
On January 13th 2022, Firefox became unusable for close to two hours for users worldwide. This incident interrupted many people’s workflow. This post highlights the complex series of events and circumstances that, together, triggered a bug deep in the networking code of Firefox.
What Happened?
Firefox has a number of servers and related infrastructure that handle several internal services. These include updates, telemetry, certificate management, crash reporting and other similar functionality. This infrastructure is hosted by different cloud service providers that use load balancers to distribute the load evenly across servers. For those services hosted on Google Cloud Platform (GCP) these load balancers have settings related to the HTTP protocol they should advertise and one of these settings is HTTP/3 support with three states: “Enabled”, “Disabled” or “Automatic (default)”. Our load balancers were set to the “Automatic (default)” setting and on January 13, 2022 at 07:28 UTC, GCP deployed an unannounced change to make HTTP/3 the default. As Firefox uses HTTP/3 when supported, from that point forward, some connections that Firefox makes to the services infrastructure would use HTTP/3 instead of the previously used HTTP/2 protocol.¹
Shortly after, we noticed a spike in crashes being reported through our crash reporter and also received several reports from inside and outside of Mozilla describing a hang of the browser.
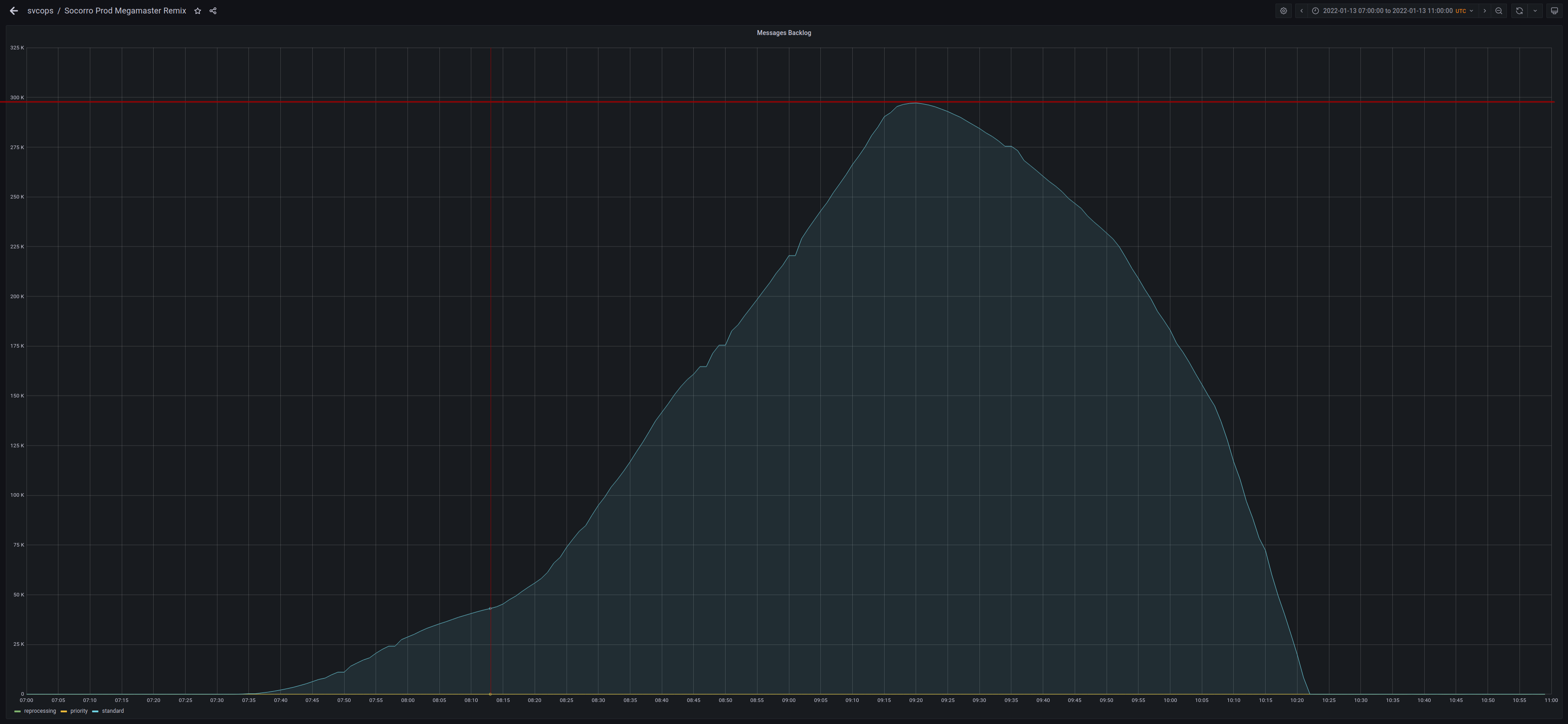
Backlog of pending crash reports building up and reaching close to 300K unprocessed reports.
As part of the incident response process, we quickly discovered that the client was hanging inside a network request to one of the Firefox internal services. However, at this point we neither had an explanation for why this would trigger just now, nor what the scope of the problem was. We continued to look for the “trigger” — some change that must have occurred to start the problem. We found that we had not shipped updates or configuration changes that could have caused this problem. At the same time, we were keeping in mind that HTTP/3 had been enabled since Firefox 88 and was actively used by some popular websites.
Although we couldn’t see it, we suspected that there had been some kind of “invisible” change rolled out by one of our cloud providers that somehow modified load balancer behavior. On closer inspection, none of our settings were changed. We then discovered through logs that for some reason, the load balancers for our Telemetry service were serving HTTP/3 connections while they hadn’t done that before. We disabled HTTP/3 explicitly on GCP at 09:12 UTC. This unblocked our users, but we were not yet certain about the root cause and without knowing that, it was impossible for us to tell if this would affect additional HTTP/3 connections.
¹ Some highly critical services such as updates use a special beConservative flag that prevents the use of any experimental technology for their connections (e.g. HTTP/3).
A Special Mix of Ingredients
It quickly became clear to us that there must be some combination of special circumstances for the hang to occur. We performed a number of tests with various tools and remote services and were not able to reproduce the problem, not even with a regular connection to the Telemetry staging server (a server only used for testing deployments, which we had left in its original configuration for testing purposes). With Firefox itself, however, we were able to reproduce the issue with the staging server.
After further debugging, we found the “special ingredient” required for this bug to happen. All HTTP/3 connections go through Necko, our networking stack. However, Rust components that need direct network access are not using Necko directly, but are calling into it through an intermediate library called viaduct.
In order to understand why this mattered, we first need to understand some things about the internals of Necko, in particular about HTTP/3 upload requests. For such requests, the higher-level Necko APIs² check if the Content-Length header is present and if it isn’t, it will automatically be added. The lower-level HTTP/3 code later relies on this header to determine the request size. This works fine for web content and other requests in our code.
When requests pass through viaduct first, however, viaduct will lower-case each header and pass it on to Necko. And here is the problem: the API checks in Necko are case-insensitive while the lower-level HTTP/3 code is case-sensitive. So if any code was to add a Content-Length header and pass the request through viaduct, it would pass the Necko API checks but the HTTP/3 code would not find the header.
It just so happens that Telemetry is currently the only Rust-based component in Firefox Desktop that uses the network stack and adds a Content-Length header. This is why users who disabled Telemetry would see this problem resolved even though the problem is not related to Telemetry functionality itself and could have been triggered otherwise.

A specific code path was required to trigger the problem in the HTTP/3 protocol implementation.
² These are internal APIs, not accessible to web content.
The Infinite Loop
With the load balancer change in place, and a special code path in a new Rust service now active, the necessary final ingredient to trigger the problem for users was deep in Necko HTTP/3 code.
When handling a request, the code looked up the field in a case-sensitive way and failed to find the header as it had been lower-cased by viaduct. Without the header, the request was determined by the Necko code to be complete, leaving the real request body unsent. However, this code would only terminate when there was no additional content to send. This unexpected state caused the code to loop indefinitely rather than returning an error. Because all network requests go through one socket thread, this loop blocked any further network communication and made Firefox unresponsive, unable to load web content.
Lessons Learned
As so often is the case, the issue was a lot more complex than it appeared at first glance and there were many contributing factors working together. Some of the key factors we have identified include:
-
GCP’s deployment of HTTP/3 as default was unannounced. We are actively working with them to improve the situation. We realize that an announcement (as is usually sent) might not have entirely mitigated the risk of an incident, but it would likely have triggered more controlled experiments (e.g. in a staging environment) and deployment.
-
Our setting of “Automatic (default)” on the load balancers instead of a more explicit choice allowed the deployment to take place automatically. We are reviewing all service configurations to avoid similar mistakes in the future.
-
The particular combination of HTTP/3 and
viaducton Firefox Desktop was not covered in our continuous integration system. While we cannot test every possible combination of configurations and components, the choice of HTTP version is a fairly major change that should have been tested, as well as the use of an additional networking layer likeviaduct. Current HTTP/3 tests cover the low-level protocol behavior and the Necko layer as it is used by web content. We should run more system tests with different HTTP versions and doing so could have revealed this problem.
We are also investigating action points both to make the browser more resilient towards such problems and to make incident response even faster. Learning as much as possible from this incident will help us improve the quality of our products. We’re grateful to all the users who have sent crash reports, worked with us in Bugzilla or helped others to work around the problem.
About Christian Holler
Christian is a Firefox Tech Lead and Senior Staff Security Engineer at Mozilla.
5 comments