
Machine Translation is an important tool for expanding the accessibility of web content. Usually, people use cloud providers to translate web pages. State-of-the-art Neural Machine Translation (NMT) models are large and often require specialized hardware like GPUs to run inference in real-time.
If people were able to run a compact Machine Translation (MT) model on their local machine CPU without sacrificing translation accuracy it would help to preserve privacy and reduce costs.
The Bergamot project is a collaboration between Mozilla, the University of Edinburgh, Charles University in Prague, the University of Sheffield, and the University of Tartu with funding from the European Union’s Horizon 2020 research and innovation programme. It brings MT to the local environment, providing small, high-quality, CPU optimized NMT models. The Firefox Translations web extension utilizes proceedings of project Bergamot and brings local translations to Firefox.
In this article, we will discuss the components used to train our efficient NMT models. The project is open-source, so you can give it a try and train your model too!
Architecture
NMT models are trained as language pairs, translating from language A to language B. The training pipeline was designed to train translation models for a language pair end-to-end, from environment configuration to exporting the ready-to-use models. The pipeline run is completely reproducible given the same code, hardware and configuration files.
The complexity of the pipeline comes from the requirement to produce an efficient model. We use Teacher-Student distillation to compress a high-quality but resource-intensive teacher model into an efficient CPU-optimized student model that still has good translation quality. We explain this further in the Compression section.
The pipeline includes many steps: compiling of components, downloading and cleaning datasets, training teacher, student and backward models, decoding, quantization, evaluation etc (more details below). The pipeline can be represented as a Directly Acyclic Graph (DAG).
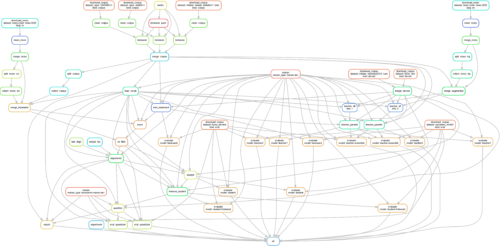
The workflow is file-based and employs self-sufficient scripts that use data on disk as input, and write intermediate and output results back to disk.
We use the Marian Neural Machine Translation engine. It is written in C++ and designed to be fast. The engine is open-sourced and used by many universities and companies, including Microsoft.
Training a quality model
The first task of the pipeline is to train a high-quality model that will be compressed later. The main challenge at this stage is to find a good parallel corpus that contains translations of the same sentences in both source and target languages and then apply appropriate cleaning procedures.
Datasets
It turned out there are many open-source parallel datasets for machine translation available on the internet. The most interesting project that aggregates such datasets is OPUS. The Annual Conference on Machine Translation also collects and distributes some datasets for competitions, for example, WMT21 Machine Translation of News. Another great source of MT corpus is the Paracrawl project.
OPUS dataset search interface:
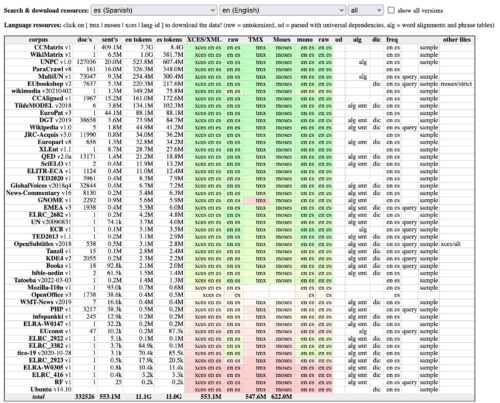
It is possible to use any dataset on disk, but automating dataset downloading from Open source resources makes adding new language pairs easy, and whenever the data set is expanded we can then easily retrain the model to take advantage of the additional data. Make sure to check the licenses of the open-source datasets before usage.
Data cleaning
Most open-source datasets are somewhat noisy. Good examples are crawled websites and translation of subtitles. Texts from websites can be poor-quality automatic translations or contain unexpected HTML, and subtitles are often free-form translations that change the meaning of the text.
It is well known in the world of Machine Learning (ML) that if we feed garbage into the model we get garbage as a result. Dataset cleaning is probably the most crucial step in the pipeline to achieving good quality.
We employ some basic cleaning techniques that work for most datasets like removing too short or too long sentences and filtering the ones with an unrealistic source to target length ratio. We also use bicleaner, a pre-trained ML classifier that attempts to indicate whether the training example in a dataset is a reversible translation. We can then remove low-scoring translation pairs that may be incorrect or otherwise add unwanted noise.
Automation is necessary when your training set is large. However, it is always recommended to look at your data manually in order to tune the cleaning thresholds and add dataset-specific fixes to get the best quality.
Data augmentation
There are more than 7000 languages spoken in the world and most of them are classified as low-resource for our purposes, meaning there is little parallel corpus data available for training. In these cases, we use a popular data augmentation strategy called back-translation.
Back-translation is a technique to increase the amount of training data available by adding synthetic translations. We get these synthetic examples by training a translation model from the target language to the source language. Then we use it to translate monolingual data from the target language into the source language, creating synthetic examples that are added to the training data for the model we actually want, from the source language to the target language.
The model
Finally, when we have a clean parallel corpus we train a big transformer model to reach the best quality we can.
Once the model converges on the augmented dataset, we fine-tune it on the original parallel corpus that doesn’t include synthetic examples from back-translation to further improve quality.
Compression
The trained model can be 800Mb or more in size depending on configuration and requires significant computing power to perform translation (decoding). At this point, it’s generally executed on GPUs and not practical to run on most consumer laptops. In the next steps we will prepare a model that works efficiently on consumer CPUs.
Knowledge distillation
The main technique we use for compression is Teacher-Student Knowledge Distillation. The idea is to decode a lot of text from the source language into the target language using the heavy model we trained (Teacher) and then train a much smaller model with fewer parameters (Student) on these synthetic translations. The student is supposed to imitate the teacher’s behavior and demonstrate similar translation quality despite being significantly faster and more compact.
We also augment the parallel corpus data with monolingual data in the source language for decoding. This improves the student by providing additional training examples of the teacher’s behavior.
Ensemble
Another trick is to use not just one teacher but an ensemble of 2-4 teachers independently trained on the same parallel corpus. It can boost quality a little bit at the cost of having to train more teachers. The pipeline supports training and decoding with an ensemble of teachers.
Quantization
One more popular technique for model compression is quantization. We use 8-bit quantization which essentially means that we store weights of the neural net as int8 instead of float32. It saves space and speeds up matrix multiplication on inference.
Other tricks
Other features worth mentioning but beyond the scope of this already lengthy article are the specialized Neural Network architecture of the student model, half-precision decoding by the teacher model to speed it up, lexical shortlists, training of word alignments, and finetuning of the quantized student.
Yes, it’s a lot! Now you can see why we wanted to have an end-to-end pipeline.
How to learn more
This work is based on a lot of research. If you are interested in the science behind the training pipeline, check out reference publications listed in the training pipeline repository README and across the wider Bergamot project. Edinburgh’s Submissions to the 2020 Machine Translation Efficiency Task is a good academic starting article. Check this tutorial by Nikolay Bogoychev for a more practical and operational explanation of the steps.
Results
The final student model is 47 times smaller and 37 times faster than the original teacher model and has only a small quality decrease!
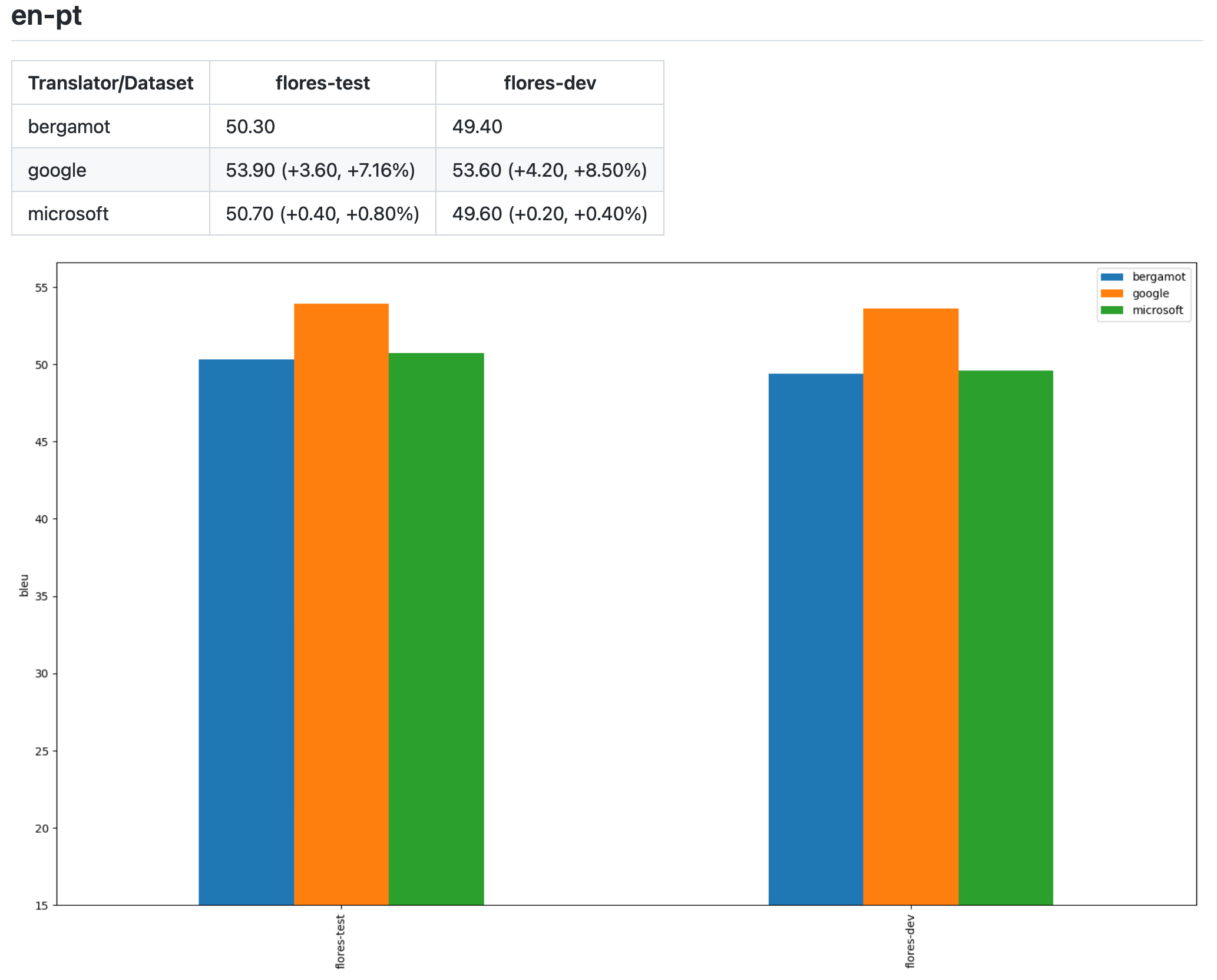
Benchmarks for en-pt model and Flores dataset:
| Model | Size | Total number of parameters | Dataset decoding time on 1 CPU core | Quality, BLEU |
| Teacher | 798Mb | 192.75M | 631s | 52.5 |
| Student quantized | 17Mb | 15.7M | 17.9s | 50.7 |
We evaluate results using MT standard BLEU scores that essentially represent how similar translated and reference texts are. This method is not perfect but it has been shown that BLEU scores correlate well with human judgment of translation quality.
We have a GitHub repository with all the trained models and evaluation results where we compare the accuracy of our models to popular APIs of cloud providers. We can see that some models perform similarly, or even outperform, the cloud providers which is a great result taking into account our model’s efficiency, reproducibility and open-source nature.
For example, here you can see evaluation results for the English to Portuguese model trained by Mozilla using open-source data only.
Anyone can train models and contribute them to our repo. Those contributions can be used in the Firefox Translations web extension and other places (see below).
Scaling
It is of course possible to run the whole pipeline on one machine, though it may take a while. Some steps of the pipeline are CPU bound and difficult to parallelize, while other steps can be offloaded to multiple GPUs. Most of the official models in the repository were trained on machines with 8 GPUs. A few steps, like teacher decoding during knowledge distillation, can take days even on well-resourced single machines. So to speed things up, we added cluster support to be able to spread different steps of the pipeline over multiple nodes.
Workflow manager
To manage this complexity we chose Snakemake which is very popular in the bioinformatics community. It uses file-based workflows, allows specifying step dependencies in Python, supports containerization and integration with different cluster software. We considered alternative solutions that focus on job scheduling, but ultimately chose Snakemake because it was more ergonomic for one-run experimentation workflows.
Example of a Snakemake rule (dependencies between rules are inferred implicitly):
rule train_teacher:
message: "Training teacher on all data"
log: f"{log_dir}/train_teacher{{ens}}.log"
conda: "envs/base.yml"
threads: gpus_num*2
resources: gpu=gpus_num
input:
rules.merge_devset.output,
train_src=f'{teacher_corpus}.{src}.gz',
train_trg=f'{teacher_corpus}.{trg}.gz',
bin=ancient(trainer),
vocab=vocab_path
output: model=f'{teacher_base_dir}{{ens}}/{best_model}'
params:
prefix_train=teacher_corpus,
prefix_test=f"{original}/devset",
dir=directory(f'{teacher_base_dir}{{ens}}'),
args=get_args("training-teacher-base")
shell: '''bash pipeline/train/train.sh \
teacher train {src} {trg} "{params.prefix_train}" \
"{params.prefix_test}" "{params.dir}" \
"{input.vocab}" {params.args} >> {log} 2>&1'''Cluster support
To parallelize workflow steps across cluster nodes we use Slurm resource manager. It is relatively simple to operate, fits well for high-performance experimentation workflows, and supports Singularity containers for easier reproducibility. Slurm is also the most popular cluster manager for High-Performance Computers (HPC) used for model training in academia, and most of the consortium partners were already using or familiar with it.
How to start training
The workflow is quite resource-intensive, so you’ll need a pretty good server machine or even a cluster. We recommend using 4-8 Nvidia 2080-equivalent or better GPUs per machine.
Clone https://github.com/mozilla/firefox-translations-training and follow the instructions in the readme for configuration.
The most important part is to find parallel datasets and properly configure settings based on your available data and hardware. You can learn more about this in the readme.
How to use the existing models
The existing models are shipped with the Firefox Translations web extension, enabling users to translate web pages in Firefox. The models are downloaded to a local machine on demand. The web extension uses these models with the bergamot-translator Marian wrapper compiled to Web Assembly.
Also, there is a playground website at https://mozilla.github.io/translate where you can input text and translate it right away, also locally but served as a static website instead of a browser extension.
If you are interested in an efficient NMT inference on the server, you can try a prototype HTTP service that uses bergamot-translator natively compiled, instead of compiled to WASM.
Or follow the build instructions in the bergamot-translator readme to directly use the C++, JavaScript WASM, or Python bindings.
Conclusion
It is fascinating how far Machine Translation research has come in recent years. Local high-quality translations are the future and it’s becoming more and more practical for companies and researchers to train such models even without access to proprietary data or large-scale computing power.
We hope that Firefox Translations will set a new standard of privacy-preserving, efficient, open-source machine translation accessible for all.
Acknowledgements
I would like to thank all the participants of the Bergamot Project for making this technology possible, my teammates Andre Natal and Abhishek Aggarwal for the incredible work they have done bringing Firefox Translations to life, Lonnen for managing the project and editing this blog post and of course awesome Mozilla community for helping with localization of the web-extension and testing its early builds.
This project has received funding from the European Union’s Horizon 2020 research and innovation programme under grant agreement No 825303
About Evgeny Pavlov
Evgeny is a Senior Software Engineer at Mozilla. He works on Applied Machine Learning projects.