
People call WebAssembly a game changer because it makes it possible to run code on the web faster. Some of these speedups are already present, and some are yet to come.
One of these speedups is streaming compilation, where the browser compiles the code while the code is still being downloaded. Up until now, this was just a potential future speedup. But with the release of Firefox 58 next week, it becomes a reality.
Firefox 58 also includes a new 2-tiered compiler. The new baseline compiler compiles code 10–15 times faster than the optimizing compiler.
Combined, these two changes mean we compile code faster than it comes in from the network.

On a desktop, we compile 30-60 megabytes of WebAssembly code per second. That’s faster than the network delivers the packets.
If you use Firefox Nightly or Beta, you can give it a try on your own device. Even on a pretty average mobile device, we can compile at 8 megabytes per second —which is faster than the average download speed for pretty much any mobile network.
This means your code executes almost as soon as it finishes downloading.
Why is this important?
Web performance advocates get prickly when sites ship a lot of JavaScript. That’s because downloading lots of JavaScript makes pages load slower.
This is largely because of the parse and compile times. As Steve Souders points out, the old bottleneck for web performance used to be the network. But the new bottleneck for web performance is the CPU, and particularly the main thread.
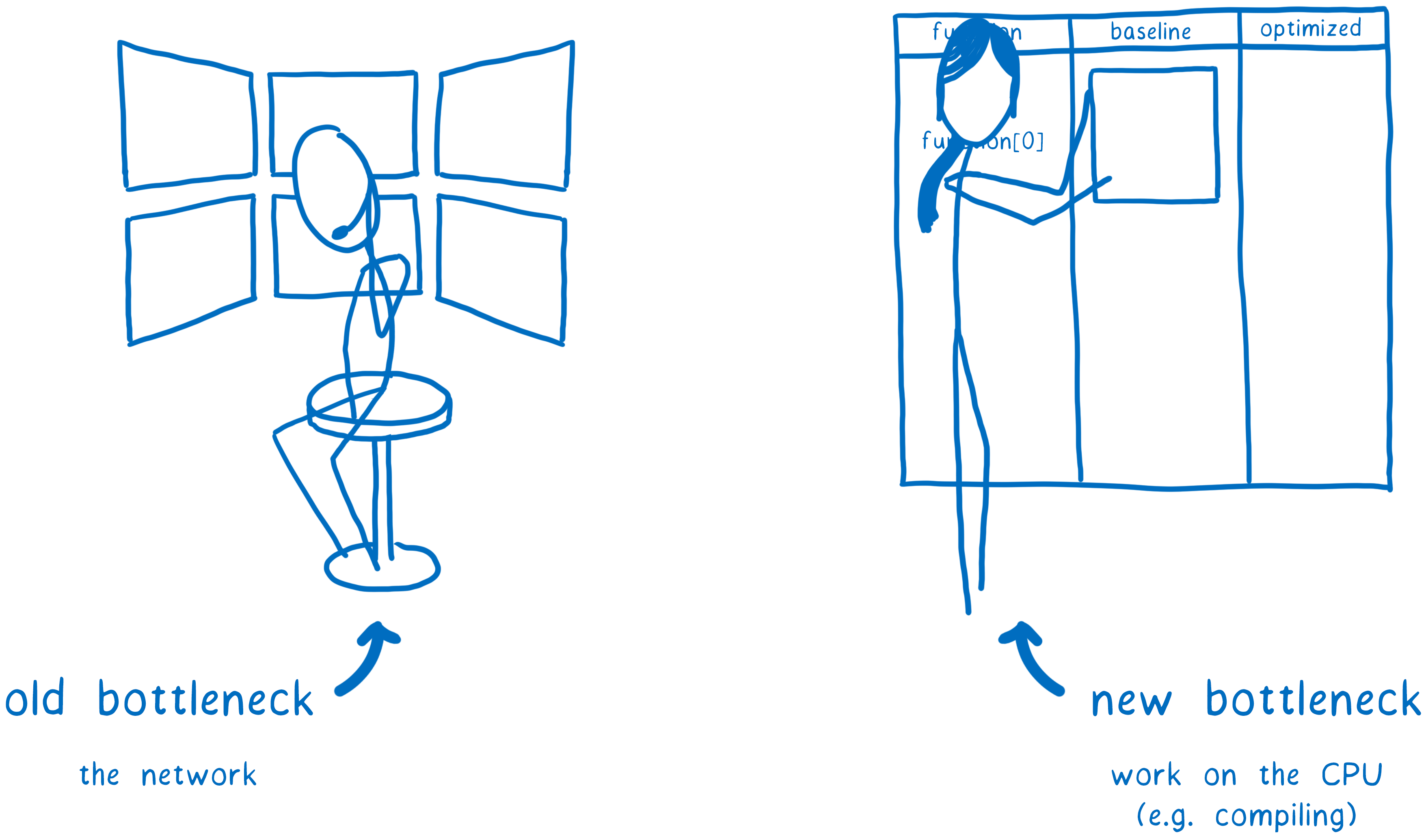
So we want to move as much work off the main thread as possible. We also want to start it as early as possible so we’re making use of all of the CPU’s time. Even better, we can do less CPU work altogether.
With JavaScript, you can do some of this. You can parse files off of the main thread, as they stream in. But you’re still parsing them, which is a lot of work, and you have to wait until they are parsed before you can start compiling. And for compiling, you’re back on the main thread. This is because JS is usually compiled lazily, at runtime.
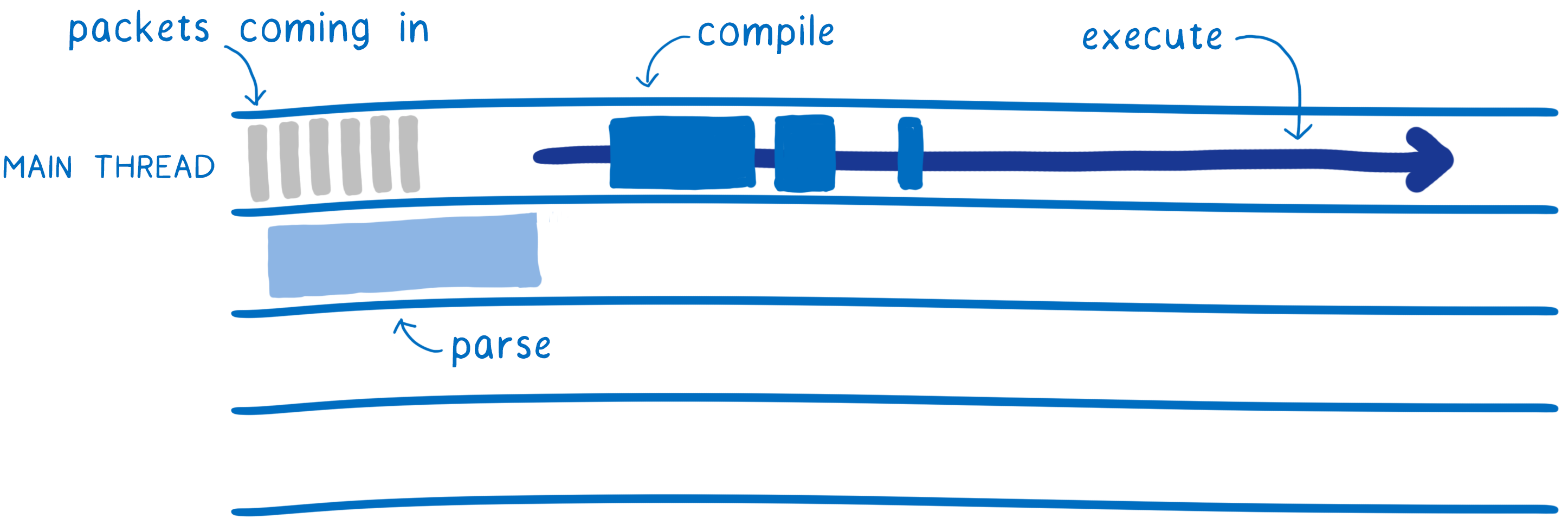
With WebAssembly, there’s less work to start with. Decoding WebAssembly is much simpler and faster than parsing JavaScript. And this decoding and the compilation can be split across multiple threads.
This means multiple threads will be doing the baseline compilation, which makes it faster. Once it’s done, the baseline compiled code can start executing on the main thread. It won’t have to pause for compilation, like the JS does.
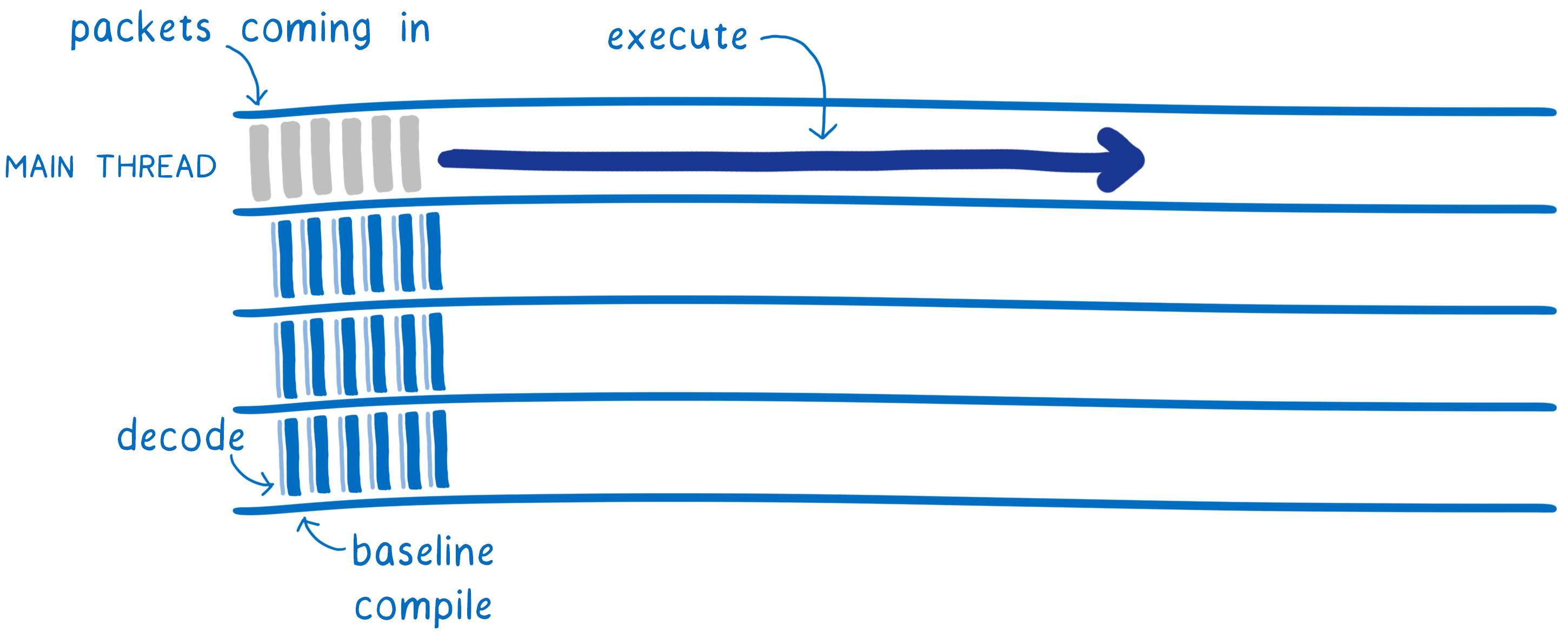
While the baseline compiled code is running on the main thread, other threads work on making a more optimized version. When the more optimized version is done, it can be swapped in so the code runs even faster.
This changes the cost of loading WebAssembly to be more like decoding an image than loading JavaScript. And think about it… web performance advocates do get prickly about JS payloads of 150 kB, but an image payload of the same size doesn’t raise eyebrows.

That’s because load time is so much faster with images, as Addy Osmani explains in The Cost of JavaScript, and decoding an image doesn’t block the main thread, as Alex Russell discusses in Can You Afford It?: Real-world Web Performance Budgets.
This doesn’t mean that we expect WebAssembly files to be as large as image files. While early WebAssembly tools created large files because they included lots of runtime, there’s currently a lot of work to make these files smaller. For example, Emscripten has a “shrinking initiative”. In Rust, you can already get pretty small file sizes using the wasm32-unknown-unknown target, and there are tools like wasm-gc and wasm-snip which can optimize this even more.
What it does mean is that these WebAssembly files will load much faster than the equivalent JavaScript.
This is big. As Yehuda Katz points out, this is a game changer.

So let’s look at how the new compiler works.
Streaming compilation: start compiling earlier
If you start compiling the code earlier, you’ll finish compiling it earlier. That’s what streaming compilation does… makes it possible to start compiling the .wasm file as soon as possible.
When you download a file, it doesn’t come down in one piece. Instead, it comes down in a series of packets.
Before, as each packet in the .wasm file was being downloaded, the browser network layer would put it into an ArrayBuffer.
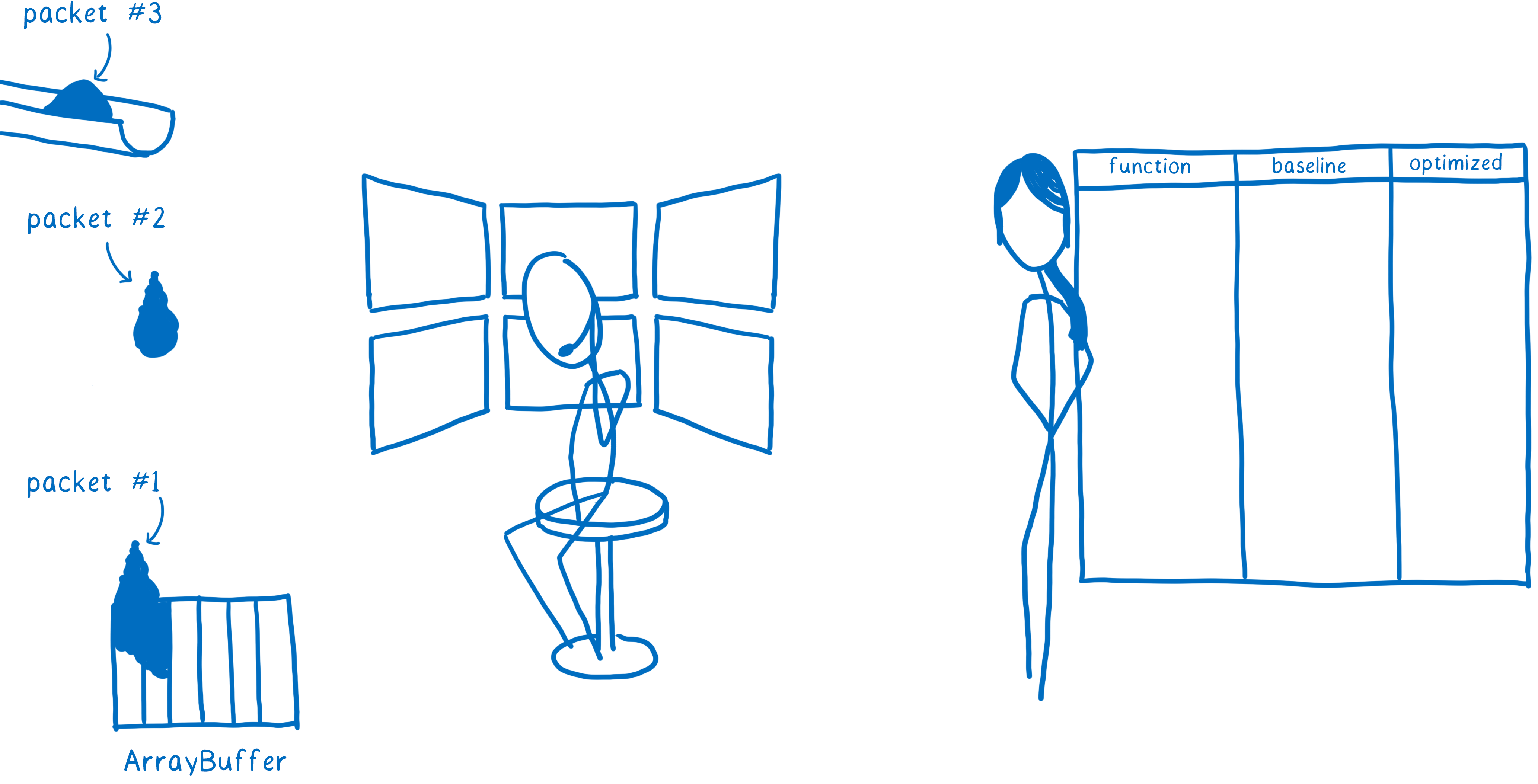
Then, once that was done, it would move that ArrayBuffer over to the Web VM (aka the JS engine). That’s when the WebAssembly compiler would start compiling.

But there’s no good reason to keep the compiler waiting. It’s technically possible to compile WebAssembly line by line. This means you should be able to start as soon as the first chunk comes in.
So that’s what our new compiler does. It takes advantage of WebAssembly’s streaming API.
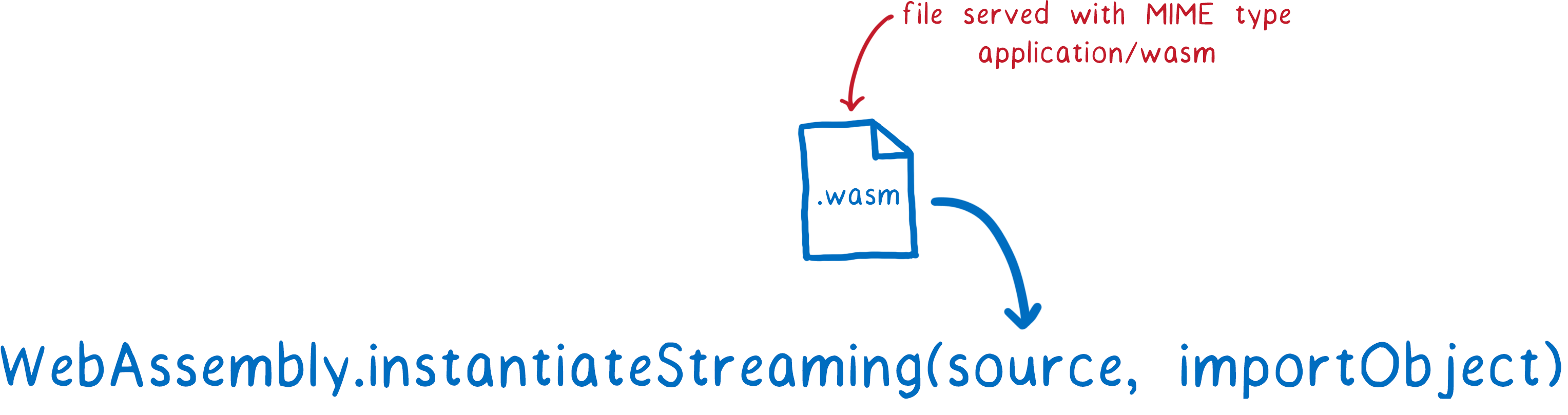
If you give WebAssembly.instantiateStreaming a response object, the chunks will go right into the WebAssembly engine as soon as they arrive. Then the compiler can start working on the first chunk while the next one is still being downloaded.
Besides being able to download and compile the code in parallel, there’s another advantage to this.
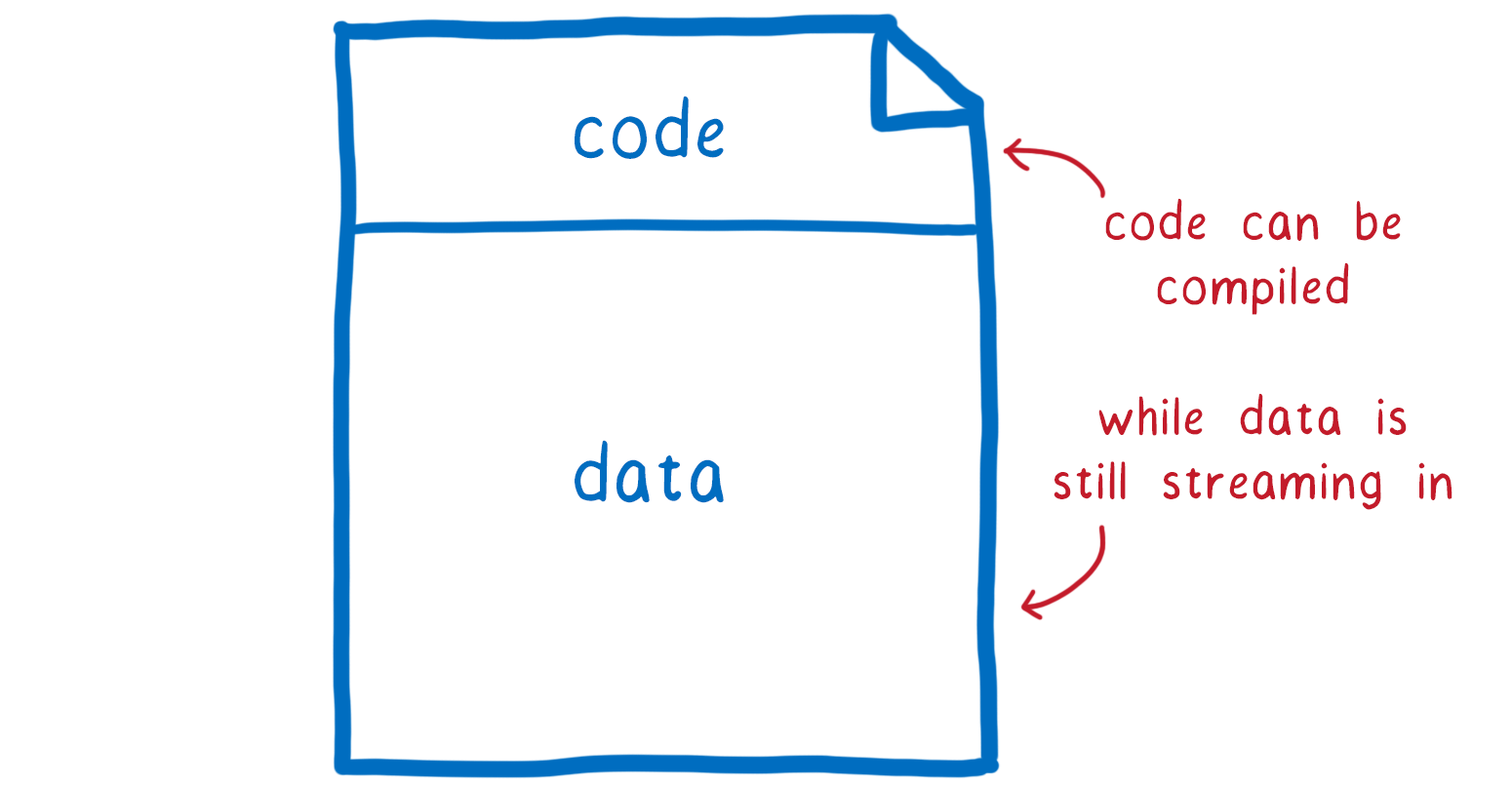
The code section of the .wasm module comes before any data (which will go in the module’s memory object). So by streaming, the compiler can compile the code while the module’s data is still being downloaded. If your module needs a lot of data, the data can be megabytes, so this can be significant.
With streaming, we start compiling earlier. But we can also make compiling faster.
Tier 1 baseline compiler: compile code faster
If you want code to run fast, you need to optimize it. But performing these optimizations while you’re compiling takes time, which makes compiling the code slower. So there’s a tradeoff.
We can have the best of both of these worlds. If we use two compilers, we can have one that compiles quickly without too many optimizations, and another that compiles the code more slowly but creates more optimized code.
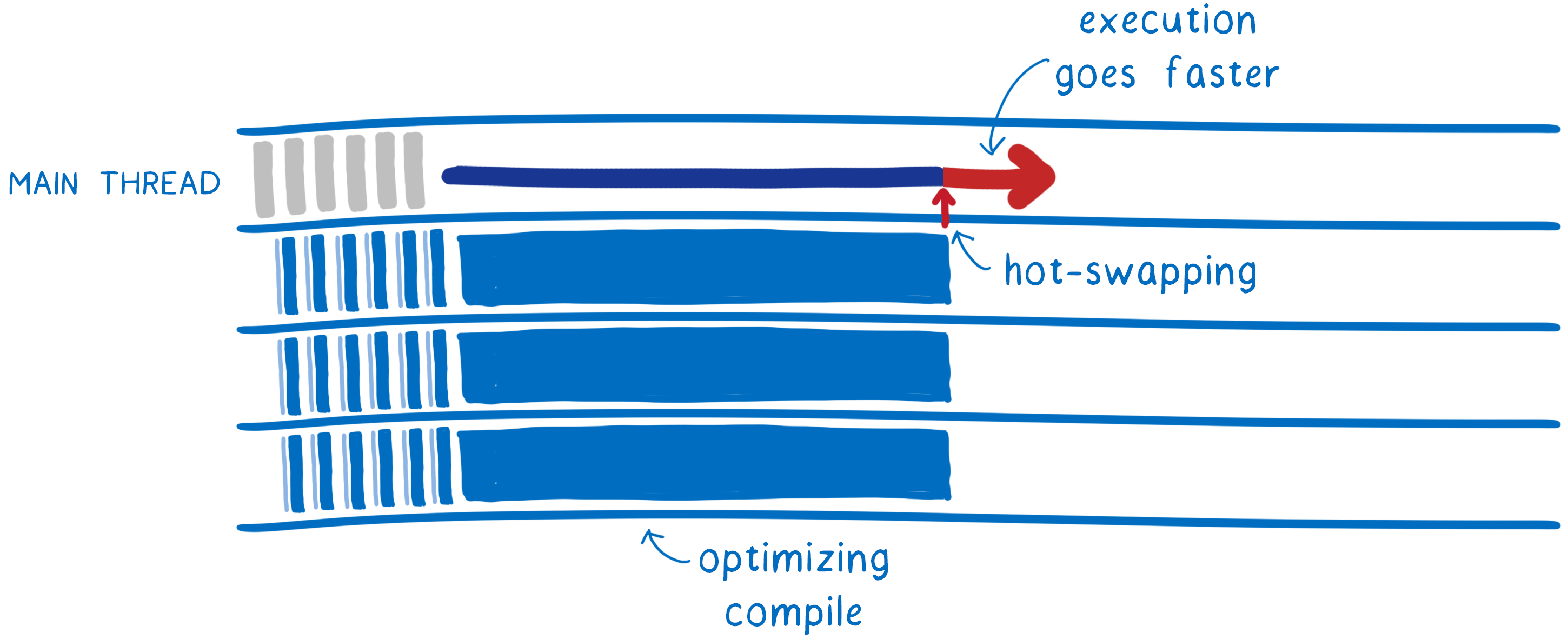
This is called a tiered compiler. When code first comes in, it’s compiled by the Tier 1 (or baseline) compiler. Then, after the baseline compiled code starts running, a Tier 2 compiler goes through the code again and compiles a more optimized version in the background.
Once it’s done, it hot-swaps the optimized code in for the previous baseline version. This makes the code execute faster.
JavaScript engines have been using tiered compilers for a long time. However, JS engines will only use the Tier 2 (or optimizing) compiler when a bit of code gets “warm”… when that part of the code gets called a lot.
In contrast, the WebAssembly Tier 2 compiler will eagerly do a full recompilation, optimizing all of the code in the module. In the future, we may add more options for developers to control how eagerly or lazily optimization is done.
This baseline compiler saves a lot of time at startup. It compiles code 10–15 times faster than the optimizing compiler. And the code it creates is, in our tests, only 2 times slower.
This means your code will be running pretty fast even in those first few moments, when it’s still running the baseline compiled code.
Parallelize: make it all even faster
In the article on Firefox Quantum, I explained coarse-grained and fine-grained parallelization. We use both for compiling WebAssembly.
I mentioned above that the optimizing compiler will do its compilation in the background. This means that it leaves the main thread available to execute the code. The baseline compiled version of the code can run while the optimizing compiler does its recompilation.
But on most computers that still leaves multiple cores unused. To make the best use of all of the cores, both of the compilers use fine-grained parallelization to split up the work.
The unit of parallelization is the function. Each function can be compiled independently, on a different core. This is so fine-grained, in fact, that we actually need to batch these functions up into larger groups of functions. These batches get sent to different cores.
… then skip all that work entirely by caching it implicitly (future work)
Currently, decoding and compiling are redone every time you reload the page. But if you have the same .wasm file, it should compile to the same machine code.
This means that most of the time, this work could be skipped. And in the future, this is what we’ll do. We’ll decode and compile on first page load, and then cache the resulting machine code in the HTTP cache. Then when you request that URL, it will pull out the precompiled machine code.
This makes load time disappear for subsequent page loads.

The groundwork is already laid for this feature. We’re caching JavaScript byte code like this in the Firefox 58 release. We just need to extend this support to caching the machine code for .wasm files.
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
22 comments