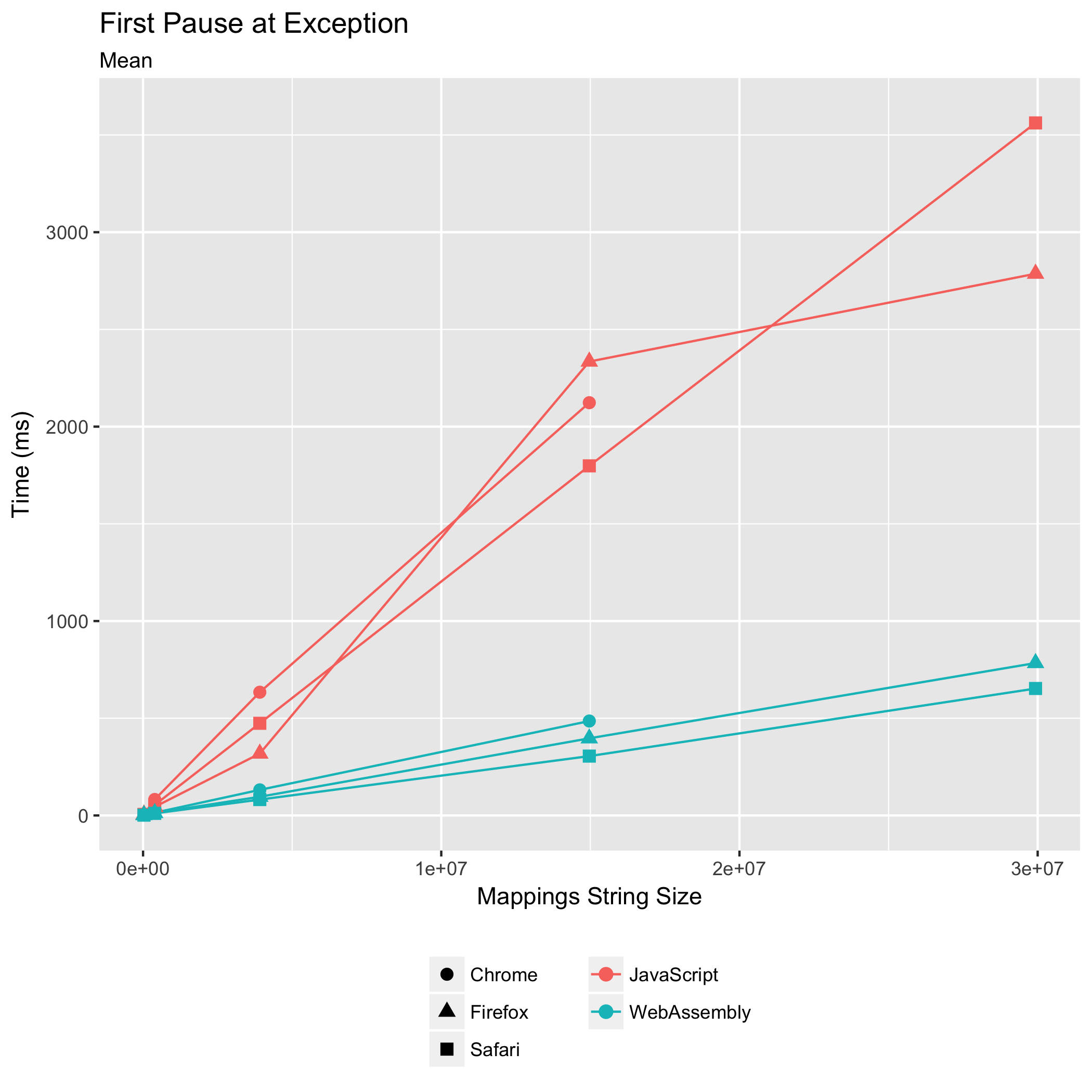
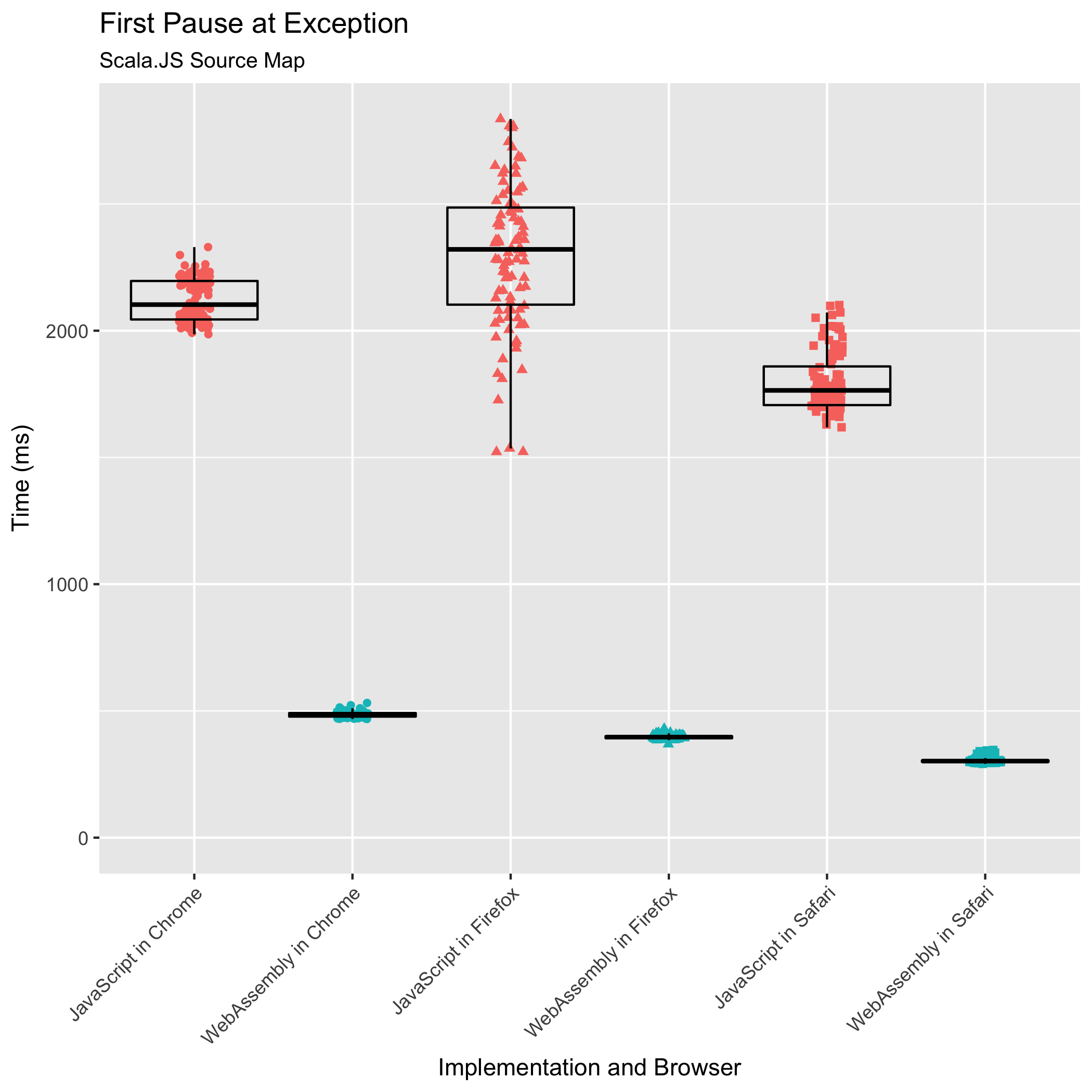
Once again, the WebAssembly implementation outperforms the JavaScript implementation in all browsers — by an even larger lead this time. With the Scala.JS source map, in Chrome, the WebAssembly implementation takes 0.23x the amount time that the JavaScript implementation takes. In both Firefox and Safari, the WebAssembly takes 0.17x the time the JavaScript takes. Once more, Safari runs the WebAssembly fastest (305ms), followed by Firefox (397ms), and then Chrome (486ms).
The WebAssembly implementation is also less noisy than the JavaScript implementation again. The relative standard deviations fell from ±4.04% to 2.35±% in Chrome, from ±13.75% to ±2.03% in Firefox, and from ±6.65% to ±3.86% in Safari for the Scala.JS source map input.
Subsequent Breakpoints and Pauses at Exceptions
The third and fourth benchmarks observe the time it takes to set subsequent breakpoints after the first one, or to pause at subsequent uncaught exceptions, or to translate subsequent logged messages’ locations. Historically, these operations have never been a performance bottleneck: the expensive part is the initial "mappings" string parse and construction of queryable data structures (the sorted arrays).
Nevertheless, we want to make sure it stays that way: we don’t want these operations to suddenly become costly.
Both of these benchmarks are measuring the time it takes to binary search for the closest mapping to the target location and returning that mapping’s co-location.
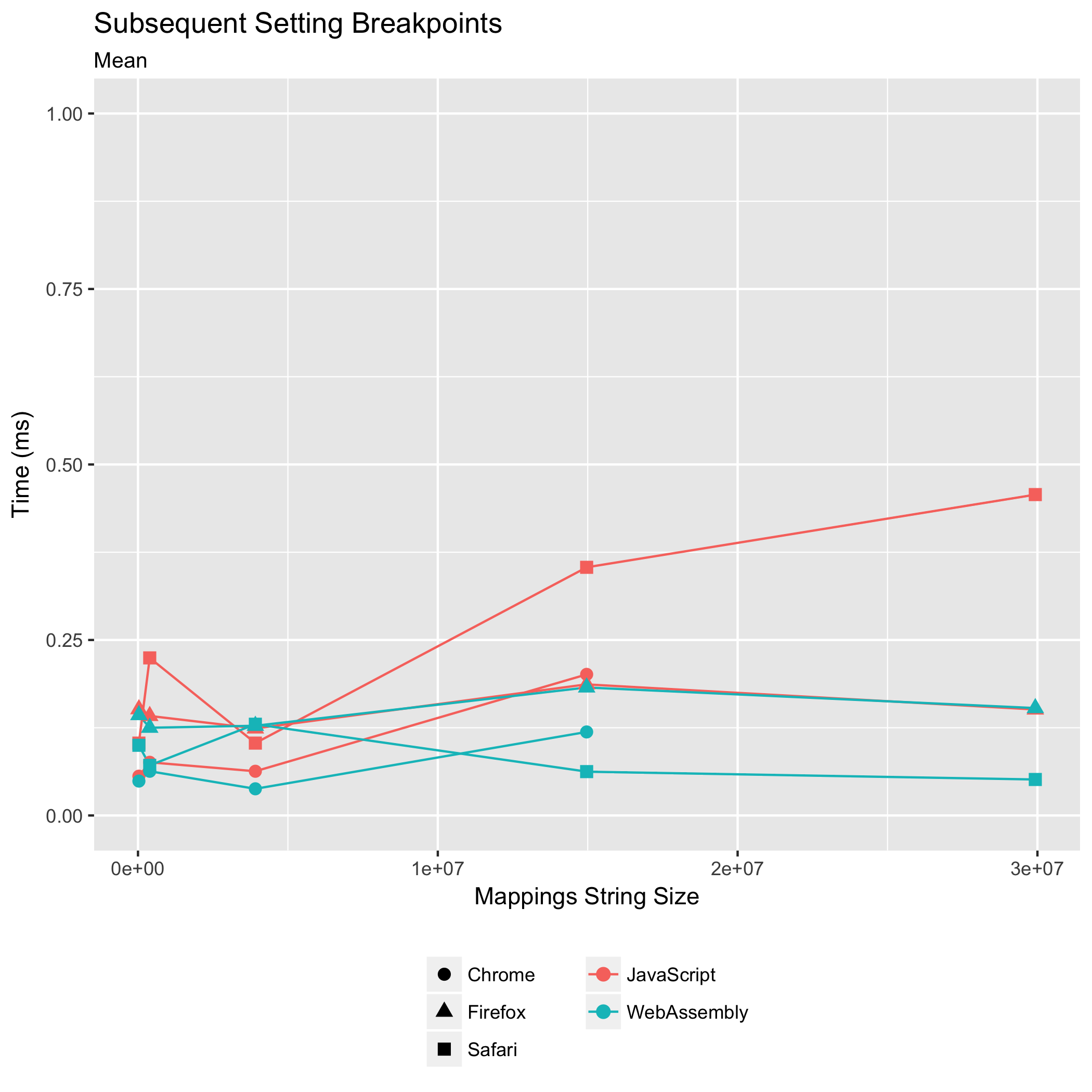
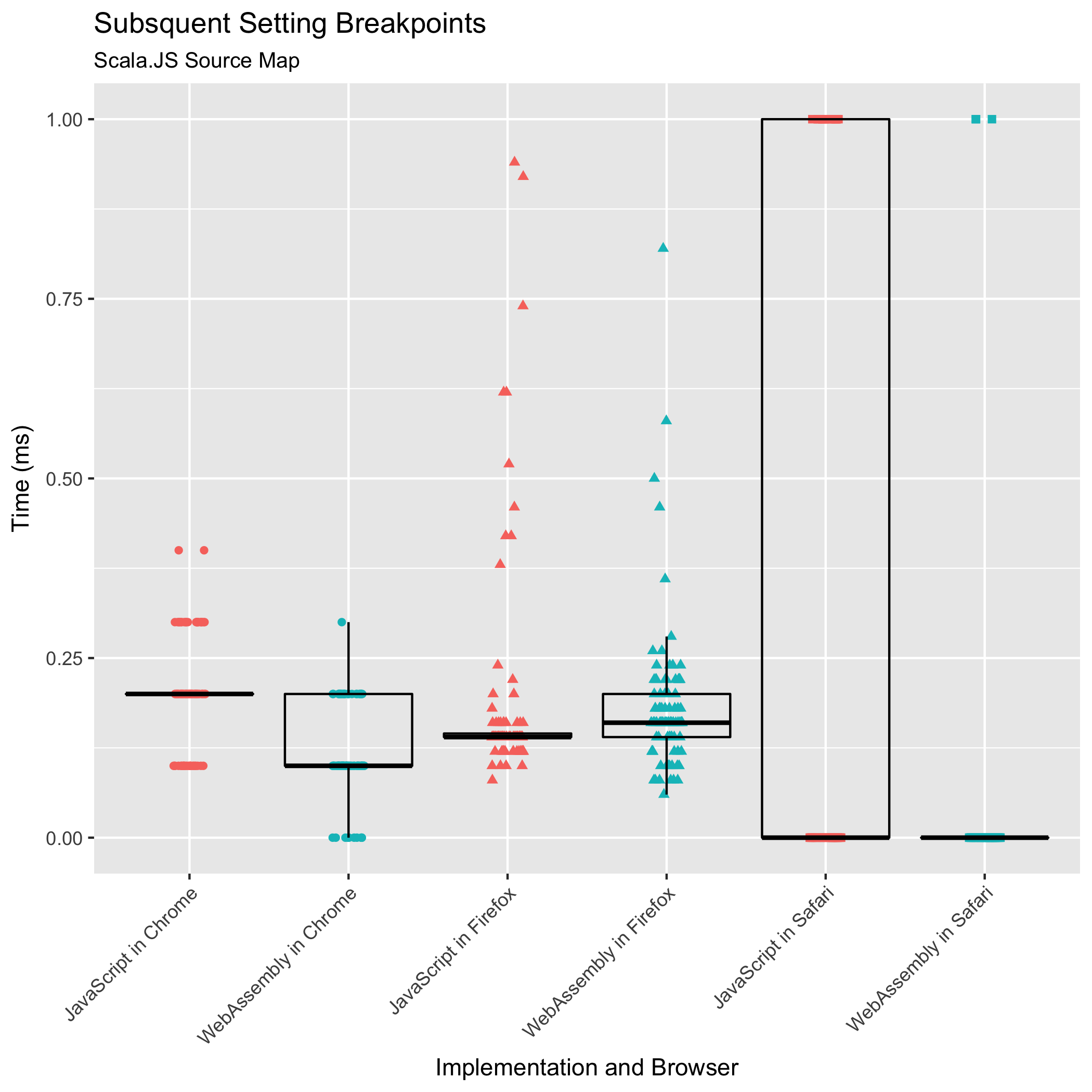
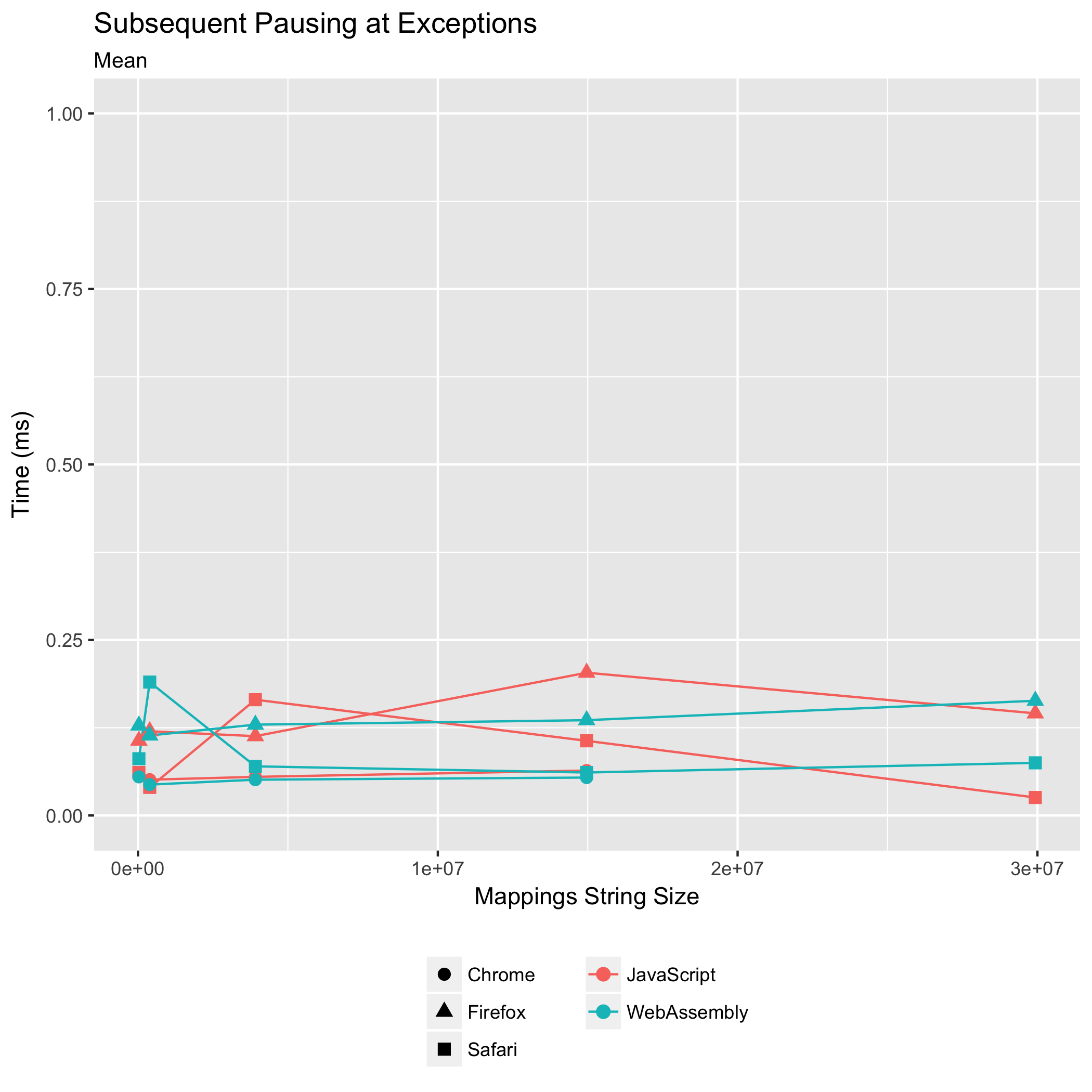
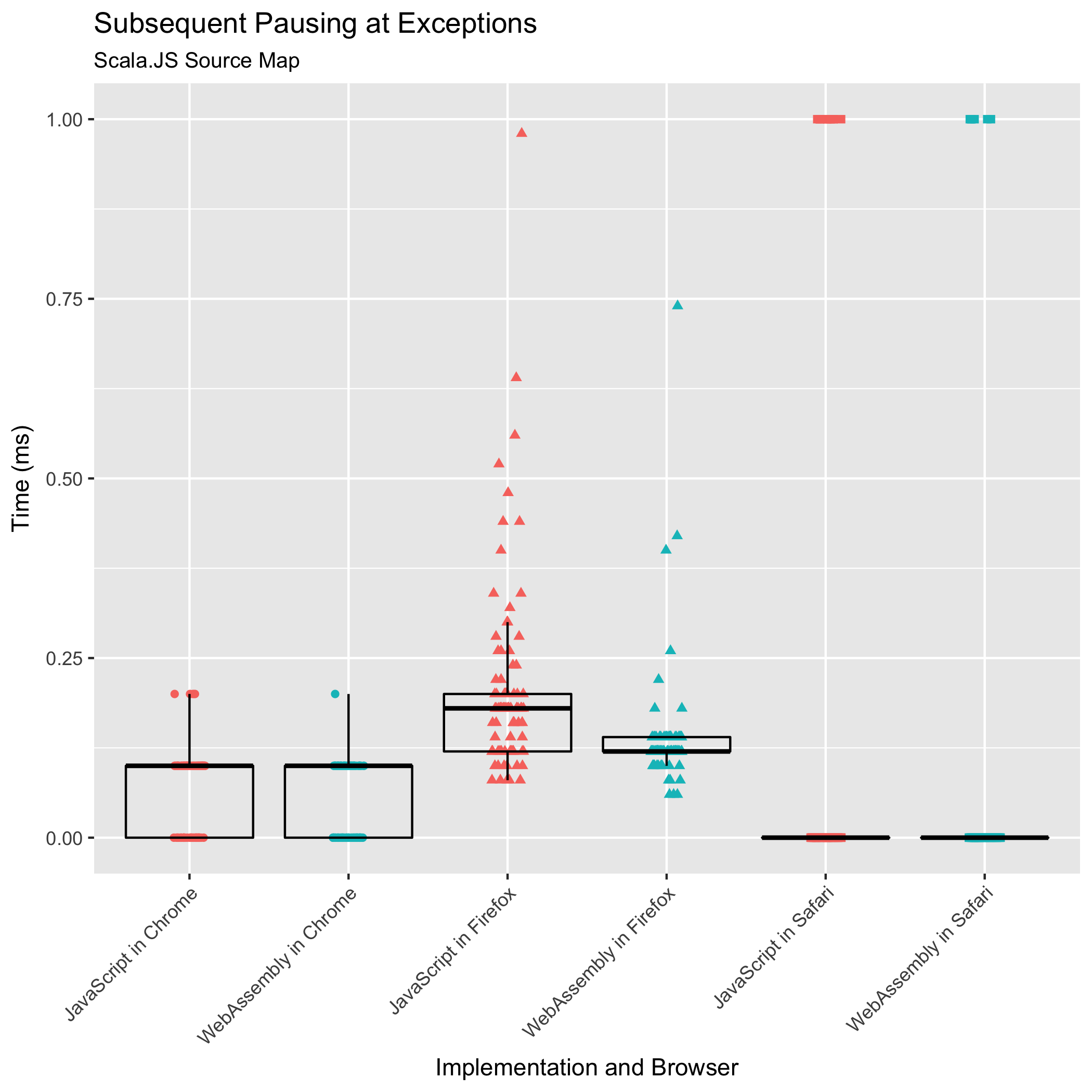
These benchmark results should be seasoned with more salt than the other benchmarks’ results. Looking at both of the Scala.JS source map input plots, we see clear strata formations. This layering happens because the benchmarked operations run in such little time that the resolution of our timer becomes visible. We can see that Chrome exposes timers with resolution to tenths of a millisecond, Firefox exposes them with resolution to .02 milliseconds, and Safari exposes millisecond resolution.
All we can conclude, based on this data, is that subsequent queries largely remain sub-millisecond operations in both JavaScript and WebAssembly implementations. Subsequent queries have never been a performance bottleneck, and they do not become a bottleneck in the new WebAssembly implementation.
Iterating Over All Mappings
The final two benchmarks measure the time it takes to parse a source map and immediately iterate over its mappings, and to iterate over an already-parsed source map’s mappings. These are common operations performed by build tools that are composing or consuming source maps. They are also sometimes performed by stepping debuggers to highlight to the user which lines within an original source the user can set breakpoints on — it doesn’t make sense to set a breakpoint on a line that doesn’t translate into any location in the generated JavaScript.
This benchmark was the one we worried about: it involves the most JavaScript↔WebAssembly boundary crossing, an FFI call for every mapping in the source map. For all other benchmarks tested, our design minimized the number of such FFI calls.
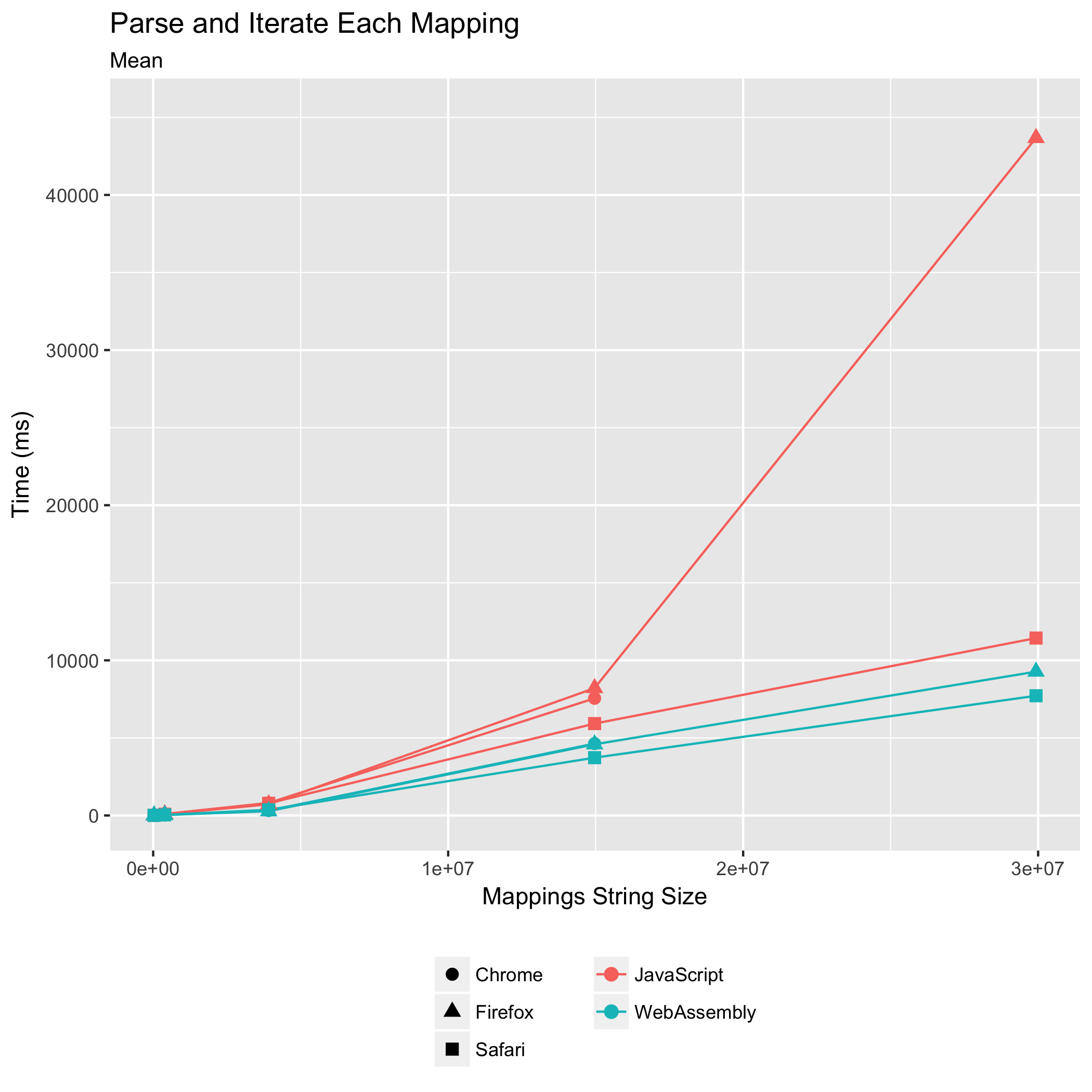
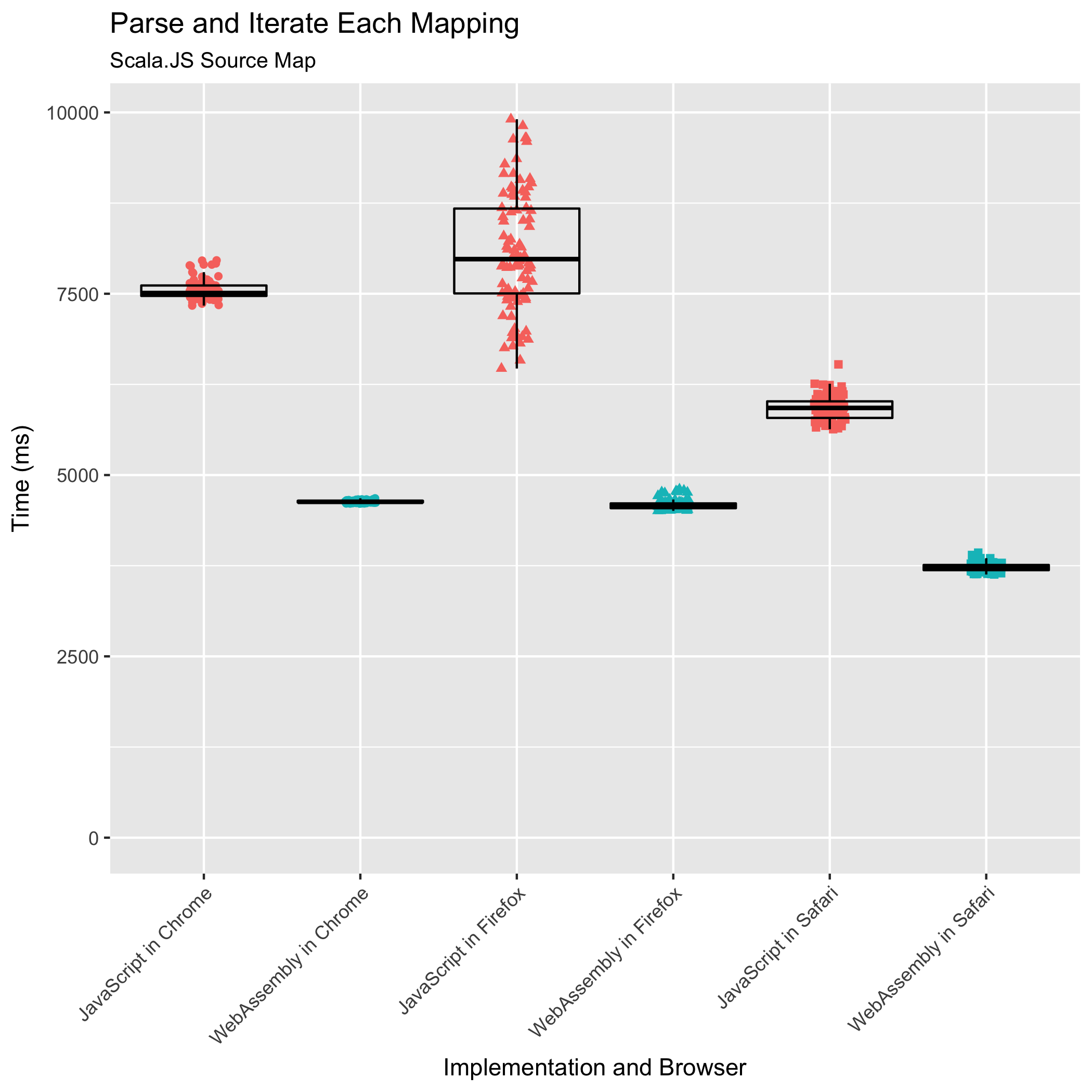
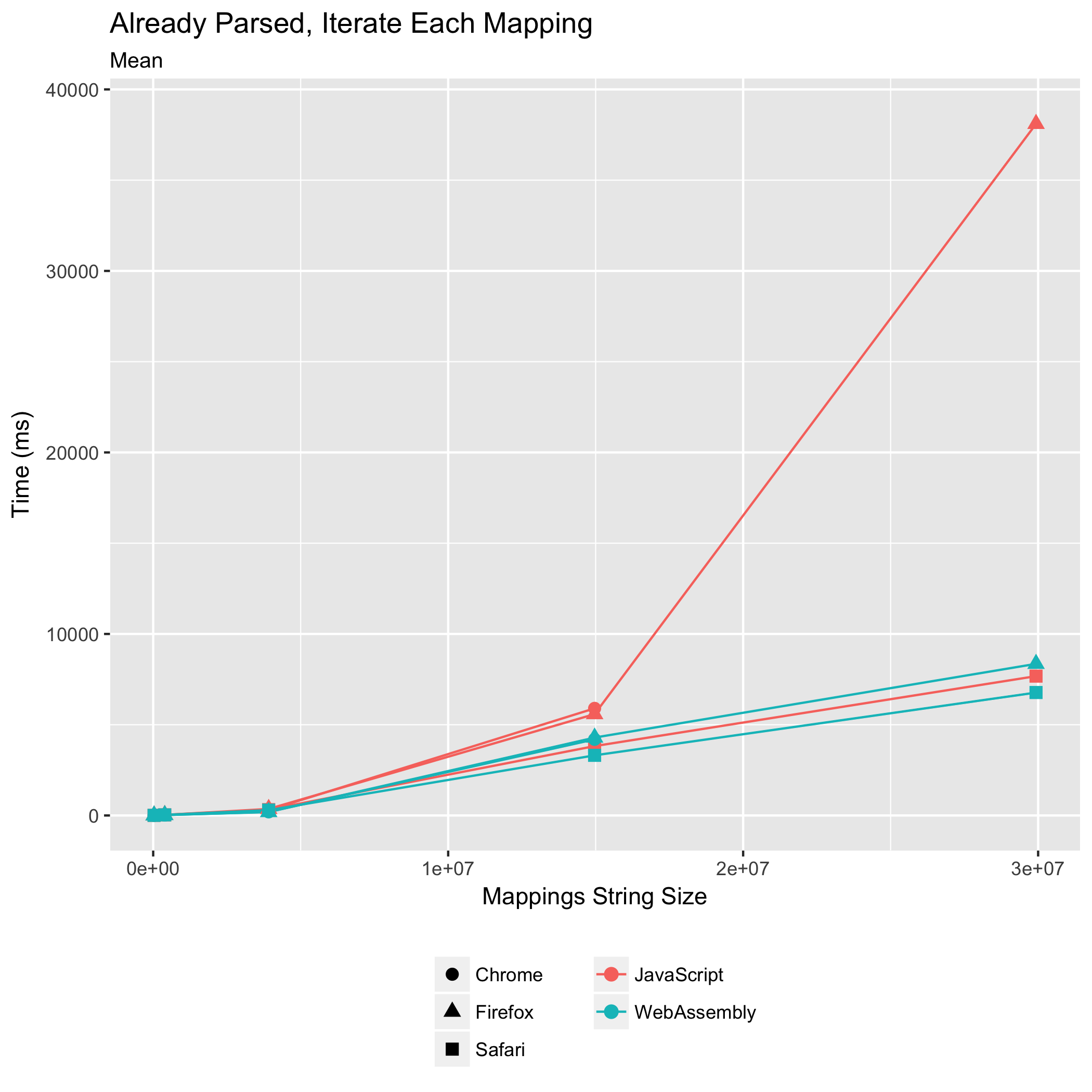
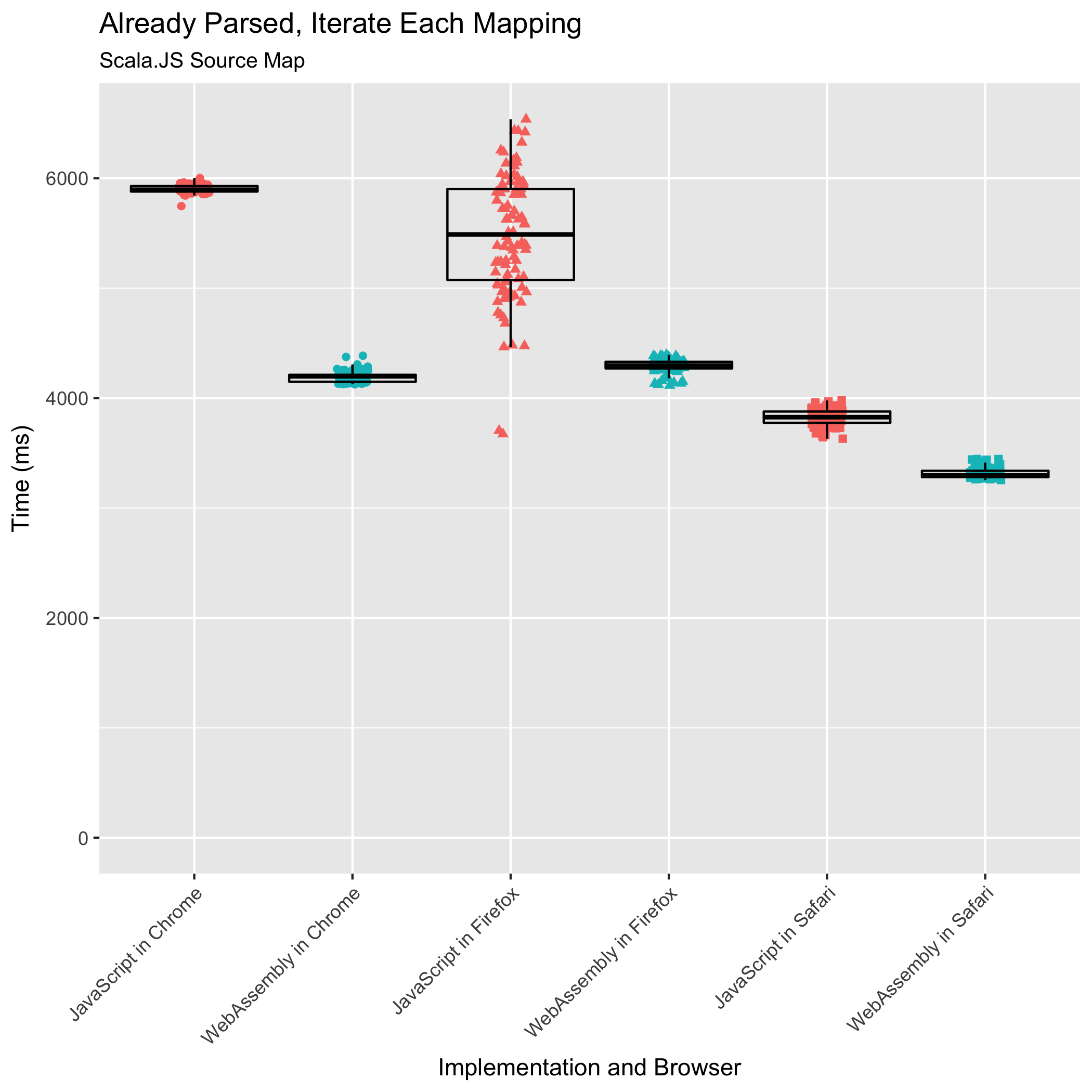
It turns out our worry was unfounded. The WebAssembly implementation doesn’t just meet the JavaScript implementation’s performance, even when the source map is already parsed, it surpasses the JavaScript implementation’s performance. For the parse-and-iterate and iterate-already-parsed benchmarks, the WebAssembly takes 0.61x and 0.71x the time of the JavaScript in Chrome. In Firefox, the WebAssembly takes 0.56x and 0.77x the time of the JavaScript. In Safari, the WebAssembly implementation takes 0.63x and 0.87x the amount of time that the JavaScript implementation takes. Once again, Safari runs the WebAssembly implementation the quickest, and Firefox and Chrome are essentially tied for second place. Safari deserves special acknowledgment for its JavaScript performance on the iterate-already-parsed benchmark: beyond just outperforming the other browsers’ JavaScript times, Safari runs the JavaScript faster than the other browsers run the WebAssembly!
True to the trend from earlier benchmarks, we also see reductions in the relative standard deviations in the WebAssembly compared to the JavaScript implementation. When both parsing and iterating, Chrome’s relative standard deviation fell from ±1.80% to ±0.33%, Firefox’s from ±11.63% to ±1.41%, and Safari’s from ±2.73% to ±1.51%. When iterating over an already-parsed source map’s mappings, Firefox’s relative standard deviation dropped from ±12.56% to ±1.40%, and Safari’s from ±1.97% to ±1.40%. Chrome’s relative standard deviation grew from ±0.61% to ±1.18%, making it the only browser to buck the trend, but only on this one benchmark.
Code Size
One of advantages of the wasm32-unknown-unknown target over the wasm32-unknown-emscripten target, is that it generates leaner WebAssembly code. The wasm32-unknown-emscripten target includes polyfills for most of libc and a file system built on top of IndexedDB, among other things, but wasm32-unknown-unknown does not. With the source-map library, we’ve only used wasm32-unknown-unknown.
We consider the code size of the JavaScript and WebAssembly that is delivered to the client. That is, we’re looking at the code size after bundling JavaScript modules together into a single .js file. We look at the effects of using wasm-gc, wasm-snip, and wasm-opt to shrink .wasm file size, and using gzip compression, which is ubiquitously supported on the Web.
In these measurements, the JavaScript size reported is always the size of minified JavaScript, created with the Google Closure Compiler at the “simple” optimization level. We used the Closure Compiler because UglifyJS does not support some newer ECMAScript forms that we introduced (for example let and arrow functions). We used the “simple” optimization level because the “advanced” optimization level is destructive for JavaScript that wasn’t authored with Closure Compiler in mind.
The bars labeled “JavaScript” are for variations of the original, pure-JavaScript source-map library implementation. The bars labeled “WebAssembly” are for variations of the new source-map library implementation that uses WebAssembly for parsing the "mappings" string and querying the parsed mappings. Note that the “WebAssembly” implementation still uses JavaScript for all other functionality! The source-map library has additional features, such as generating source maps, that are still implemented in JavaScript. For the “WebAssembly” implementation, we report the sizes of both the WebAssembly and JavaScript.
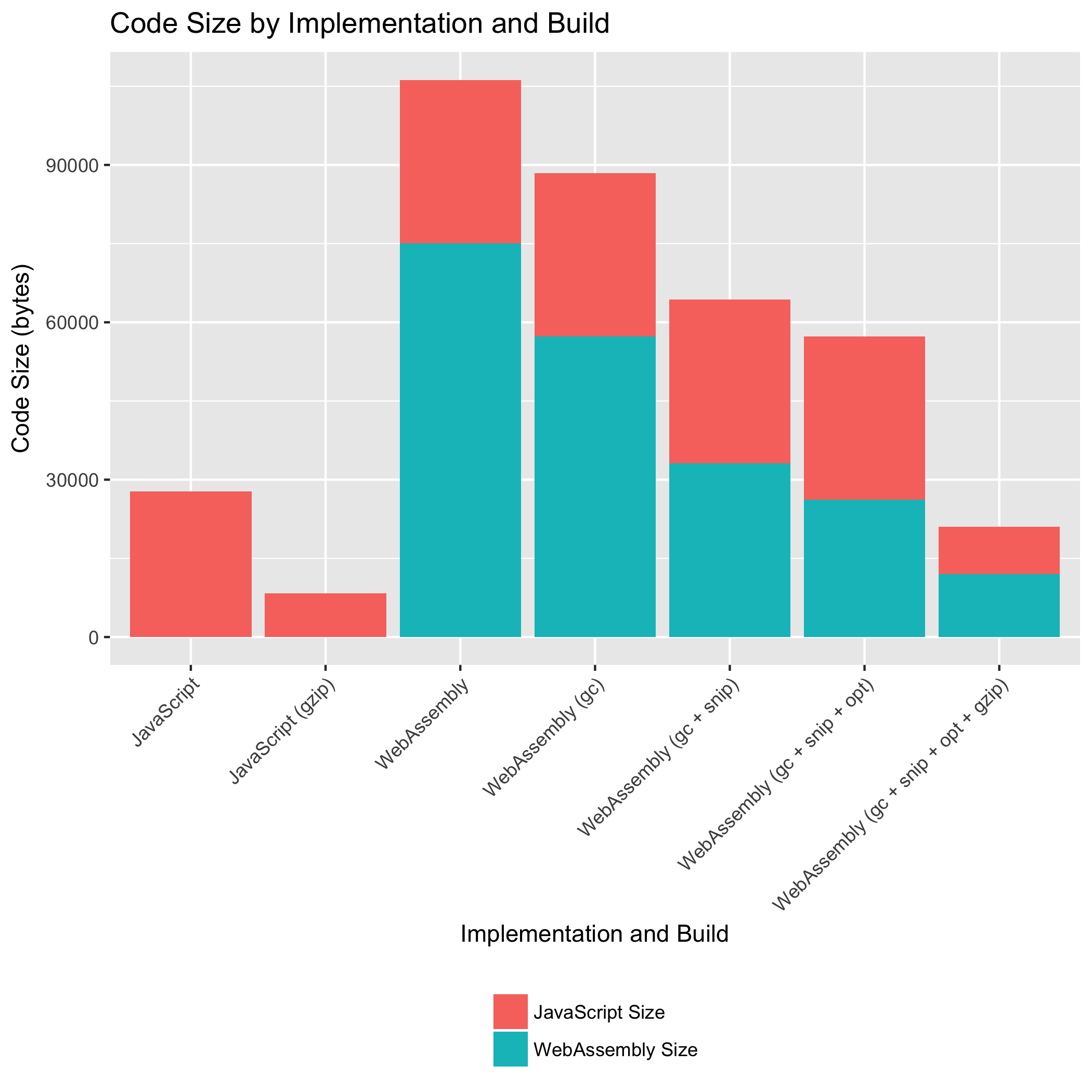
At its smallest, the new WebAssembly implementation has a larger total code size than the old JavaScript implementation: 20,996 bytes versus 8,365 bytes respectively. However, by using tools for shrinking .wasm size, we brought the size of the WebAssembly down to 0.16x its original size. Both implementations have similar amounts of JavaScript.
If we replaced JavaScript parsing and querying code with WebAssembly, why doesn’t the WebAssembly implementation contain less JavaScript? There are two factors contributing to the lack of JavaScript code size reductions. First, there is some small amount of new JavaScript introduced to load the .wasm file and interface with the WebAssembly. Second, and more importantly, some of the JavaScript routines that we “replaced” were previously shared with other parts of the source-map library. Now, although those routines are no longer shared, they are still in use by those other portions of the library.
Let us turn our focus towards what is contributing to the size of the pre-gziped .wasm file. Running wasm-objdump -h gives us the sizes of each section:
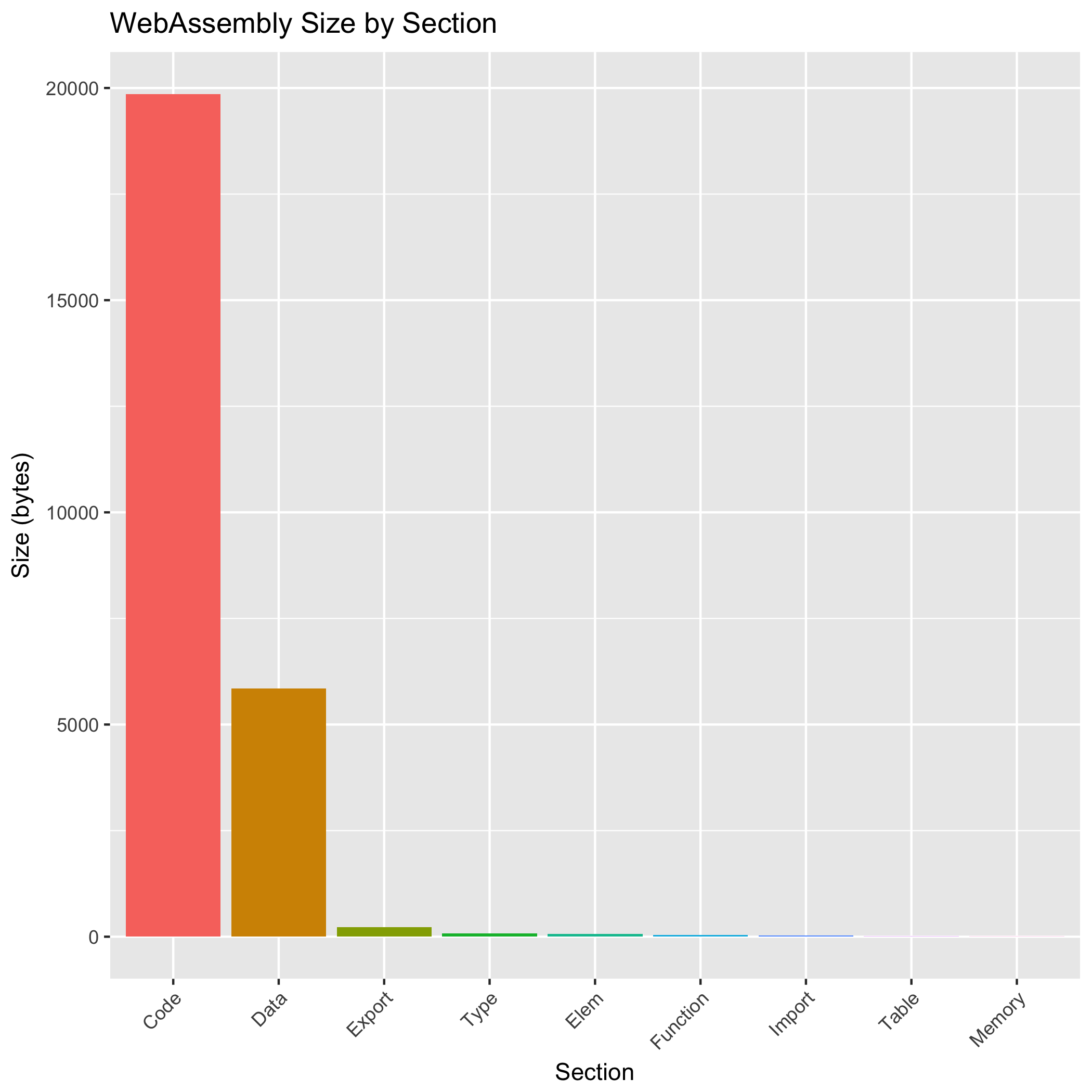
The Code and Data sections effectively account for the whole .wasm file’s size. The Code section contains the encoded WebAssembly instructions that make up function bodies. The Data section consists of static data to be loaded into the WebAssembly module’s linear memory space.
Using wasm-objdump to manually inspect the Data section’s contents shows that it mostly consists of string fragments used for constructing diagnostic messages if the Rust code were to panic. However, when targeting WebAssembly, Rust panics translate into WebAssembly traps, and traps do not carry extra diagnostic information. We consider it a bug in rustc that these string fragments are even emitted. Unfortunately, wasm-gc cannot currently remove unused Data segments either, so we are stuck with this bloat for the meantime. WebAssembly and its tooling is still relatively immature, and we expect the toolchain to improve in this respect with time.
Next, we post-process wasm-objdump‘s disassembly output to compute the size of each function body inside the Code section, and group sizes by Rust crate:
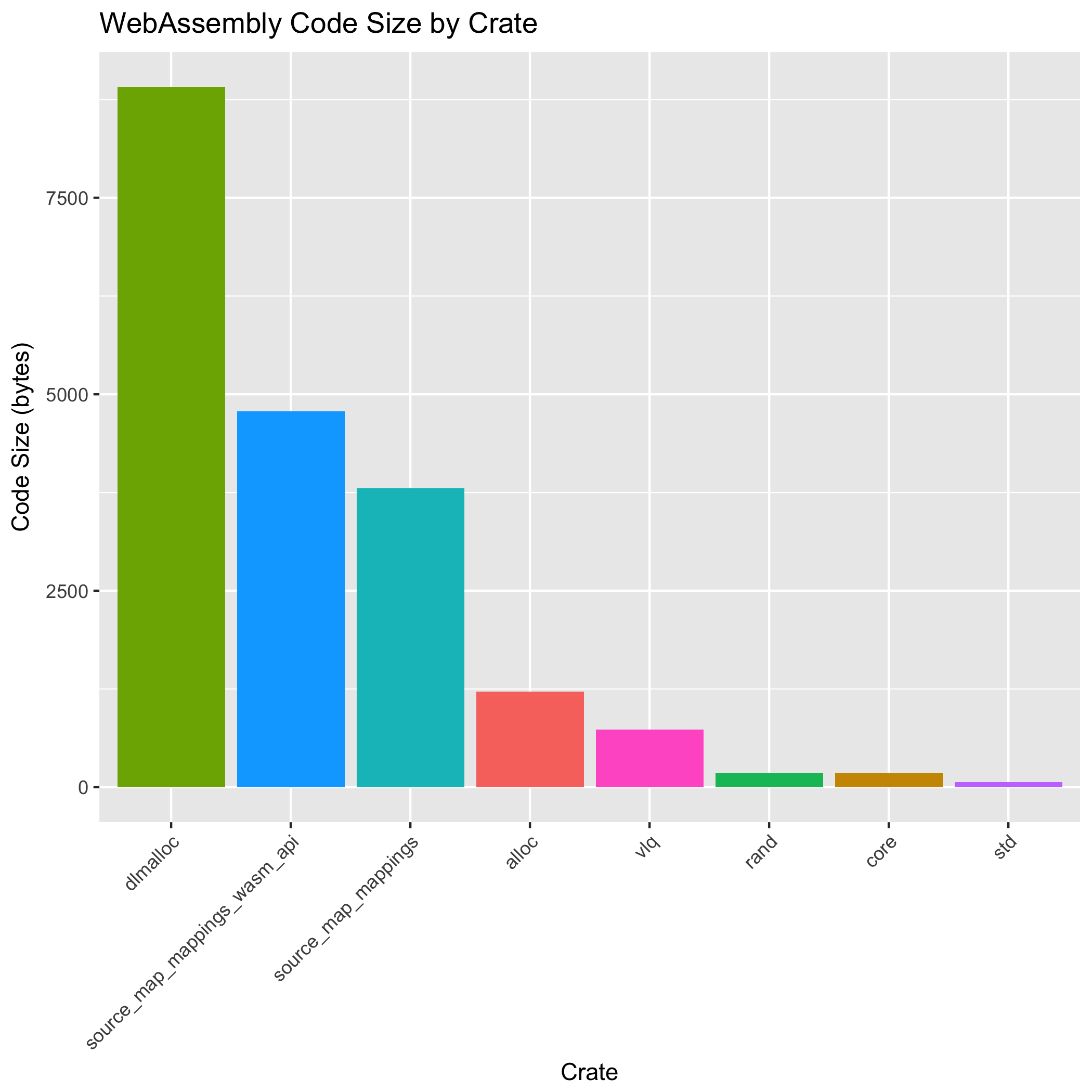
The heaviest crate is dlmalloc which is used by the alloc crate, which implements Rust’s low-level allocation APIs. Together, dlmalloc and alloc clock in at 10,126 bytes, or 50.98% the total function size. In a sense, this is a relief: the code size of the allocator is a constant that will not grow as we port more JavaScript code to Rust.
The sum of code sizes from crates that we authored (vlq, source_map_mappings, and source_map_mappings_wasm_api) is 9,320 bytes, or 46.92% the total function size. That leaves only 417 bytes (2.10%) of space consumed by the other crates. This speaks to the efficacy of wasm-gc, wasm-snip, and wasm-opt: although crates like std are much larger than our crates, we only use a tiny fraction of its APIs and we only pay for what we use.
Conclusions and Future Work
Rewriting the most performance-sensitive portions of source map parsing and querying in Rust and WebAssembly has been a success. On our benchmarks, the WebAssembly implementation takes a fraction the time that the original JavaScript implementation takes — as little as 0.17x the time. We observe that, for all browsers, the WebAssembly implementation is faster than the JavaScript implementation. Furthermore, the WebAssembly implementation offers more consistent and reliable performance: relative standard deviation between iterations dropped significantly compared to the JavaScript implementation.
The JavaScript implementation has accumulated convoluted code in the name of performance, and we replaced it with idiomatic Rust. Rust does not force us to choose between clearly expressing intent and runtime performance.
That said, there is still more work to do.
The most pressing next step is investigating why the Rust standard library’s sorting is not as fast as our custom Quicksort when targeting WebAssembly. This is the sole unidiomatic bit of Rust code in the rewrite. This behavior is surprising since our Quicksort implementation is naive, and the standard library’s quick sort is pattern defeating and opportunistically uses insertion sort for small and mostly-sorted ranges. In fact, the standard library’s sorting routine is faster than ours when targeting native code. We speculate that inlining heuristics are changing across targets, and that our comparator functions aren’t being inlined into the standard library’s sorting routine when targeting WebAssembly. It requires further investigation.
We found size profiling WebAssembly was more difficult than necessary. To get useful information presented meaningfully, we were forced to write our own home-grown script to post-process wasm-objdump. The script constructs the call graph, and lets us query who the callers of some function were, helping us understand why the function was emitted in the .wasm file, even if we didn’t expect it to be. It is pretty hacky, and doesn’t expose information about inlined functions. A proper WebAssembly size profiler would have helped, and would be a benefit for anyone following in our tracks.
The relatively large code size footprint of the allocator suggests that writing or adapting an allocator that is focused on tiny code size could provide considerable utility for the WebAssembly ecosystem. At least for our use case, allocator performance is not a concern, and we only make a small handful of dynamic allocations. For an allocator, we would choose small code size over performance in a heartbeat.
The unused segments in our Data section highlight the need for wasm-gc, or another tool, to detect and remove static data that is never referenced.
There are still some JavaScript API improvements that we can make for the library’s downstream users. The introduction of WebAssembly in our current implementation requires the introduction of manually freeing the parsed mappings when the user is finished with it. This does not come naturally to most JavaScript programmers, who are used to relying on a garbage collector, and do not typically think about the lifetime of any particular object. We could introduce a SourceMapConsumer.with function that took a raw, un-parsed source map, and an async function. The with function would construct a SourceMapConsumer instance, invoke the async function with it, and then call destroy on the SourceMapConsumer instance once the async function call completes. This is like async RAII for JavaScript.
SourceMapConsumer.with = async function (rawSourceMap, f) {
const consumer = await new SourceMapConsumer(rawSourceMap);
try {
await f(consumer);
} finally {
consumer.destroy();
}
};
Another alternative way to make the API easier to work with for JavaScript programmers would be to give every SourceMapConsumer its own instance of the WebAssembly module. Then, because the SourceMapConsumer instance would have the sole GC edge to its WebAssembly module instance, we could let the garbage collector manage all of the SourceMapConsumer instance, the WebAssembly module instance, and the module instance’s heap. With this strategy, we would have a single static mut MAPPINGS: Mappings in the Rust WebAssembly glue code, and the Mappings instance would be implicit in all exported query function calls. No more Box::new(mappings) in the parse_mappings function, and no more passing around *mut Mappings pointers. With some care, we might be able to remove all allocation from the Rust library, which would shrink the emitted WebAssembly to half its current size. Of course, this all depends on creating multiple instances of the same WebAssembly module being a relatively cheap operation, which requires further investigation.
The wasm-bindgen project aims to remove the need to write FFI glue code by hand, and automates interfacing between WebAssembly and JavaScript. Using it, we should be able to remove all the hand-written unsafe pointer manipulation code involved in exporting Rust APIs to JavaScript.
In this project, we ported source map parsing and querying to Rust and WebAssembly, but this is only half of the source-map library’s functionality. The other half is generating source maps, and it is also performance sensitive. We would like to rewrite the core of building and encoding source maps in Rust and WebAssembly sometime in the future as well. We expect to see similar speed ups to what we observed for parsing source maps.
The pull request adding the WebAssembly implementation to the mozilla/source-map library is in the process of merging here. That pull request contains the benchmarking code, so that results can be reproduced, and we can continue to improve them.
Finally, I’d like to thank Tom Tromey for hacking on this project with me. I’d also like to thank Aaron Turon, Alex Crichton, Benjamin Bouvier, Jeena Lee, Jim Blandy, Lin Clark, Luke Wagner, Mike Cooper, and Till Schneidereit for reading early drafts and providing valuable feedback. This document, our benchmarks, and the source-map library are all better thanks to them.
0 Or “transpiler” if you must insist. ⬑
1 SpiderMonkey now uses a self-hosted JavaScript implementation of Array.prototype.sort when there is a custom comparator function, and a C++ implementation when there is not. ⬑
2 The overhead of calls between WebAssembly and JavaScript should mostly disappear in Firefox once bug 1319203 lands. After that, calls between JavaScript and WebAssembly will have similar overheads to out-of-line calls between JavaScript functions. But that patch hasn’t landed yet, and other browsers haven’t landed equivalent improvements yet either. ⬑
3 For Firefox and Chrome, we tested with the latest nightly builds. We did not do the same with Safari because the latest Safari Technology Preview requires a newer macOS version than El Capitan, which this laptop was running. ⬑
About Nick Fitzgerald
I like computing, bicycles, hiphop, books, and pen plotters. My pronouns are he/him.
7 comments