
People are excited about running WebAssembly outside the browser.
That excitement isn’t just about WebAssembly running in its own standalone runtime. People are also excited about running WebAssembly from languages like Python, Ruby, and Rust.
Why would you want to do that? A few reasons:
- Make “native” modules less complicated
Runtimes like Node or Python’s CPython often allow you to write modules in low-level languages like C++, too. That’s because these low-level languages are often much faster. So you can use native modules in Node, or extension modules in Python. But these modules are often hard to use because they need to be compiled on the user’s device. With a WebAssembly “native” module, you can get most of the speed without the complication. - Make it easier to sandbox native code
On the other hand, low-level languages like Rust wouldn’t use WebAssembly for speed. But they could use it for security. As we talked about in the WASI announcement, WebAssembly gives you lightweight sandboxing by default. So a language like Rust could use WebAssembly to sandbox native code modules. - Share native code across platforms
Developers can save time and reduce maintainance costs if they can share the same codebase across different platforms (e.g. between the web and a desktop app). This is true for both scripting and low-level languages. And WebAssembly gives you a way to do that without making things slower on these platforms.

So WebAssembly could really help other languages with important problems.
But with today’s WebAssembly, you wouldn’t want to use it in this way. You can run WebAssembly in all of these places, but that’s not enough.
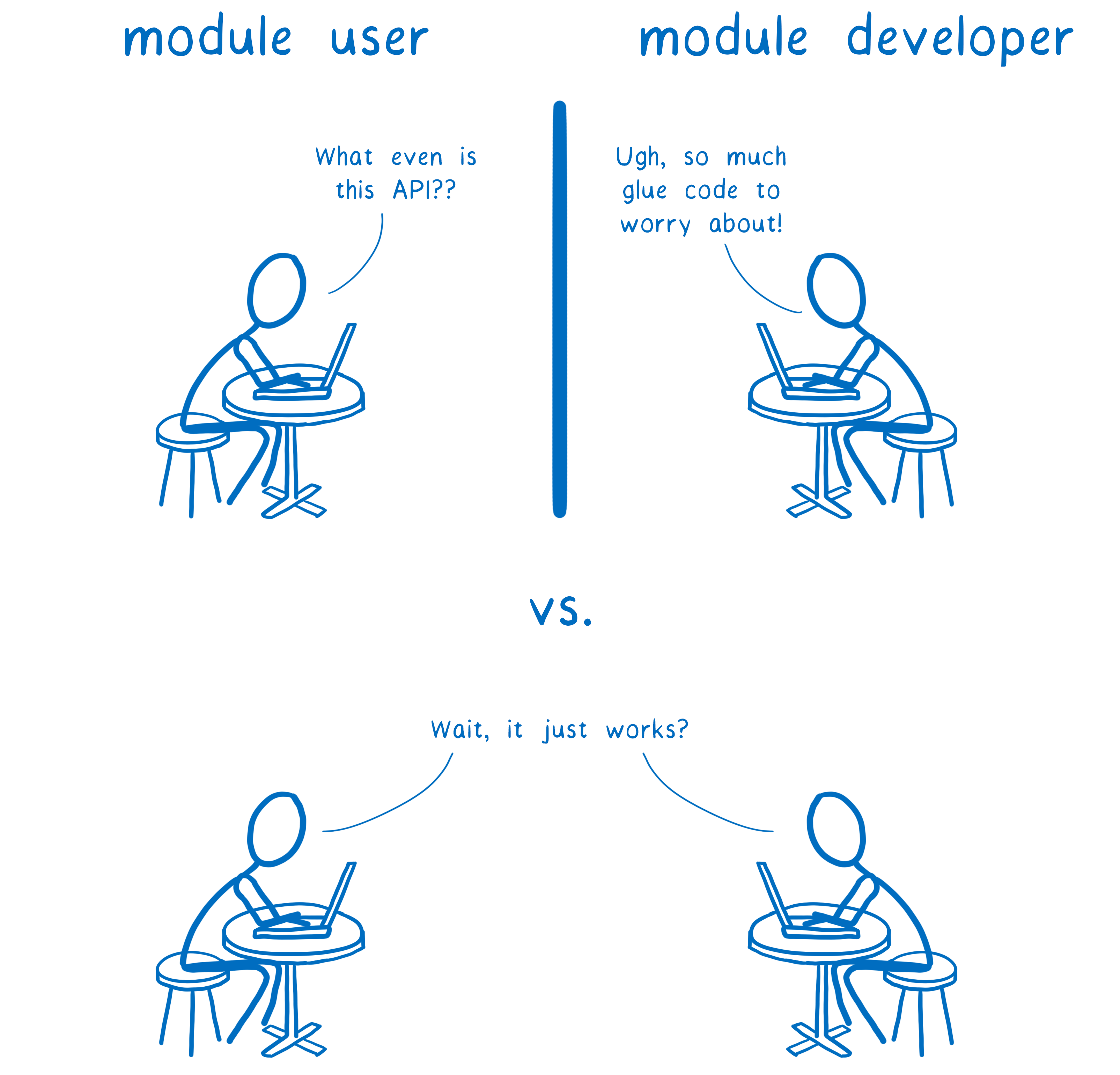
Right now, WebAssembly only talks in numbers. This means the two languages can call each other’s functions.
But if a function takes or returns anything besides numbers, things get complicated. You can either:
- Ship one module that has a really hard-to-use API that only speaks in numbers… making life hard for the module’s user.
- Add glue code for every single environment you want this module to run in… making life hard for the module’s developer.
But this doesn’t have to be the case.
It should be possible to ship a single WebAssembly module and have it run anywhere… without making life hard for either the module’s user or developer.
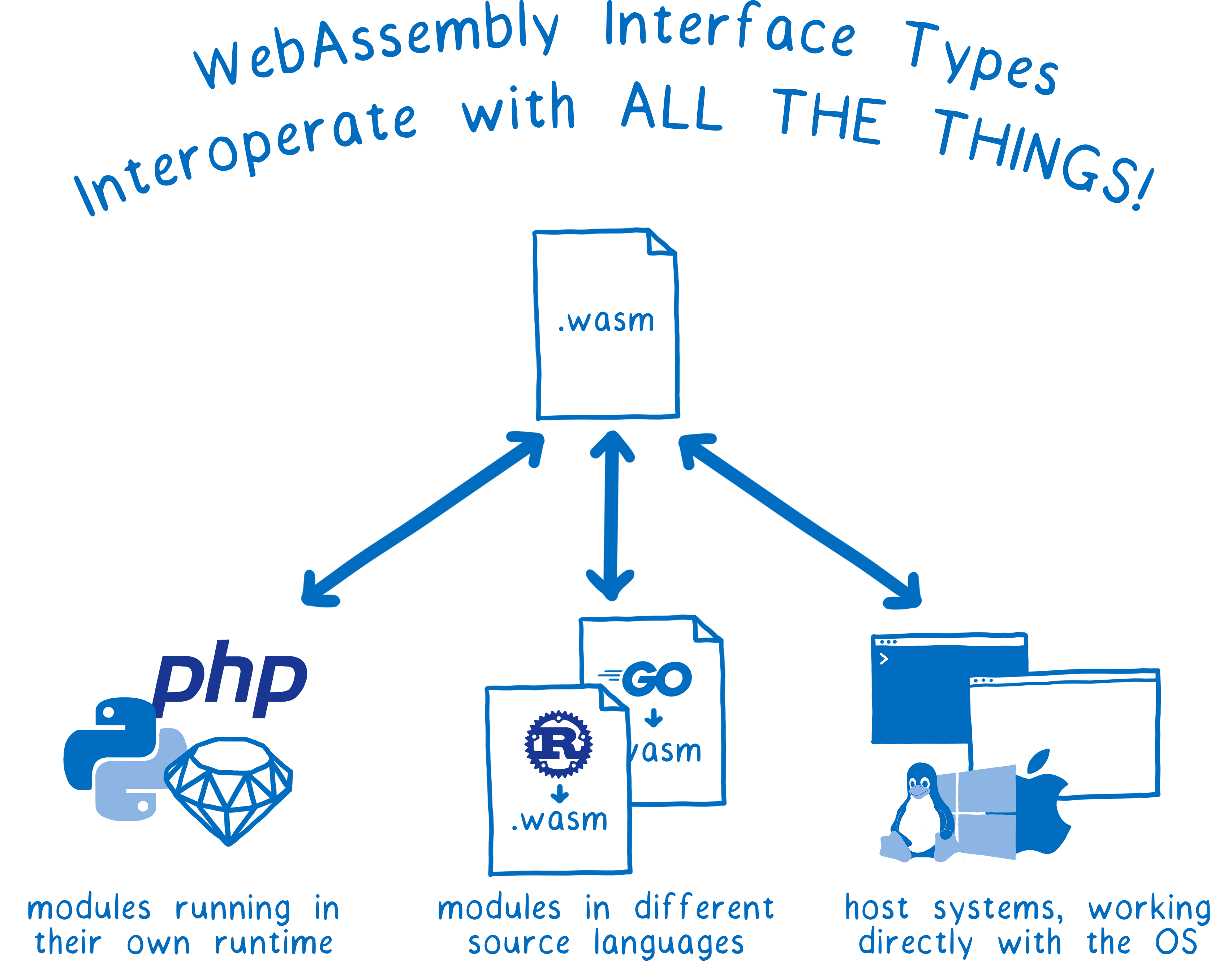
So the same WebAssembly module could use rich APIs, using complex types, to talk to:
- Modules running in their own native runtime (e.g. Python modules running in a Python runtime)
- Other WebAssembly modules written in different source languages (e.g. a Rust module and a Go module running together in the browser)
- The host system itself (e.g. a WASI module providing the system interface to an operating system or the browser’s APIs)
And with a new, early-stage proposal, we’re seeing how we can make this Just Work™, as you can see in this demo.
So let’s take a look at how this will work. But first, let’s look at where we are today and the problems that we’re trying to solve.
WebAssembly talking to JS
WebAssembly isn’t limited to the web. But up to now, most of WebAssembly’s development has focused on the Web.
That’s because you can make better designs when you focus on solving concrete use cases. The language was definitely going to have to run on the Web, so that was a good use case to start with.
This gave the MVP a nicely contained scope. WebAssembly only needed to be able to talk to one language—JavaScript.
And this was relatively easy to do. In the browser, WebAssembly and JS both run in the same engine, so that engine can help them efficiently talk to each other.
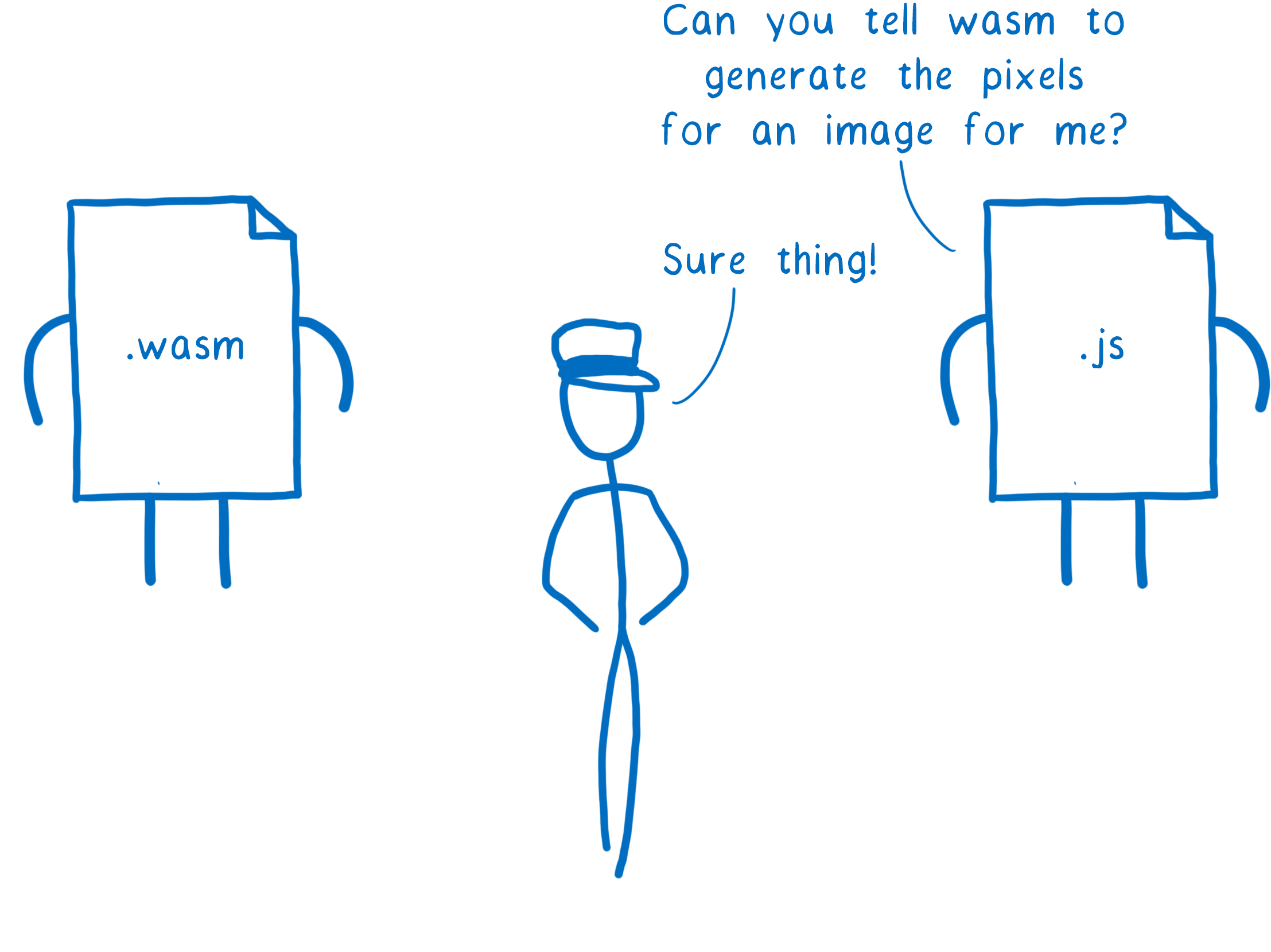
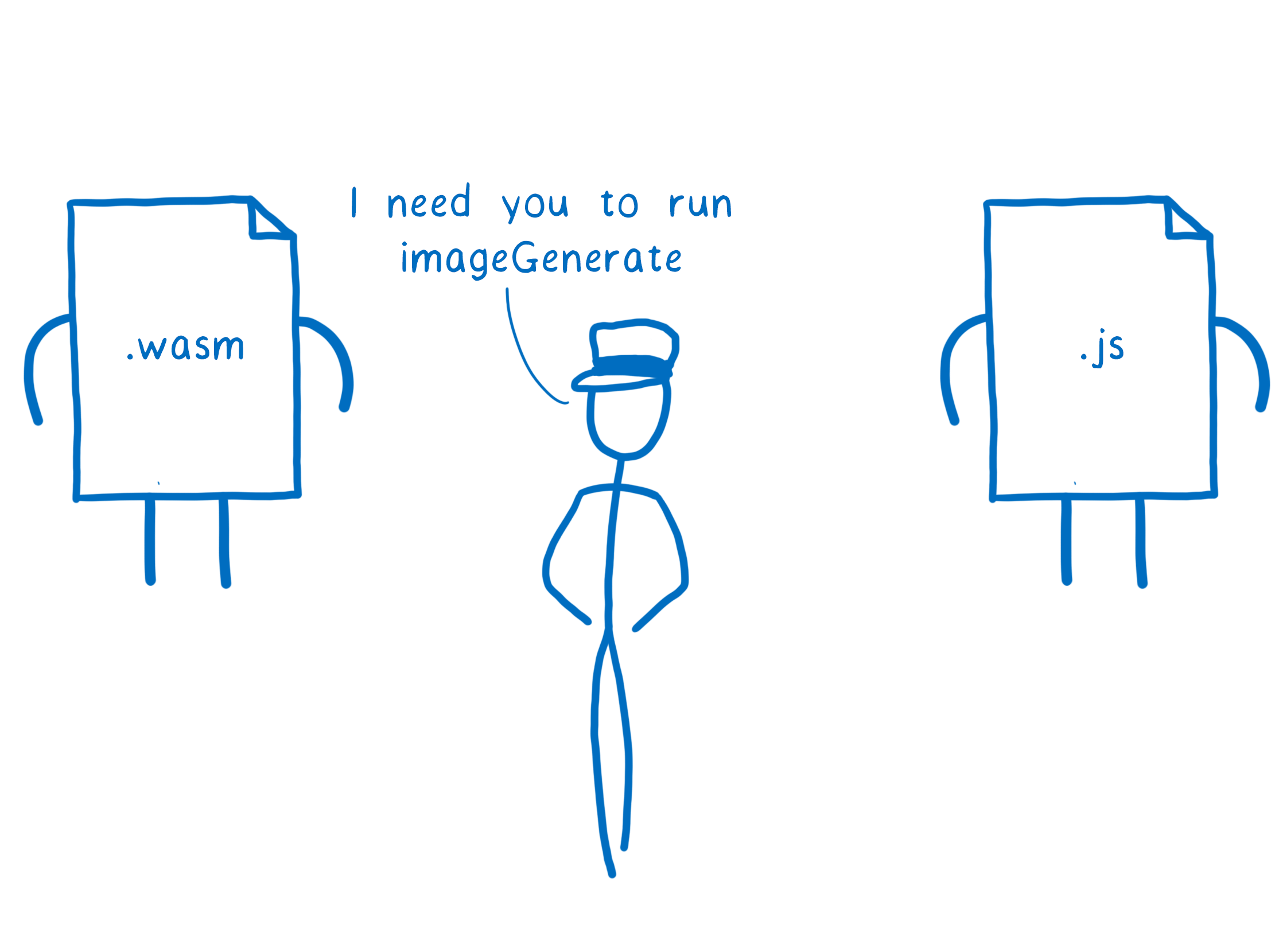
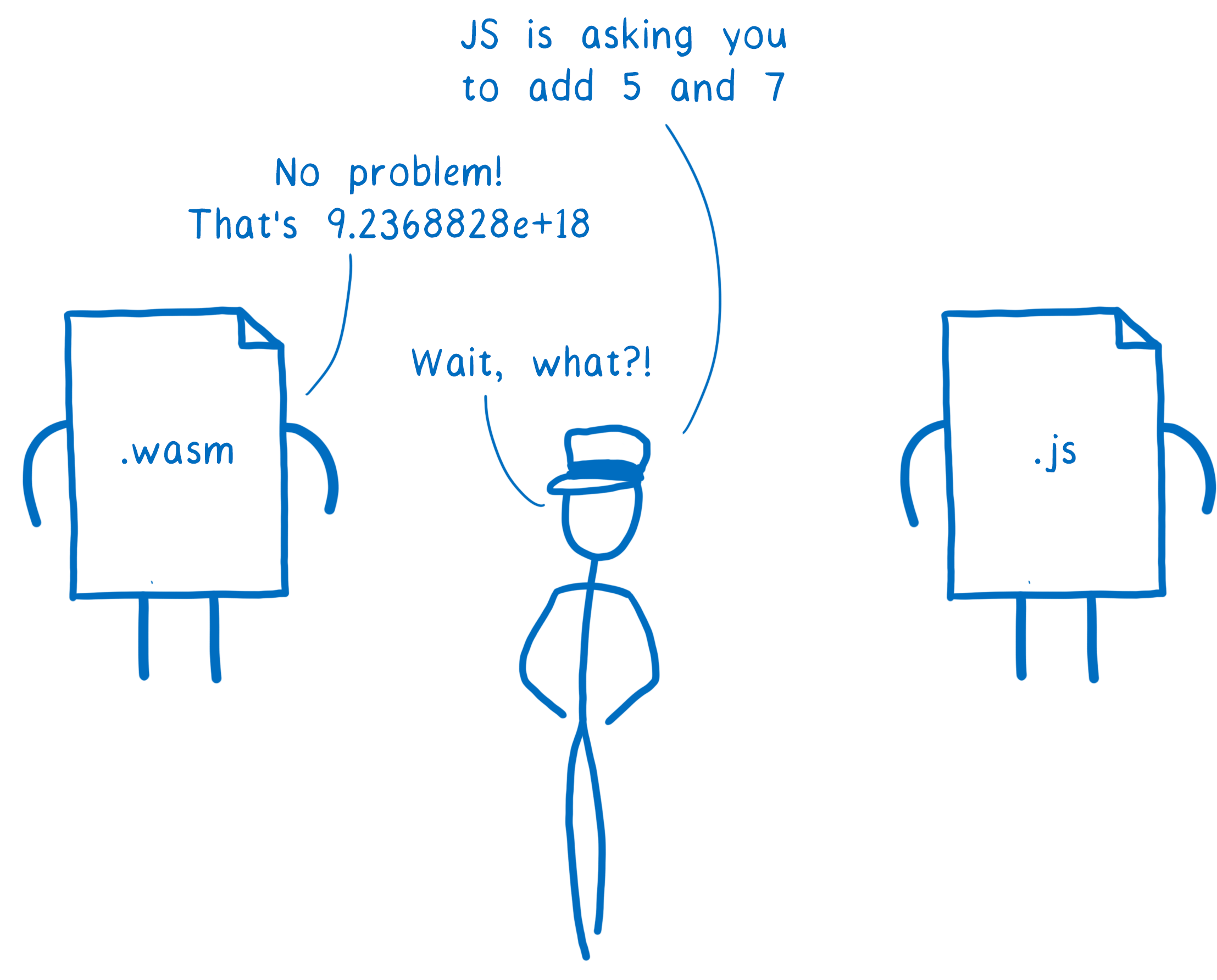
But there is one problem when JS and WebAssembly try to talk to each other… they use different types.
Currently, WebAssembly can only talk in numbers. JavaScript has numbers, but also quite a few more types.
And even the numbers aren’t the same. WebAssembly has 4 different kinds of numbers: int32, int64, float32, and float64. JavaScript currently only has Number (though it will soon have another number type, BigInt).
The difference isn’t just in the names for these types. The values are also stored differently in memory.
First off, in JavaScript any value, no matter the type, is put in something called a box (and I explained boxing more in another article).
WebAssembly, in contrast, has static types for its numbers. Because of this, it doesn’t need (or understand) JS boxes.
This difference makes it hard to communicate with each other.
But if you want to convert a value from one number type to the other, there are pretty straightforward rules.
Because it’s so simple, it’s easy to write down. And you can find this written down in WebAssembly’s JS API spec.

This mapping is hardcoded in the engines.
It’s kind of like the engine has a reference book. Whenever the engine has to pass parameters or return values between JS and WebAssembly, it pulls this reference book off the shelf to see how to convert these values.

Having such a limited set of types (just numbers) made this mapping pretty easy. That was great for an MVP. It limited how many tough design decisions needed to be made.
But it made things more complicated for the developers using WebAssembly. To pass strings between JS and WebAssembly, you had to find a way to turn the strings into an array of numbers, and then turn an array of numbers back into a string. I explained this in a previous post.

This isn’t difficult, but it is tedious. So tools were built to abstract this away.
For example, tools like Rust’s wasm-bindgen and Emscripten’s Embind automatically wrap the WebAssembly module with JS glue code that does this translation from strings to numbers.
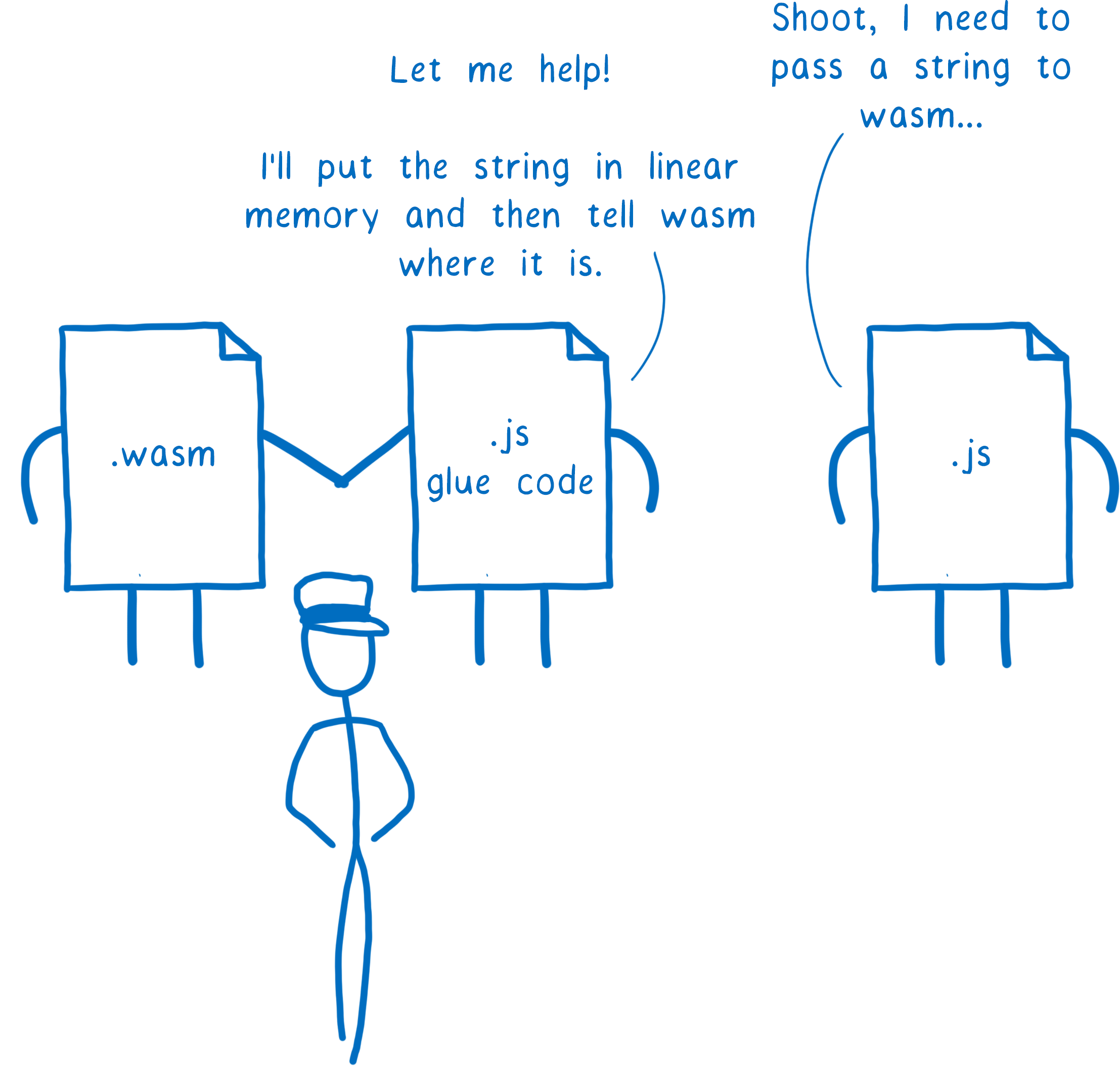
And these tools can do these kinds of transformations for other high-level types, too, such as complex objects with properties.
This works, but there are some pretty obvious use cases where it doesn’t work very well.
For example, sometimes you just want to pass a string through WebAssembly. You want a JavaScript function to pass a string to a WebAssembly function, and then have WebAssembly pass it to another JavaScript function.
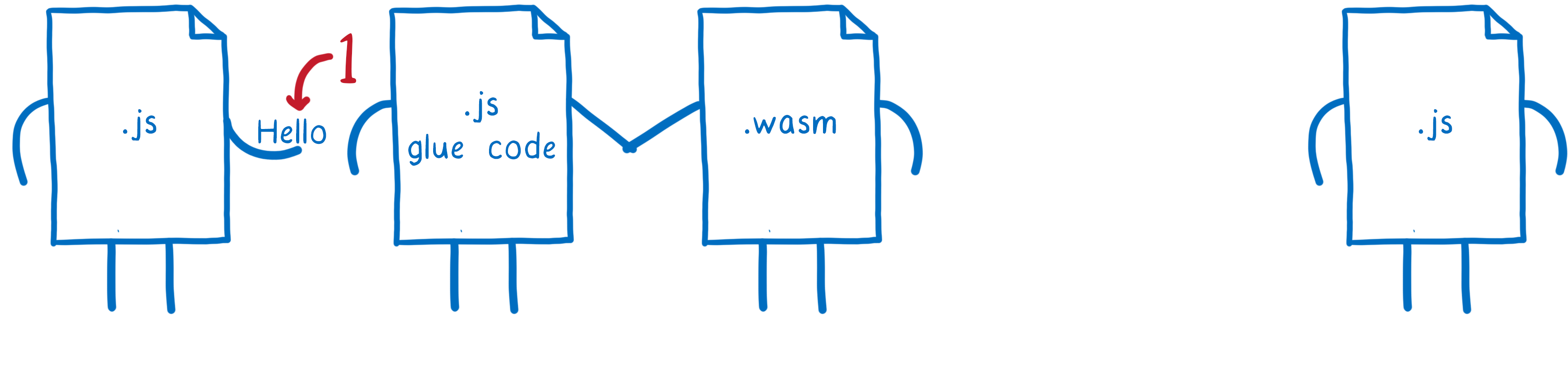
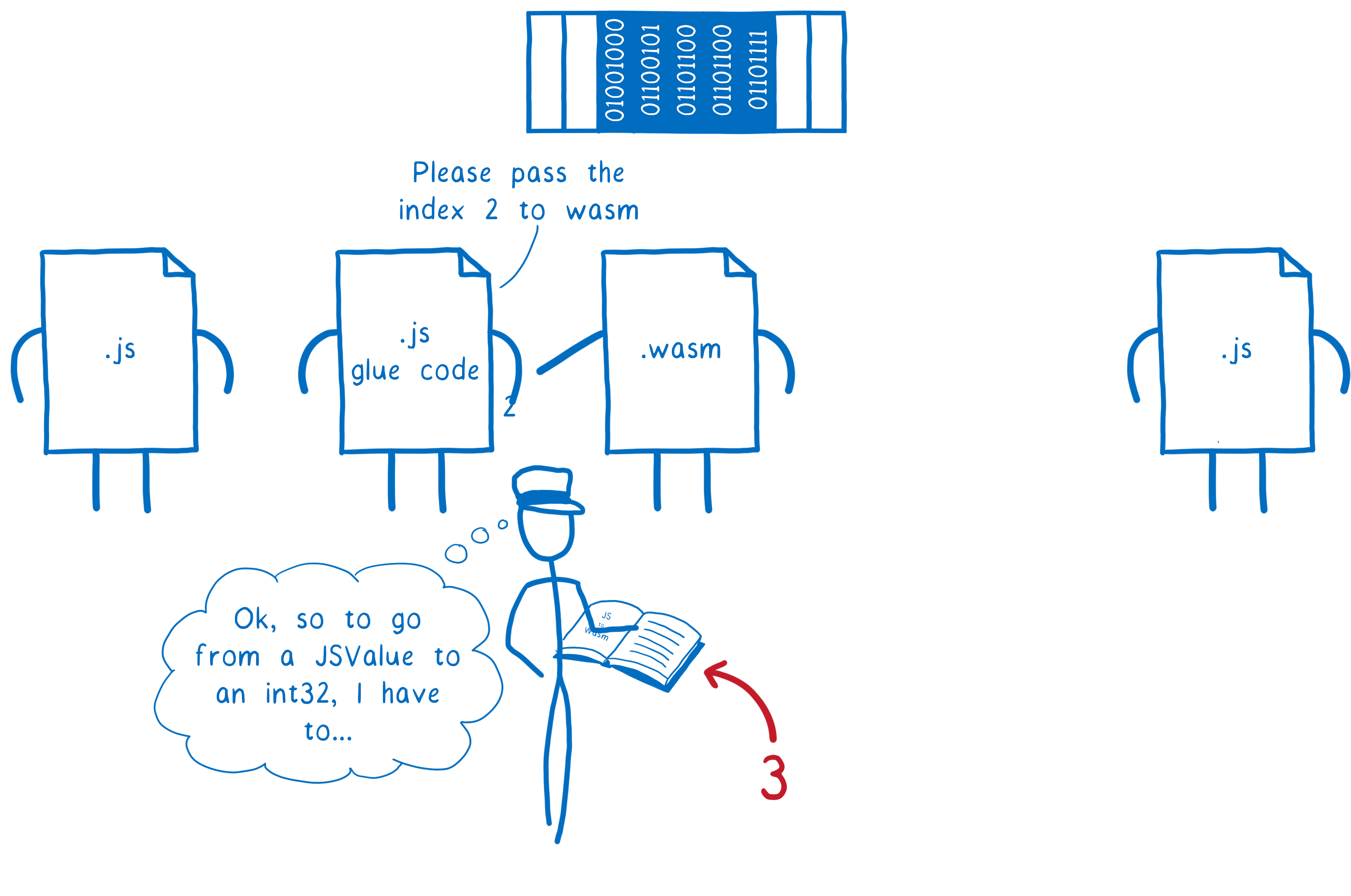
Here’s what needs to happen for that to work:
- the first JavaScript function passes the string to the JS glue code
-
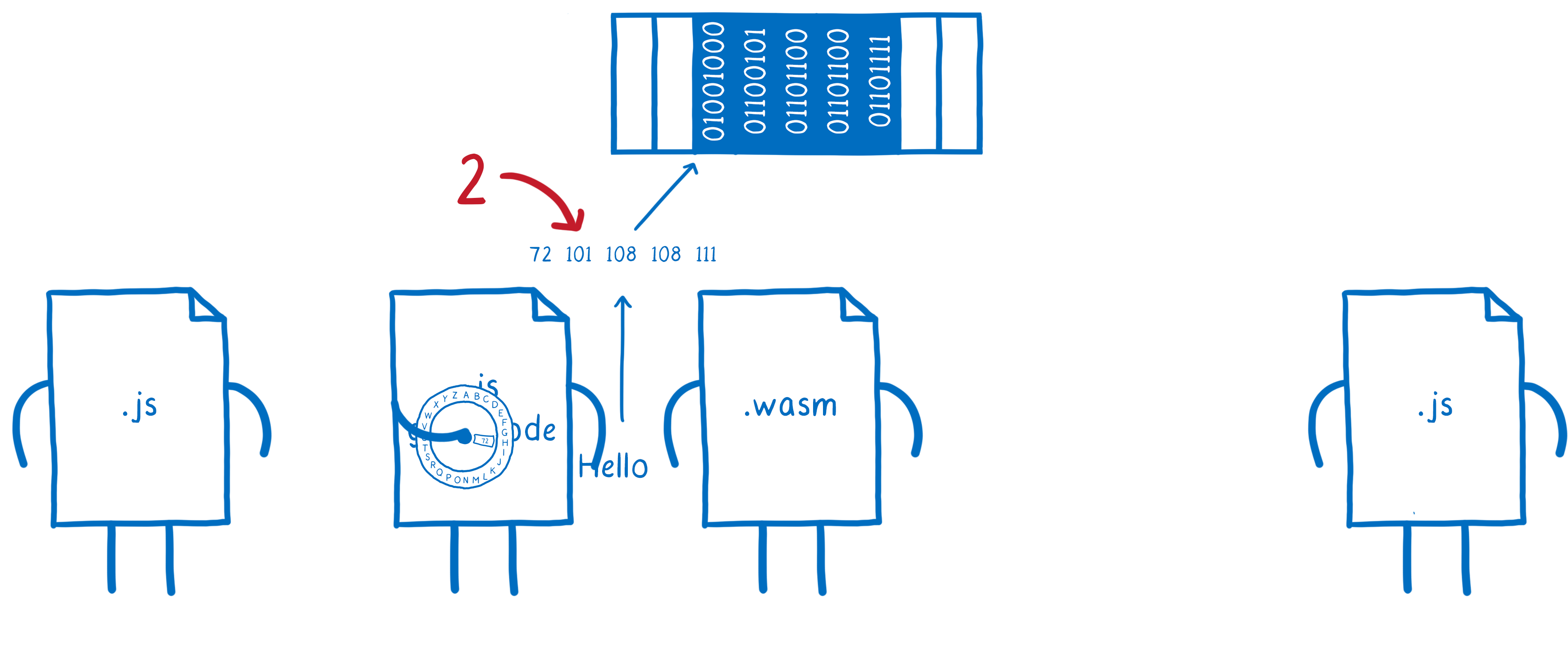
the JS glue code turns that string object into numbers and then puts those numbers into linear memory
-
then passes a number (a pointer to the start of the string) to WebAssembly
-
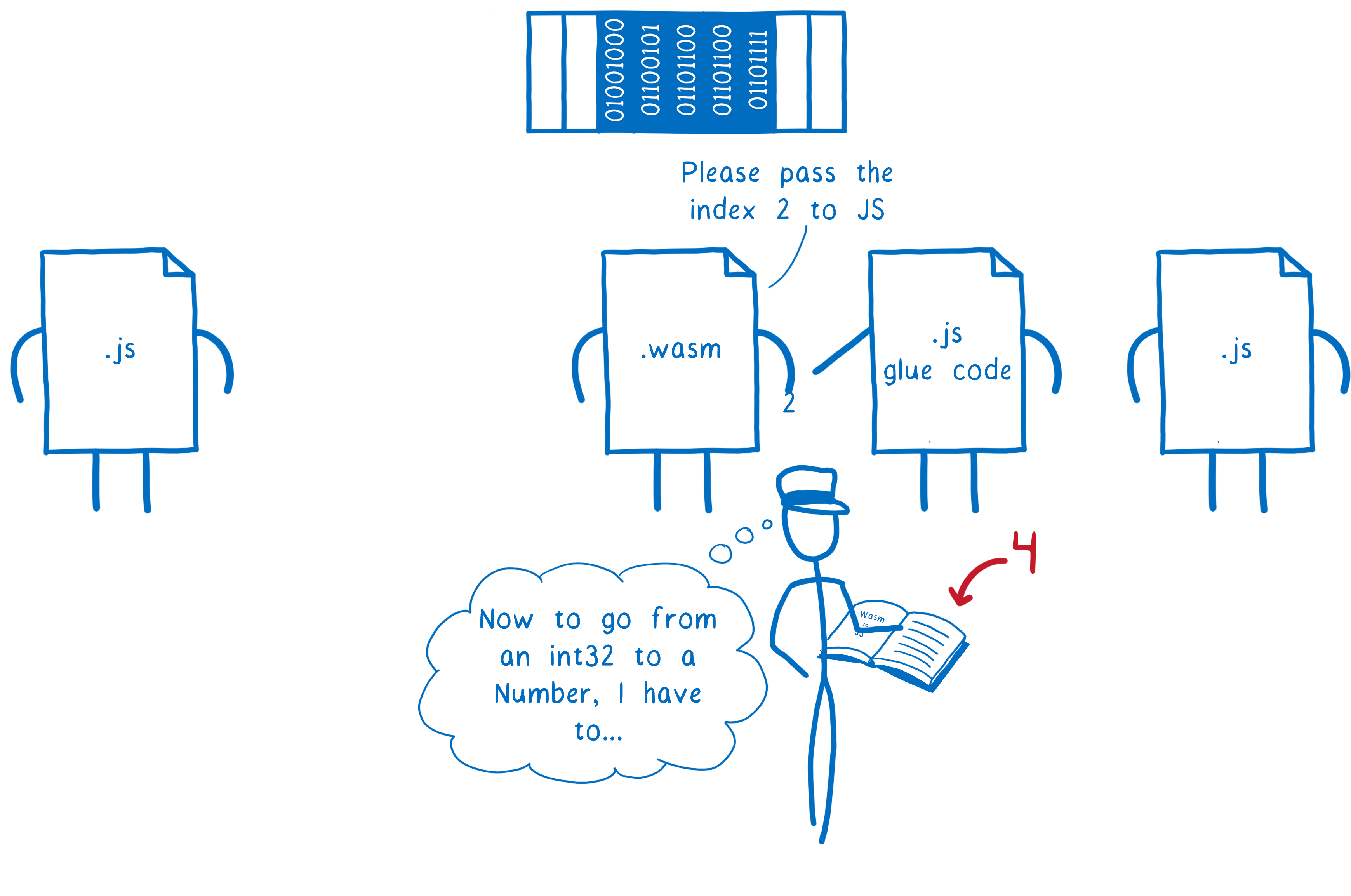
the WebAssembly function passes that number over to the JS glue code on the other side
-
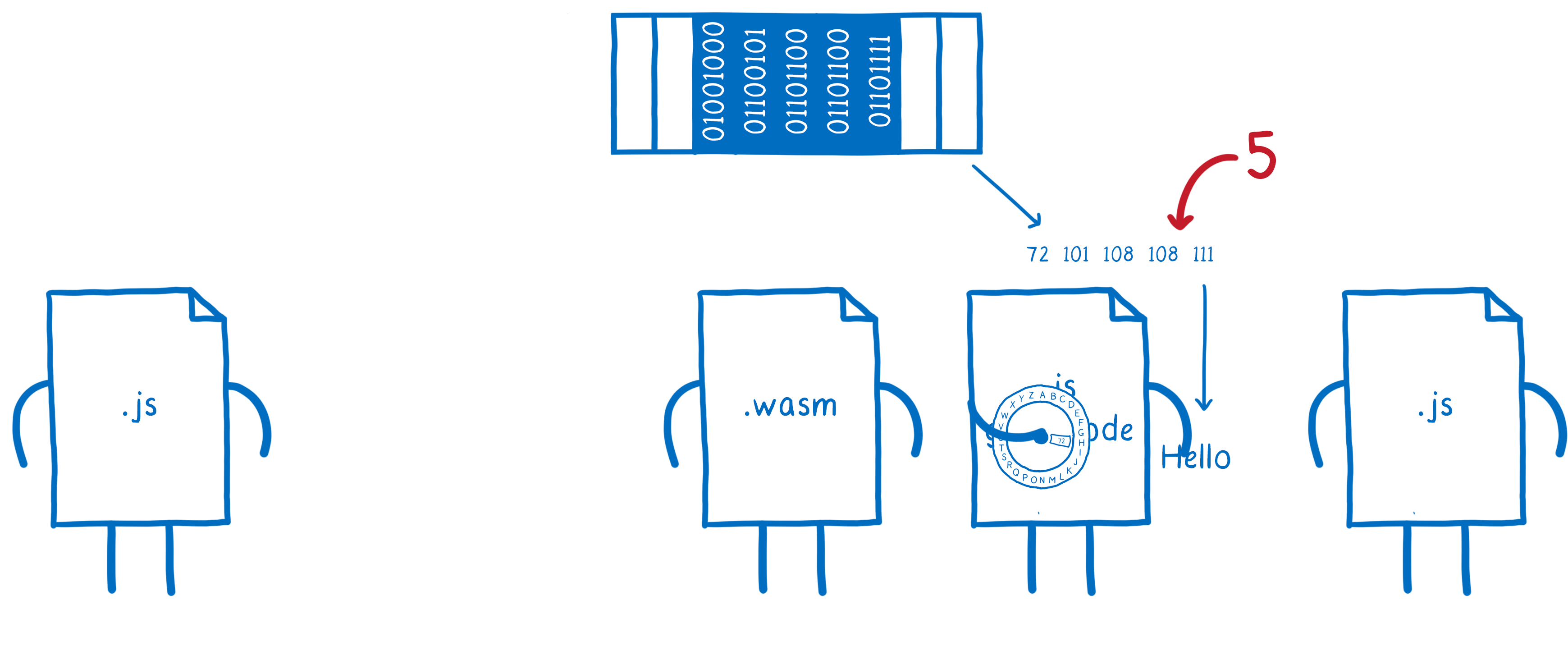
the second JavaScript function pulls all of those numbers out of linear memory and then decodes them back into a string object
-
which it gives to the second JS function
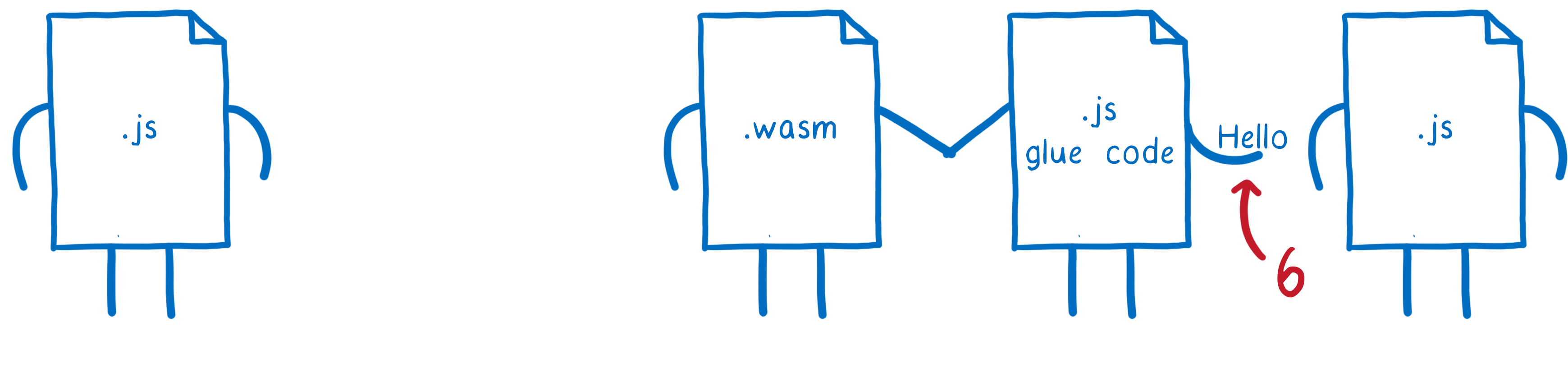
So the JS glue code on one side is just reversing the work it did on the other side. That’s a lot of work to recreate what’s basically the same object.
If the string could just pass straight through WebAssembly without any transformations, that would be way easier.
WebAssembly wouldn’t be able to do anything with this string—it doesn’t understand that type. We wouldn’t be solving that problem.
But it could just pass the string object back and forth between the two JS functions, since they do understand the type.
So this is one of the reasons for the WebAssembly reference types proposal. That proposal adds a new basic WebAssembly type called anyref.
With an anyref, JavaScript just gives WebAssembly a reference object (basically a pointer that doesn’t disclose the memory address). This reference points to the object on the JS heap. Then WebAssembly can pass it to other JS functions, which know exactly how to use it.

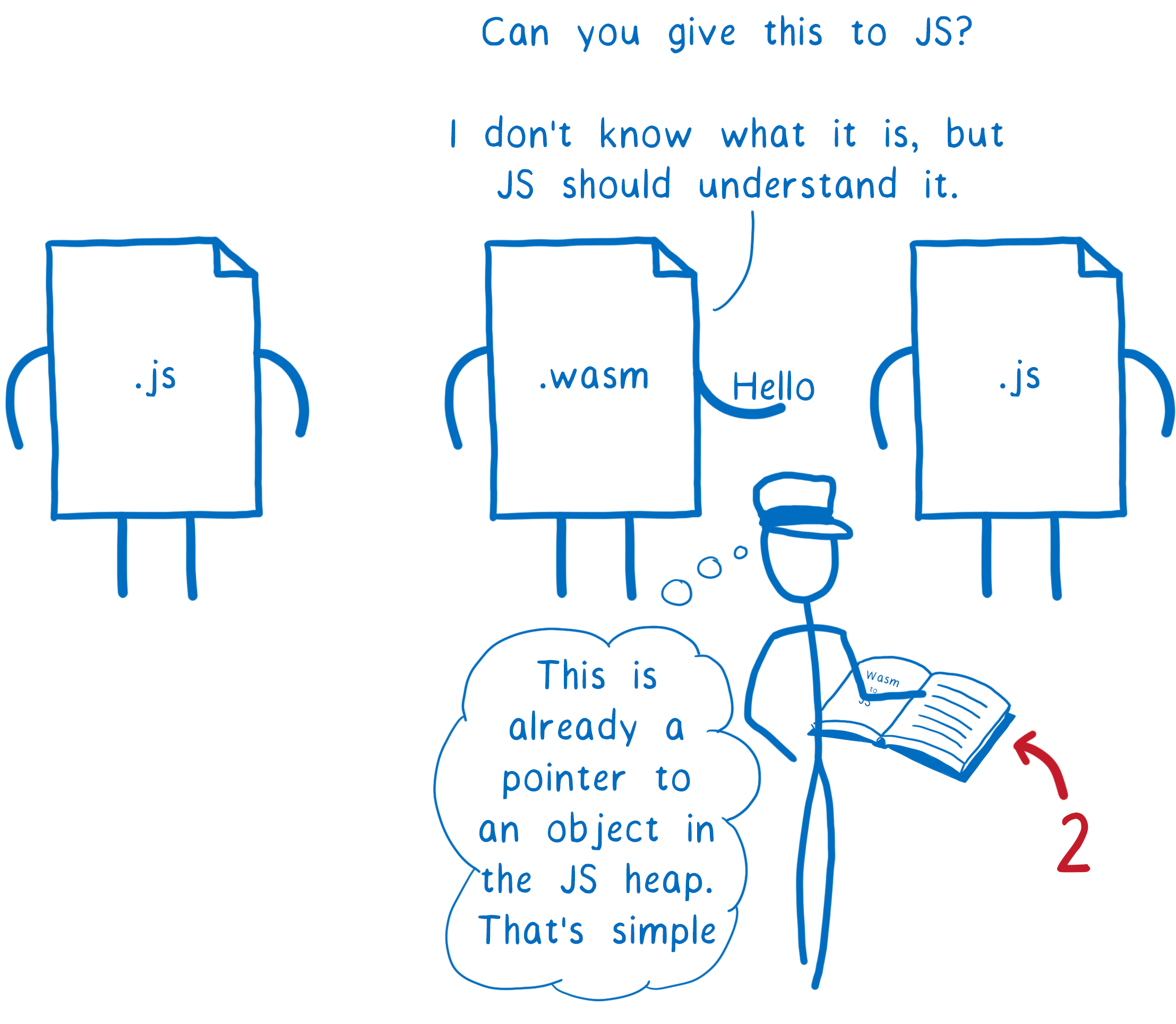
So that solves one of the most annoying interoperability problems with JavaScript. But that’s not the only interoperability problem to solve in the browser.
There’s another, much larger, set of types in the browser. WebAssembly needs to be able to interoperate with these types if we’re going to have good performance.
WebAssembly talking directly to the browser
JS is only one part of the browser. The browser also has a lot of other functions, called Web APIs, that you can use.
Behind the scenes, these Web API functions are usually written in C++ or Rust. And they have their own way of storing objects in memory.
Web APIs’ parameters and return values can be lots of different types. It would be hard to manually create mappings for each of these types. So to simplify things, there’s a standard way to talk about the structure of these types—Web IDL.
When you’re using these functions, you’re usually using them from JavaScript. This means you are passing in values that use JS types. How does a JS type get converted to a Web IDL type?
Just as there is a mapping from WebAssembly types to JavaScript types, there is a mapping from JavaScript types to Web IDL types.
So it’s like the engine has another reference book, showing how to get from JS to Web IDL. And this mapping is also hardcoded in the engine.
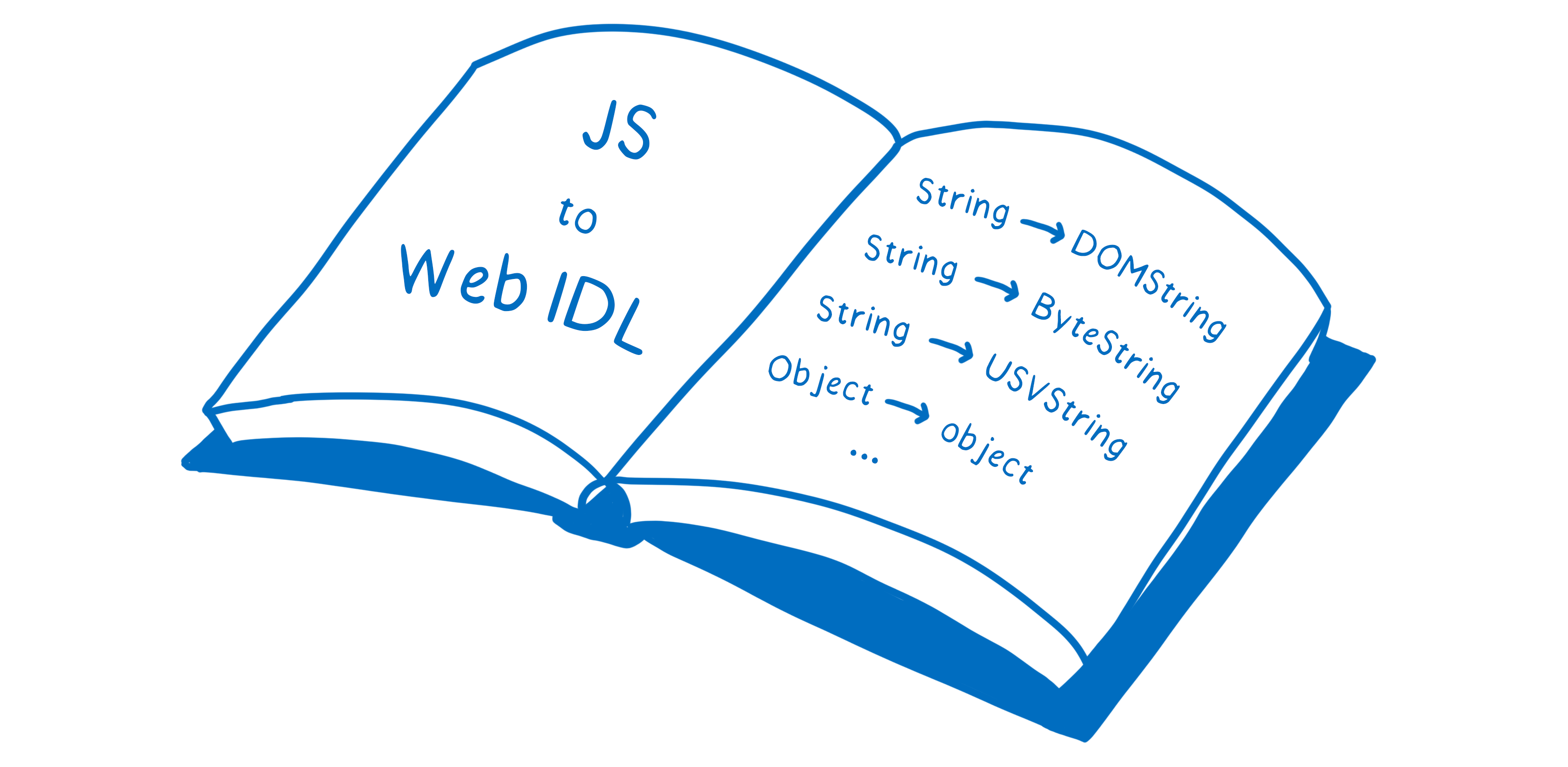
For many types, this mapping between JavaScript and Web IDL is pretty straightforward. For example, types like DOMString and JS’s String are compatible and can be mapped directly to each other.
Now, what happens when you’re trying to call a Web API from WebAssembly? Here’s where we get to the problem.
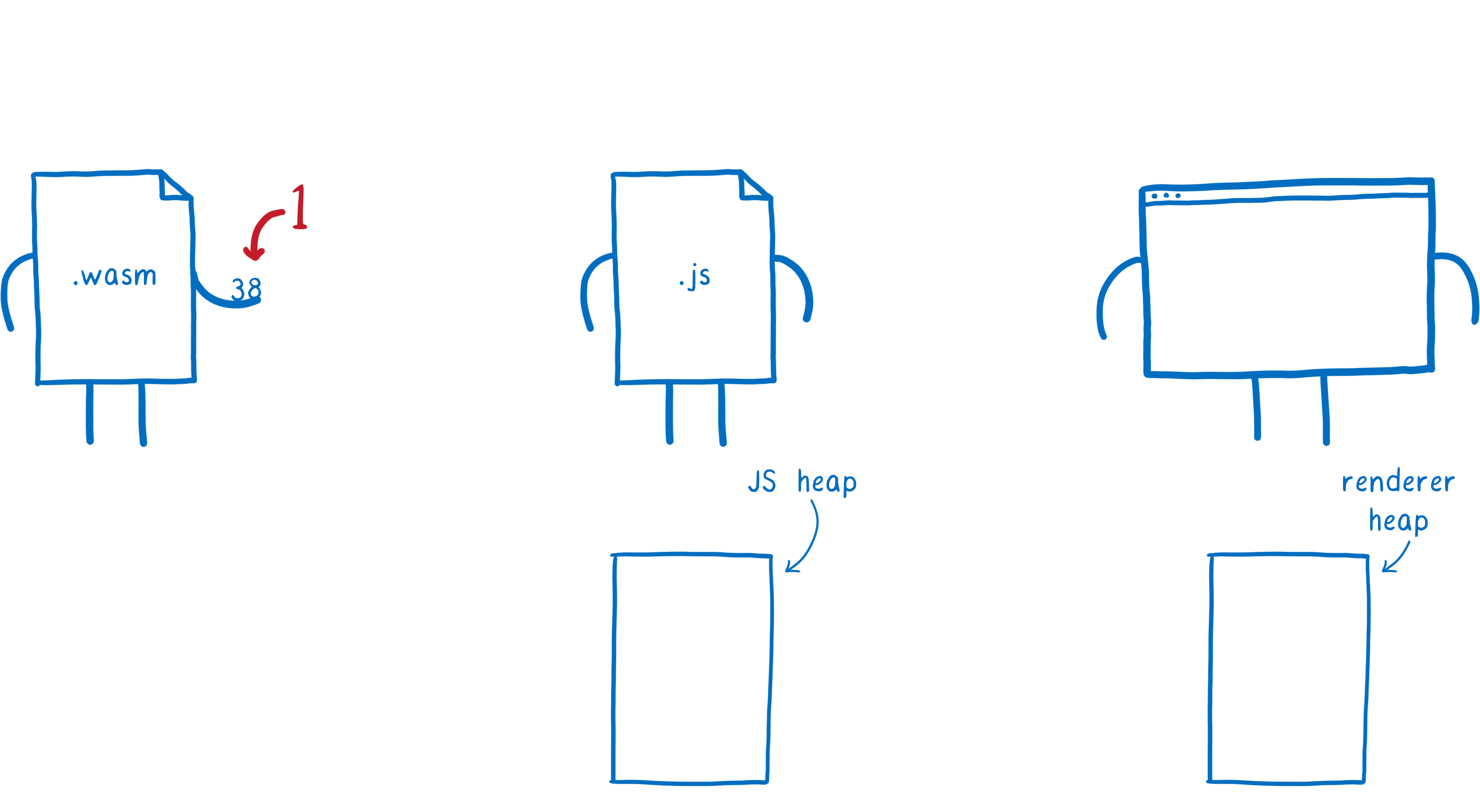
Currently, there is no mapping between WebAssembly types and Web IDL types. This means that, even for simple types like numbers, your call has to go through JavaScript.
Here’s how this works:
- WebAssembly passes the value to JS.
- In the process, the engine converts this value into a JavaScript type, and puts it in the JS heap in memory
- Then, that JS value is passed to the Web API function. In the process, the engine converts the JS value into a Web IDL type, and puts it in a different part of memory, the renderer’s heap.
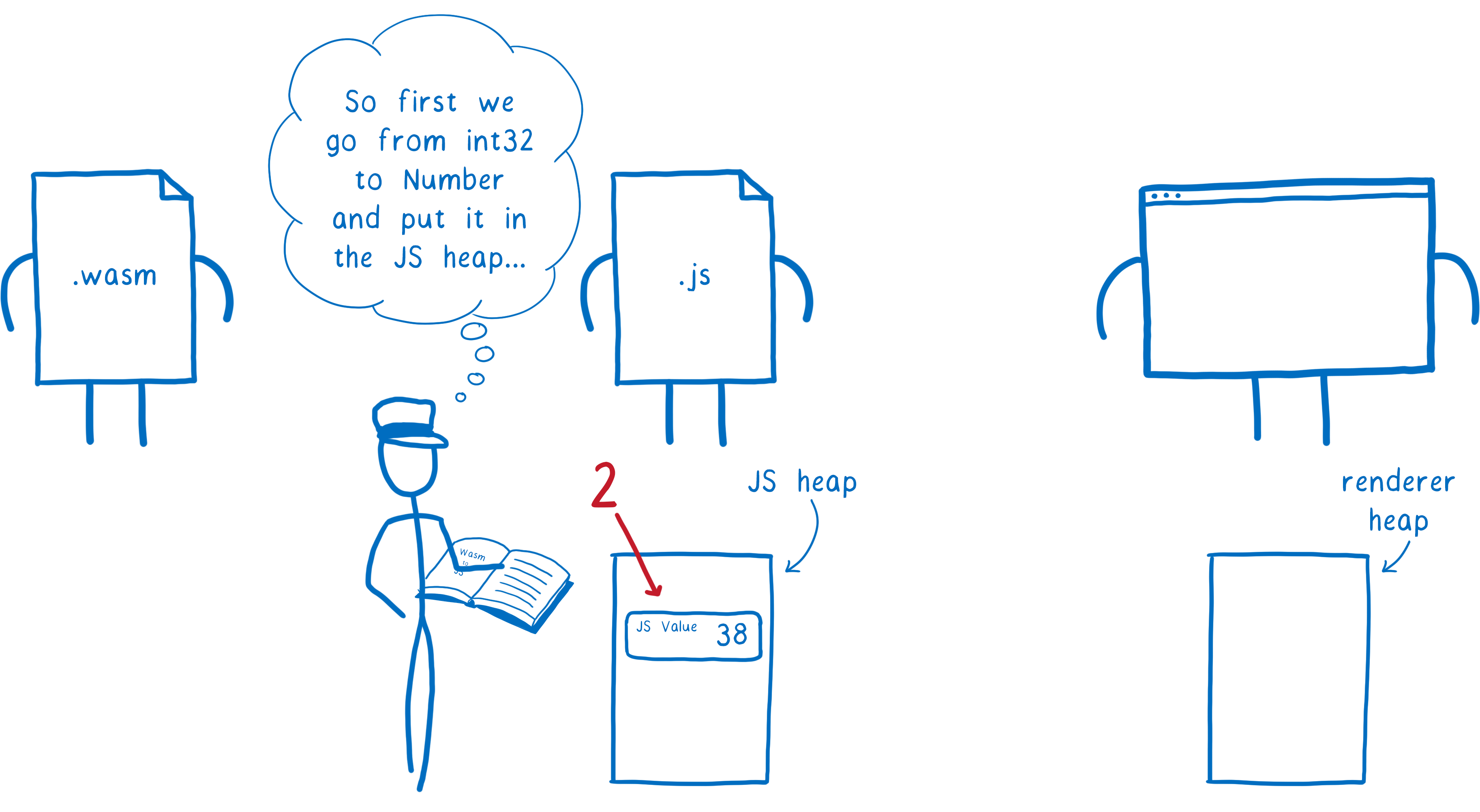
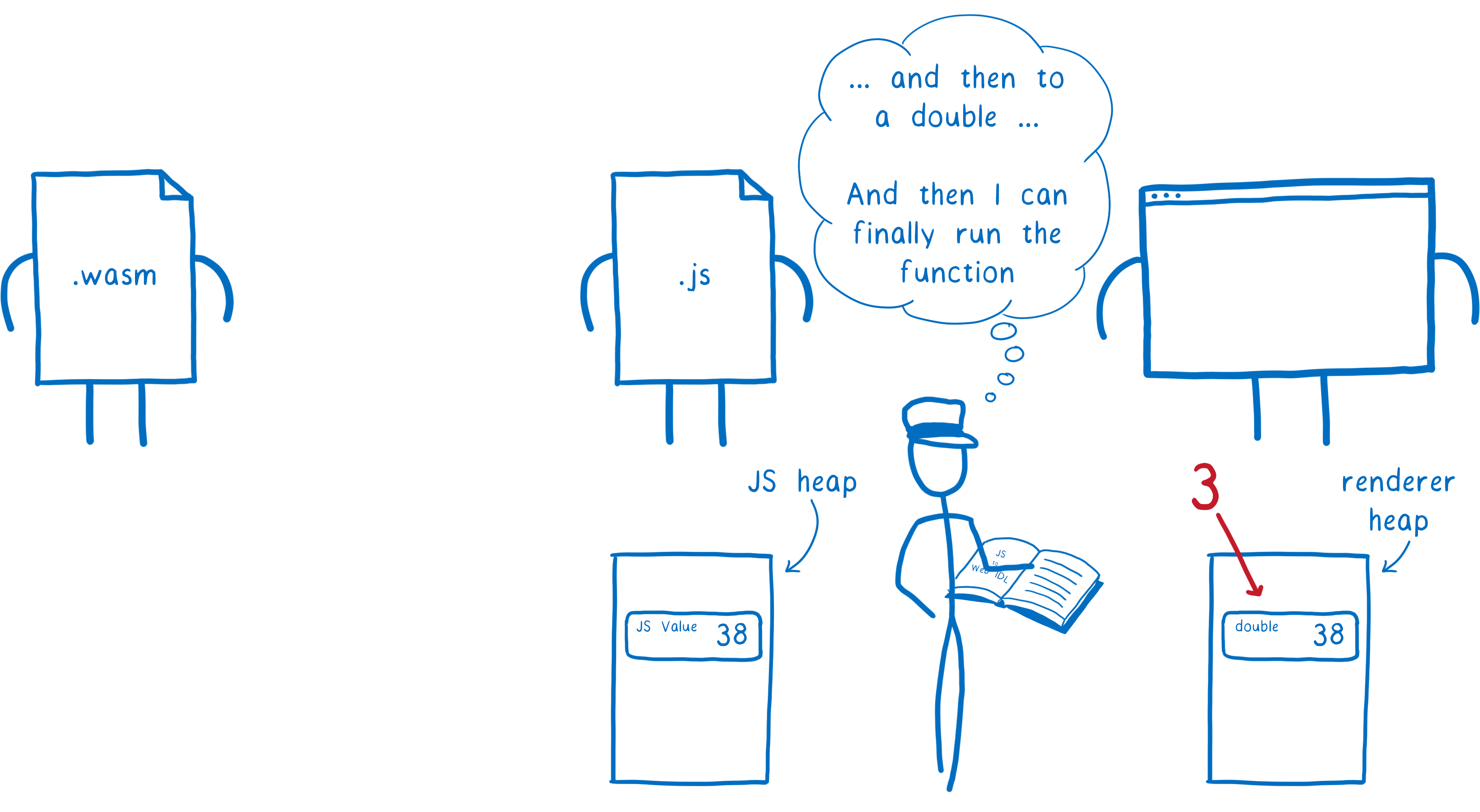
This takes more work than it needs to, and also uses up more memory.
There’s an obvious solution to this—create a mapping from WebAssembly directly to Web IDL. But that’s not as straightforward as it might seem.
For simple Web IDL types like boolean and unsigned long (which is a number), there are clear mappings from WebAssembly to Web IDL.
But for the most part, Web API parameters are more complex types. For example, an API might take a dictionary, which is basically an object with properties, or a sequence, which is like an array.
To have a straightforward mapping between WebAssembly types and Web IDL types, we’d need to add some higher-level types. And we are doing that—with the GC proposal. With that, WebAssembly modules will be able to create GC objects—things like structs and arrays—that could be mapped to complicated Web IDL types.
But if the only way to interoperate with Web APIs is through GC objects, that makes life harder for languages like C++ and Rust that wouldn’t use GC objects otherwise. Whenever the code interacts with a Web API, it would have to create a new GC object and copy values from its linear memory into that object.
That’s only slightly better than what we have today with JS glue code.
We don’t want JS glue code to have to build up GC objects—that’s a waste of time and space. And we don’t want the WebAssembly module to do that either, for the same reasons.
We want it to be just as easy for languages that use linear memory (like Rust and C++) to call Web APIs as it is for languages that use the engine’s built-in GC. So we need a way to create a mapping between objects in linear memory and Web IDL types, too.
There’s a problem here, though. Each of these languages represents things in linear memory in different ways. And we can’t just pick one language’s representation. That would make all the other languages less efficient.
But even though the exact layout in memory for these things is often different, there are some abstract concepts that they usually share in common.
For example, for strings the language often has a pointer to the start of the string in memory, and the length of the string. And even if the string has a more complicated internal representation, it usually needs to convert strings into this format when calling external APIs anyways.
This means we can reduce this string down to a type that WebAssembly understands… two i32s.
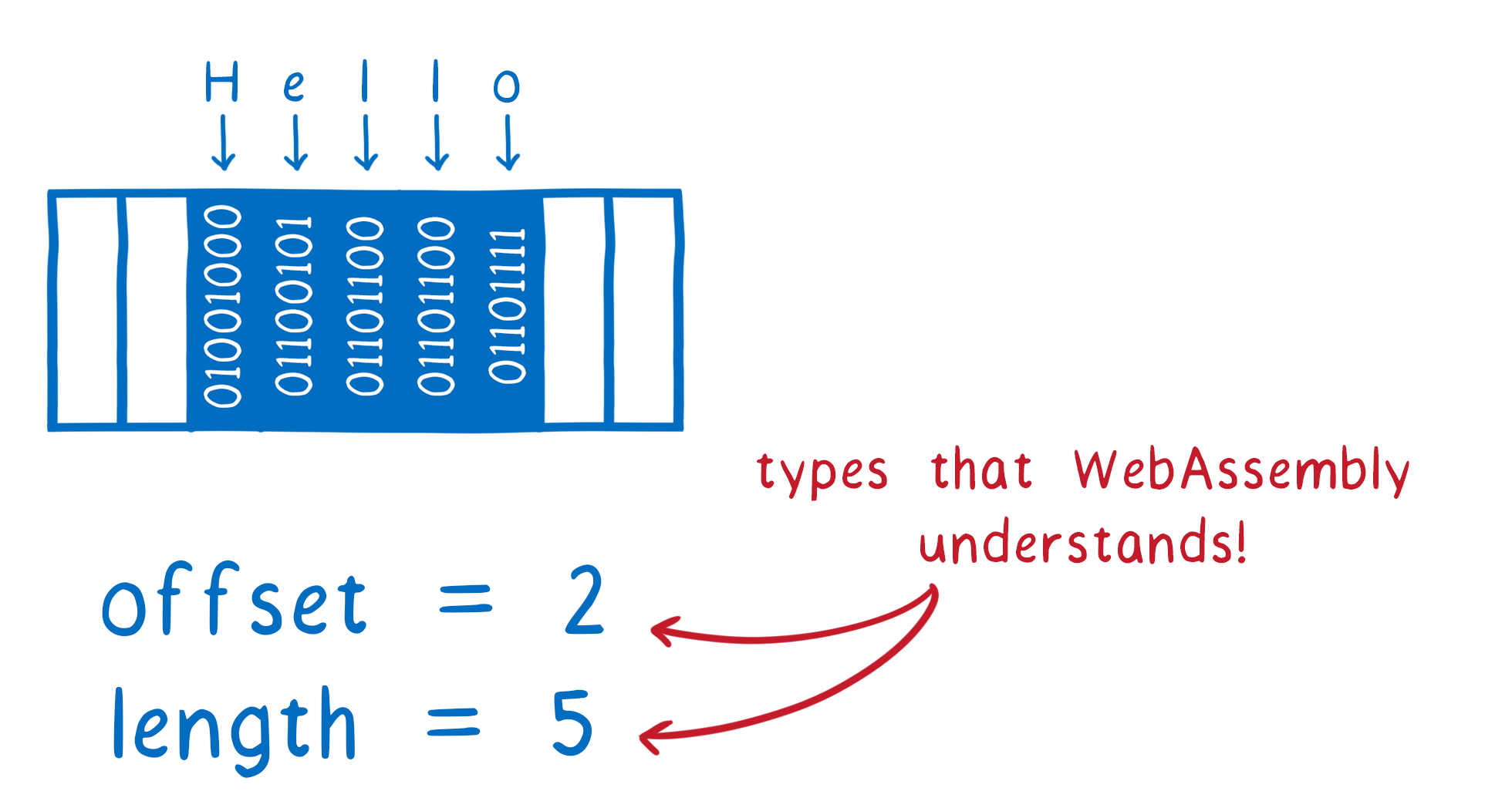
We could hardcode a mapping like this in the engine. So the engine would have yet another reference book, this time for WebAssembly to Web IDL mappings.
But there’s a problem here. WebAssembly is a type-checked language. To keep things secure, the engine has to check that the calling code passes in types that match what the callee asks for.
This is because there are ways for attackers to exploit type mismatches and make the engine do things it’s not supposed to do.
If you’re calling something that takes a string, but you try to pass the function an integer, the engine will yell at you. And it should yell at you.
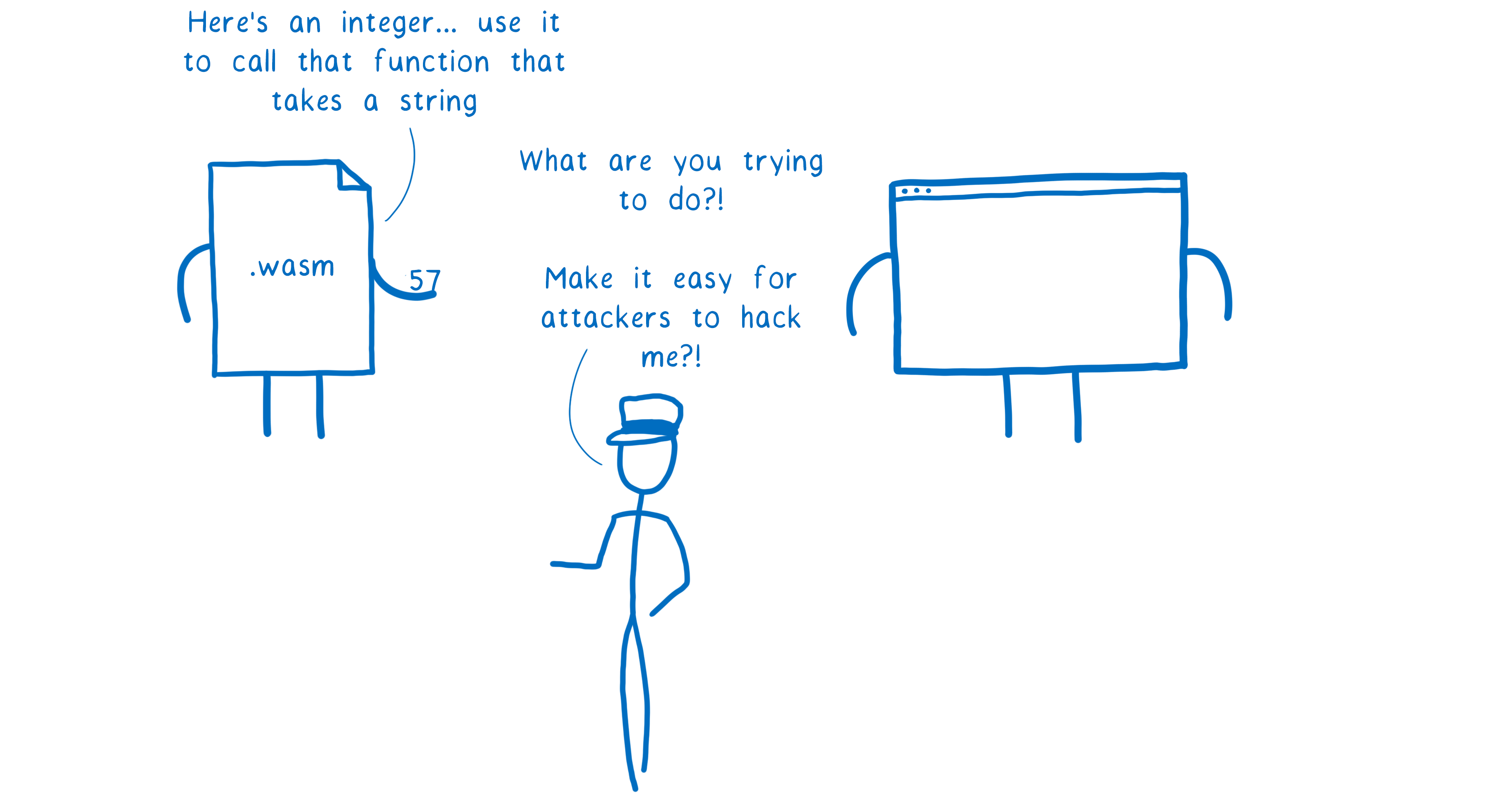
So we need a way for the module to explicitly tell the engine something like: “I know Document.createElement() takes a string. But when I call it, I’m going to pass you two integers. Use these to create a DOMString from data in my linear memory. Use the first integer as the starting address of the string and the second as the length.”
This is what the Web IDL proposal does. It gives a WebAssembly module a way to map between the types that it uses and Web IDL’s types.
These mappings aren’t hardcoded in the engine. Instead, a module comes with its own little booklet of mappings.
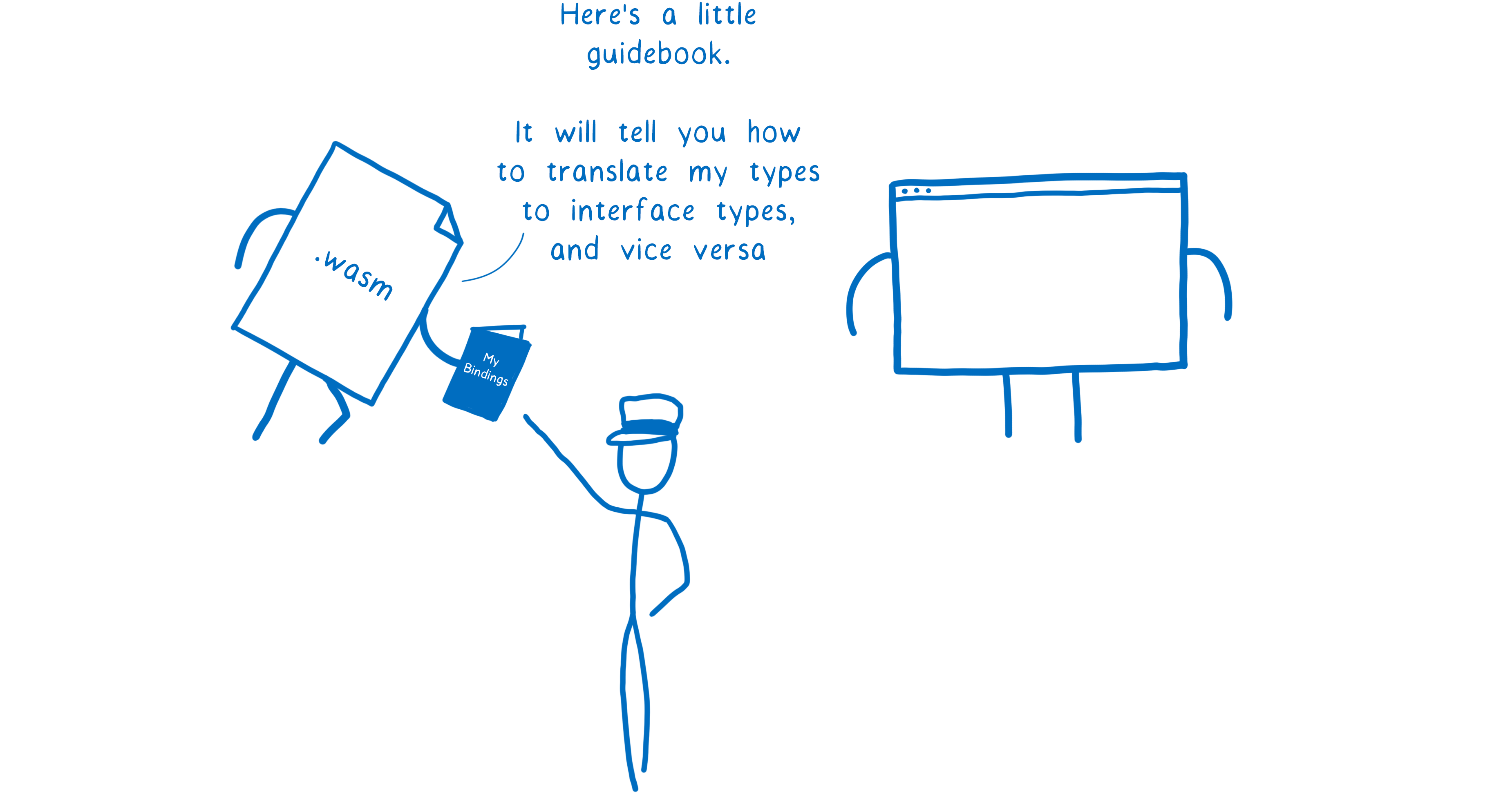
So this gives the engine a way to say “For this function, do the type checking as if these two integers are a string.”
The fact that this booklet comes with the module is useful for another reason, though.
Sometimes a module that would usually store its strings in linear memory will want to use an anyref or a GC type in a particular case… for example, if the module is just passing an object that it got from a JS function, like a DOM node, to a Web API.
So modules need to be able to choose on a function-by-function (or even even argument-by-argument) basis how different types should be handled. And since the mapping is provided by the module, it can be custom-tailored for that module.

How do you generate this booklet?
The compiler takes care of this information for you. It adds a custom section to the WebAssembly module. So for many language toolchains, the programmer doesn’t have to do much work.
For example, let’s look at how the Rust toolchain handles this for one of the simplest cases: passing a string into the alert function.
#[wasm_bindgen]
extern "C" {
fn alert(s: &str);
}
The programmer just has to tell the compiler to include this function in the booklet using the annotation #[wasm_bindgen]. By default, the compiler will treat this as a linear memory string and add the right mapping for us. If we needed it to be handled differently (for example, as an anyref) we’d have to tell the compiler using a second annotation.
So with that, we can cut out the JS in the middle. That makes passing values between WebAssembly and Web APIs faster. Plus, it means we don’t need to ship down as much JS.
And we didn’t have to make any compromises on what kinds of languages we support. It’s possible to have all different kinds of languages that compile to WebAssembly. And these languages can all map their types to Web IDL types—whether the language uses linear memory, or GC objects, or both.
Once we stepped back and looked at this solution, we realized it solved a much bigger problem.
WebAssembly talking to All The Things
Here’s where we get back to the promise in the intro.
Is there a feasible way for WebAssembly to talk to all of these different things, using all these different type systems?
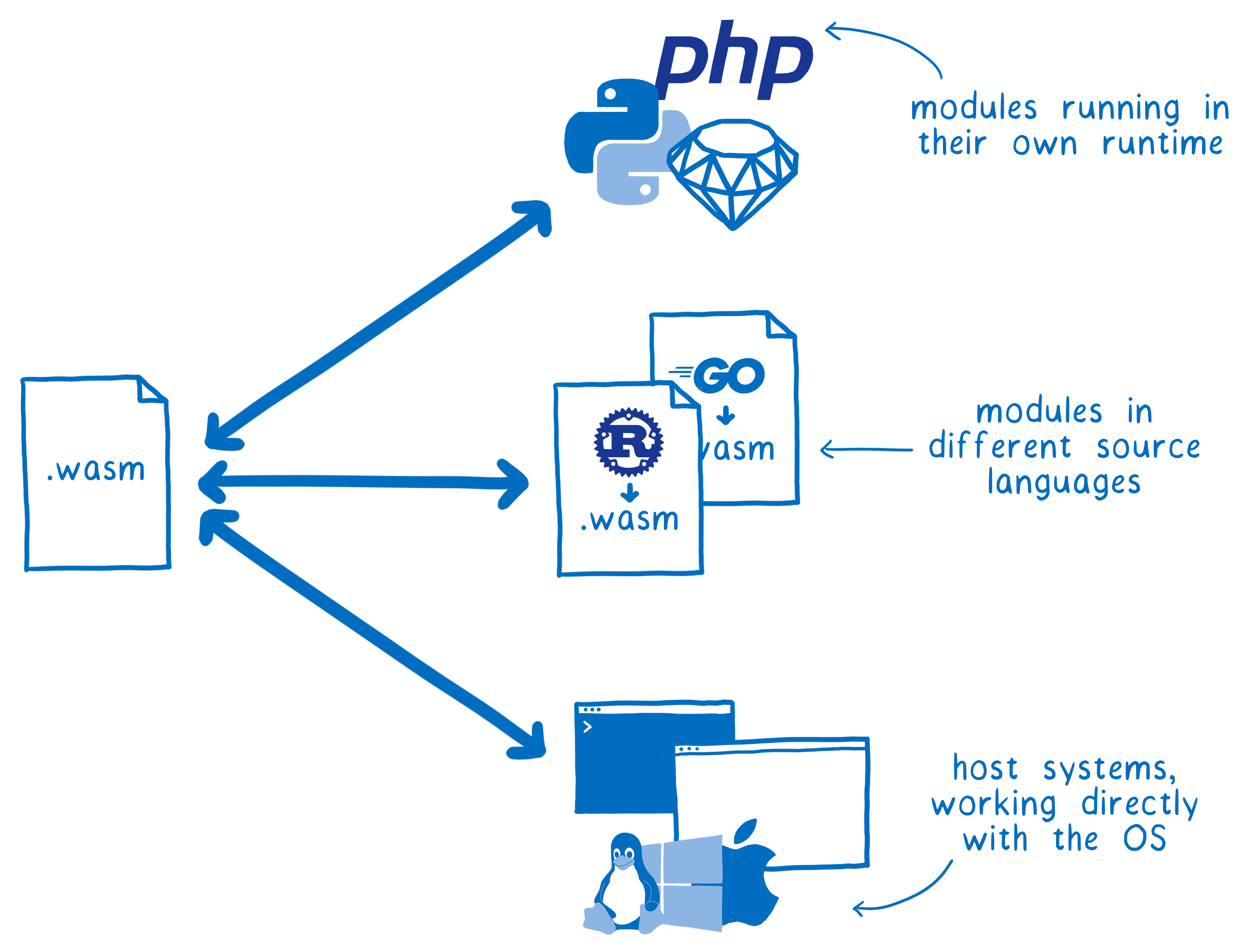
Let’s look at the options.
You could try to create mappings that are hardcoded in the engine, like WebAssembly to JS and JS to Web IDL are.
But to do that, for each language you’d have to create a specific mapping. And the engine would have to explicitly support each of these mappings, and update them as the language on either side changes. This creates a real mess.
This is kind of how early compilers were designed. There was a pipeline for each source language to each machine code language. I talked about this more in my first posts on WebAssembly.
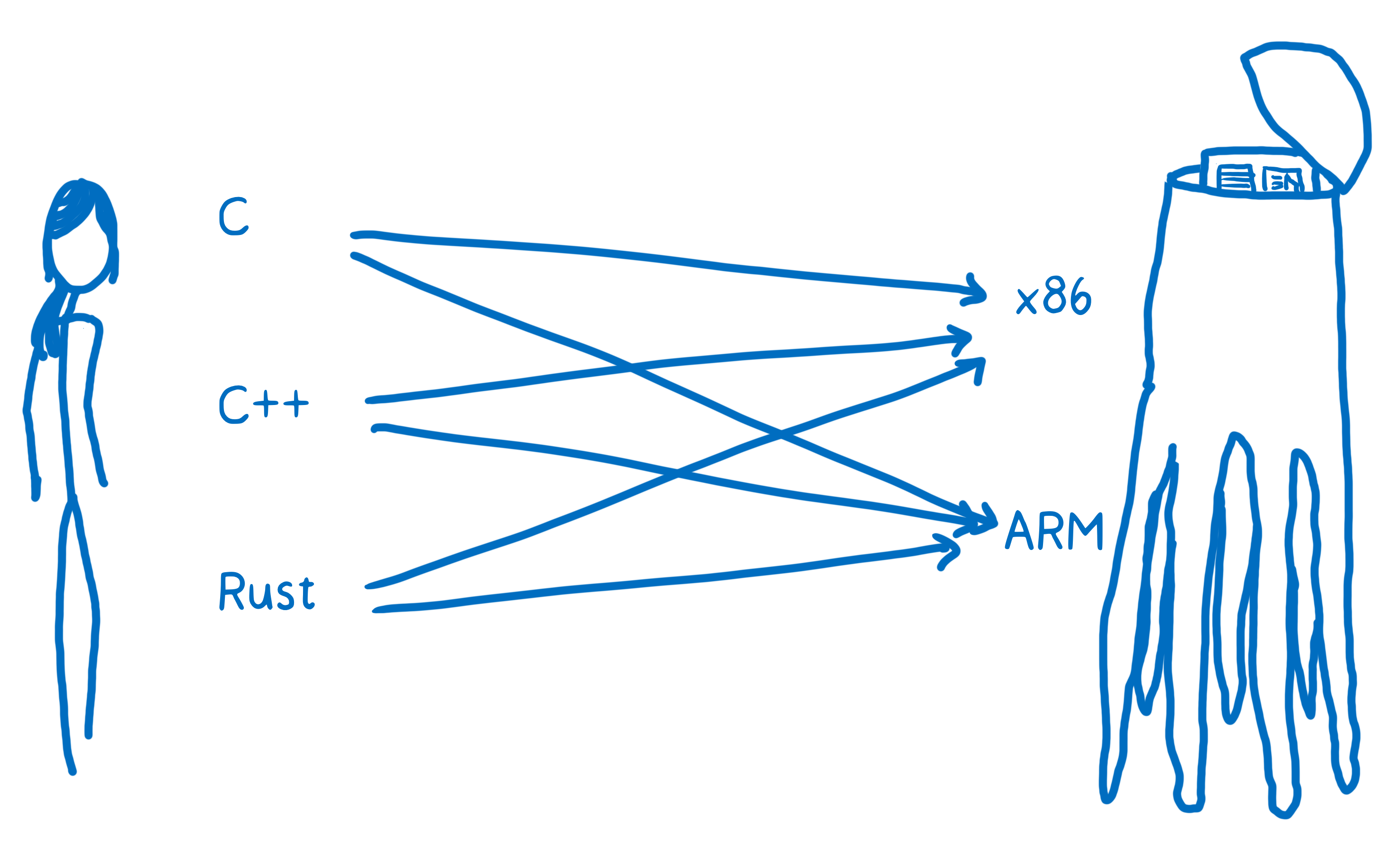
We don’t want something this complicated. We want it to be possible for all these different languages and platforms to talk to each other. But we need it to be scalable, too.
So we need a different way to do this… more like modern day compiler architectures. These have a split between front-end and back-end. The front-end goes from the source language to an abstract intermediate representation (IR). The back-end goes from that IR to the target machine code.
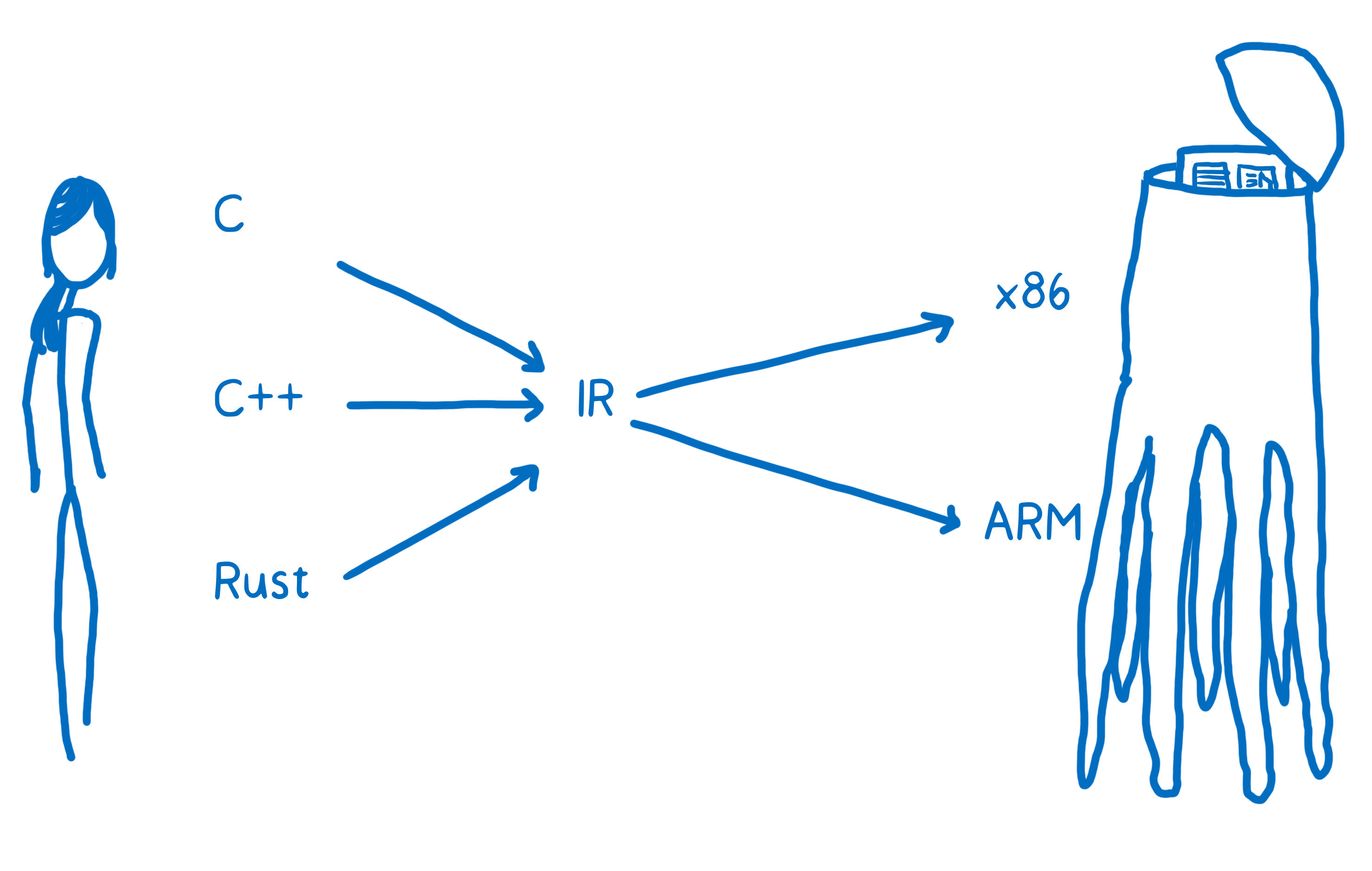
This is where the insight from Web IDL comes in. When you squint at it, Web IDL kind of looks like an IR.
Now, Web IDL is pretty specific to the Web. And there are lots of use cases for WebAssembly outside the web. So Web IDL itself isn’t a great IR to use.
But what if you just use Web IDL as inspiration and create a new set of abstract types?
This is how we got to the WebAssembly interface types proposal.
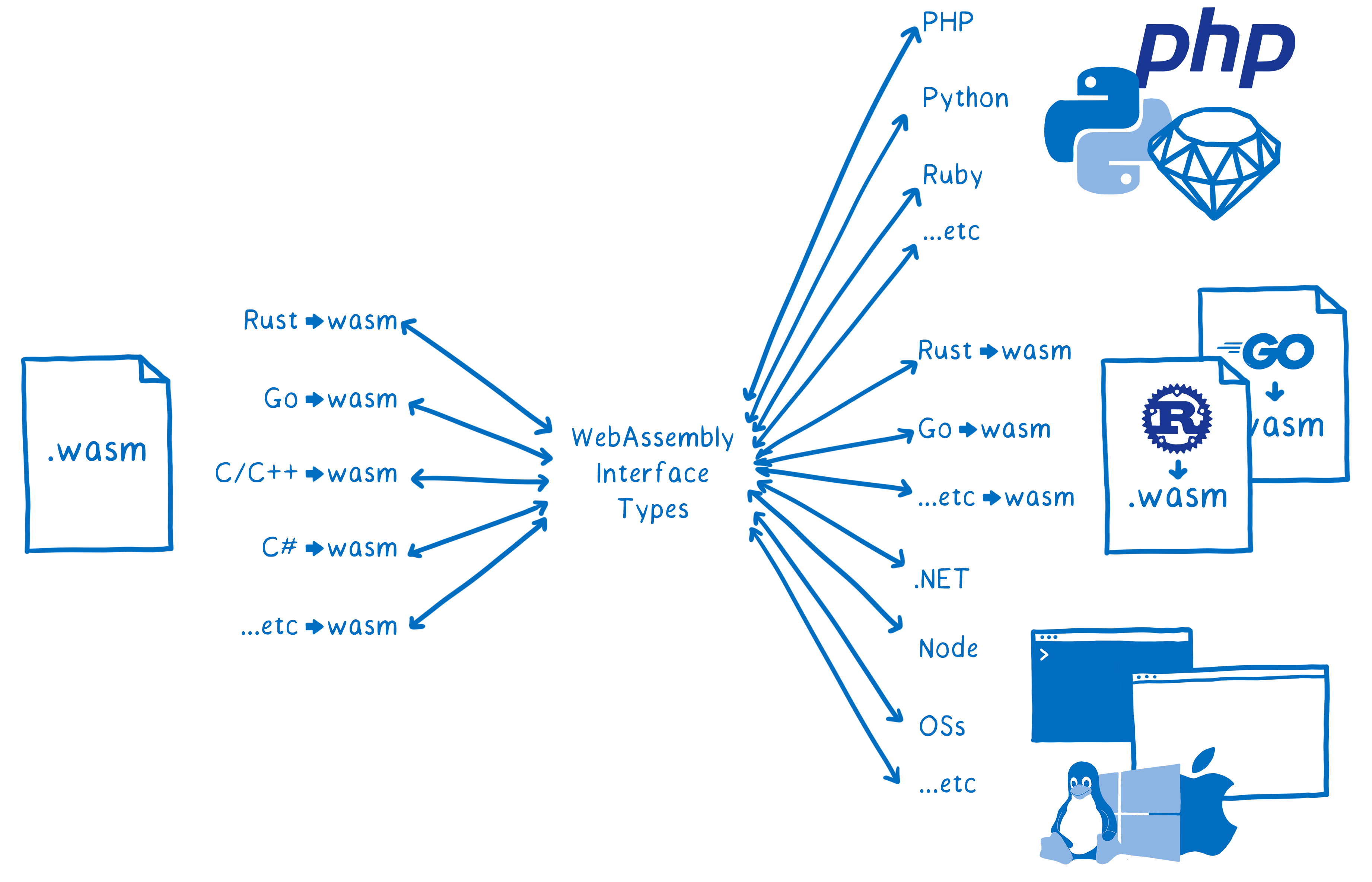
These types aren’t concrete types. They aren’t like the int32 or float64 types in WebAssembly today. There are no operations on them in WebAssembly.
For example, there won’t be any string concatenation operations added to WebAssembly. Instead, all operations are performed on the concrete types on either end.
There’s one key point that makes this possible: with interface types, the two sides aren’t trying to share a representation. Instead, the default is to copy values between one side and the other.
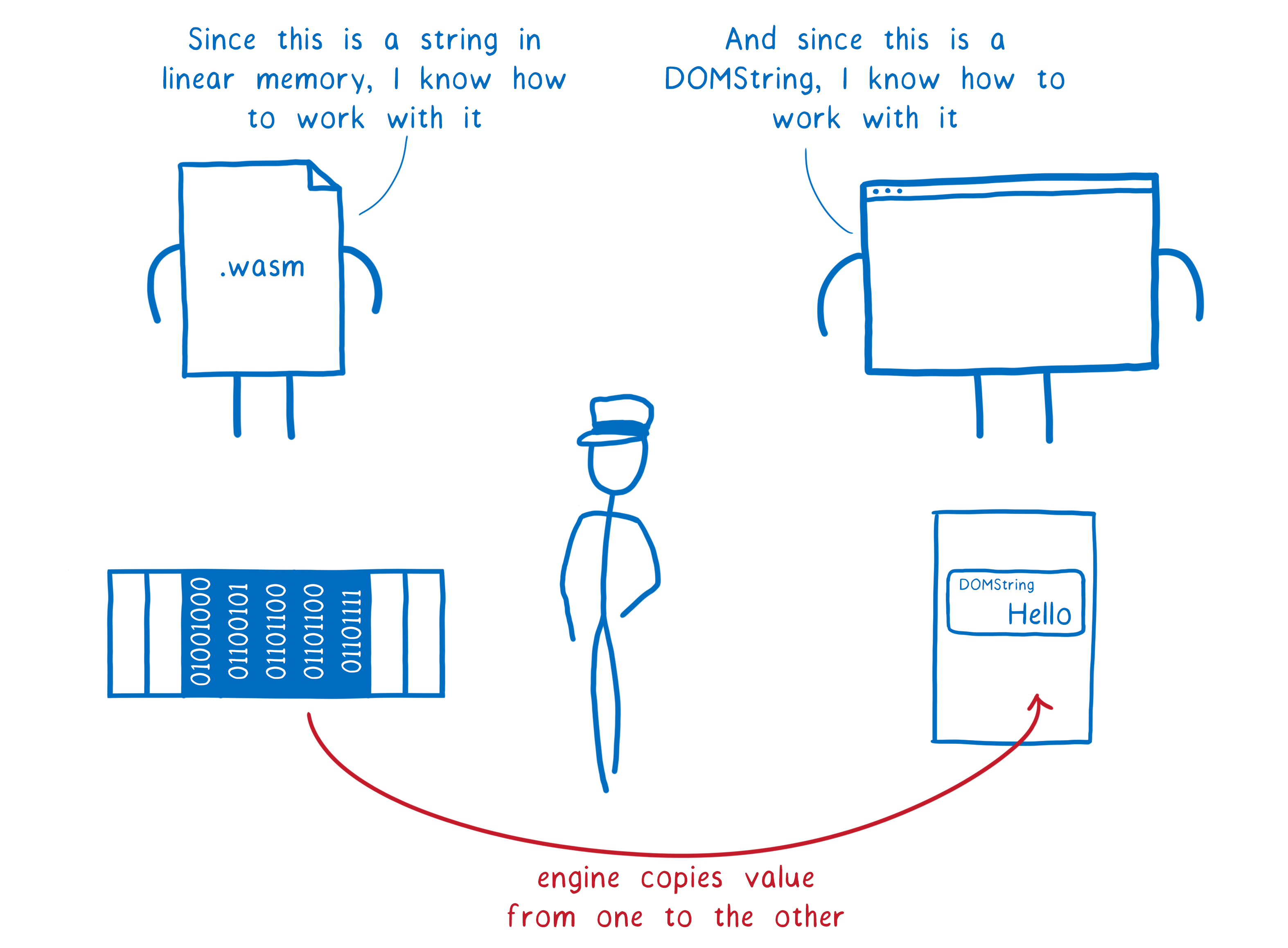
There is one case that would seem like an exception to this rule: the new reference values (like anyref) that I mentioned before. In this case, what is copied between the two sides is the pointer to the object. So both pointers point to the same thing. In theory, this could mean they need to share a representation.
In cases where the reference is just passing through the WebAssembly module (like the anyref example I gave above), the two sides still don’t need to share a representation. The module isn’t expected to understand that type anyway… just pass it along to other functions.
But there are times where the two sides will want to share a representation. For example, the GC proposal adds a way to create type definitions so that the two sides can share representations. In these cases, the choice of how much of the representation to share is up to the developers designing the APIs.
This makes it a lot easier for a single module to talk to many different languages.
In some cases, like the browser, the mapping from the interface types to the host’s concrete types will be baked into the engine.
So one set of mappings is baked in at compile time and the other is handed to the engine at load time.

But in other cases, like when two WebAssembly modules are talking to each other, they both send down their own little booklet. They each map their functions’ types to the abstract types.
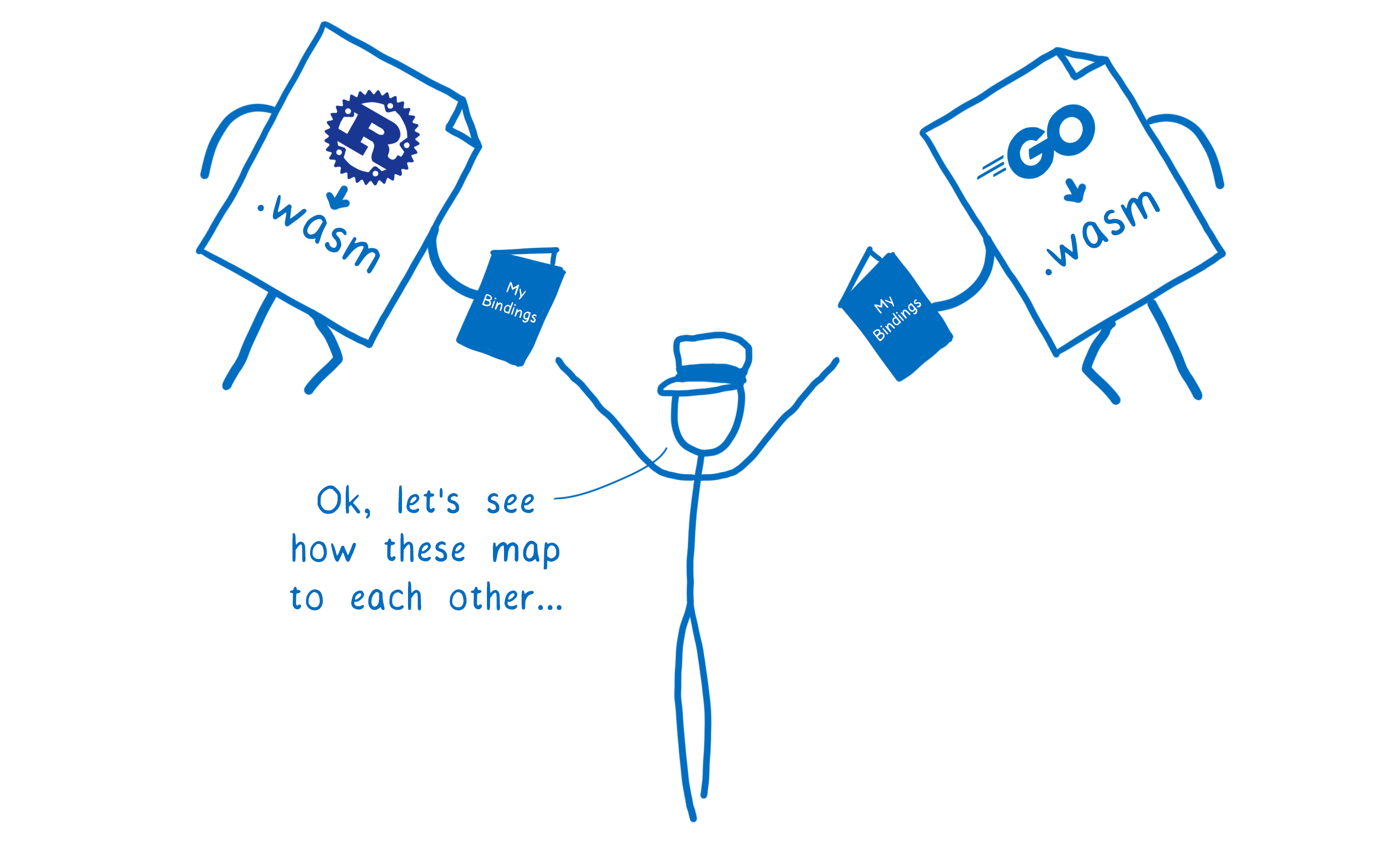
This isn’t the only thing you need to enable modules written in different source languages to talk to each other (and we’ll write more about this in the future) but it is a big step in that direction.
So now that you understand why, let’s look at how.
What do these interface types actually look like?
Before we look at the details, I should say again: this proposal is still under development. So the final proposal may look very different.
Also, this is all handled by the compiler. So even when the proposal is finalized, you’ll only need to know what annotations your toolchain expects you to put in your code (like in the wasm-bindgen example above). You won’t really need to know how this all works under the covers.
But the details of the proposal are pretty neat, so let’s dig into the current thinking.
The problem to solve
The problem we need to solve is translating values between different types when a module is talking to another module (or directly to a host, like the browser).
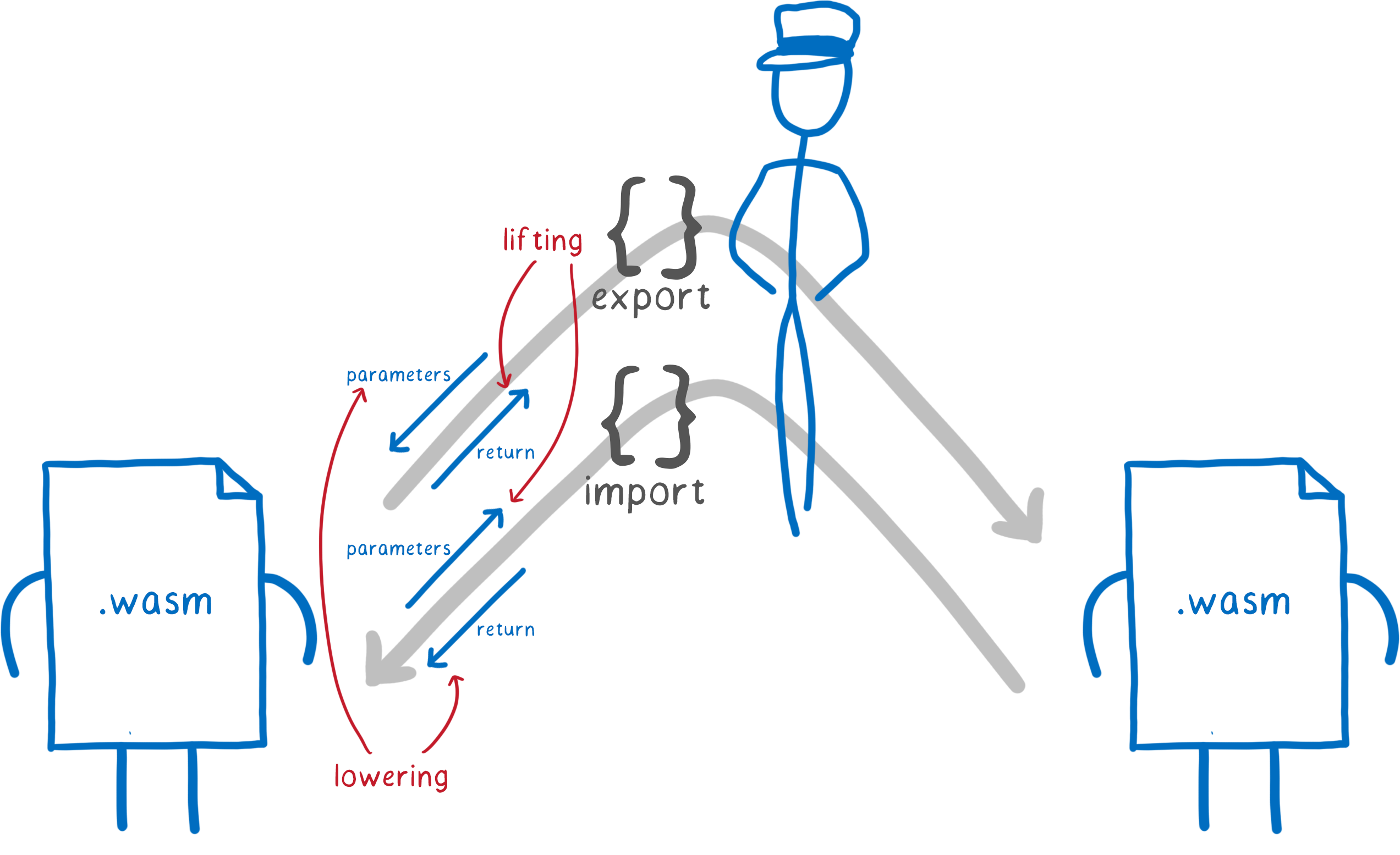
There are four places where we may need to do a translation:
For exported functions
- accepting parameters from the caller
- returning values to the caller
For imported functions
- passing parameters to the function
- accepting return values from the function
And you can think about each of these as going in one of two directions:
- Lifting, for values leaving the module. These go from a concrete type to an interface type.
- Lowering, for values coming into the module. These go from an interface type to a concrete type.
Telling the engine how to transform between concrete types and interface types
So we need a way to tell the engine which transformations to apply to a function’s parameters and return values. How do we do this?
By defining an interface adapter.
For example, let’s say we have a Rust module compiled to WebAssembly. It exports a greeting_ function that can be called without any parameters and returns a greeting.
Here’s what it would look like (in WebAssembly text format) today.

So right now, this function returns two integers.
But we want it to return the string interface type. So we add something called an interface adapter.
If an engine understands interface types, then when it sees this interface adapter, it will wrap the original module with this interface.

It won’t export the greeting_ function anymore… just the greeting function that wraps the original. This new greeting function returns a string, not two numbers.
This provides backwards compatibility because engines that don’t understand interface types will just export the original greeting_ function (the one that returns two integers).
How does the interface adapter tell the engine to turn the two integers into a string?
It uses a sequence of adapter instructions.

The adapter instructions above are two from a small set of new instructions that the proposal specifies.
Here’s what the instructions above do:
- Use the
call-exportadapter instruction to call the originalgreeting_function. This is the one that the original module exported, which returned two numbers. These numbers get put on the stack. - Use the
memory-to-stringadapter instruction to convert the numbers into the sequence of bytes that make up the string. We have to specifiy “mem” here because a WebAssembly module could one day have multiple memories. This tells the engine which memory to look in. Then the engine takes the two integers from the top of the stack (which are the pointer and the length) and uses those to figure out which bytes to use.
This might look like a full-fledged programming language. But there is no control flow here—you don’t have loops or branches. So it’s still declarative even though we’re giving the engine instructions.
What would it look like if our function also took a string as a parameter (for example, the name of the person to greet)?
Very similar. We just change the interface of the adapter function to add the parameter. Then we add two new adapter instructions.

Here’s what these new instructions do:
- Use the
arg.getinstruction to take a reference to the string object and put it on the stack. - Use the
string-to-memoryinstruction to take the bytes from that object and put them in linear memory. Once again, we have to tell it which memory to put the bytes into. We also have to tell it how to allocate the bytes. We do this by giving it an allocator function (which would be an export provided by the original module).
One nice thing about using instructions like this: we can extend them in the future… just as we can extend the instructions in WebAssembly core. We think the instructions we’re defining are a good set, but we aren’t committing to these being the only instruct for all time.
If you’re interested in understanding more about how this all works, the explainer goes into much more detail.
Sending these instructions to the engine
Now how do we send this to the engine?
These annotations gets added to the binary file in a custom section.
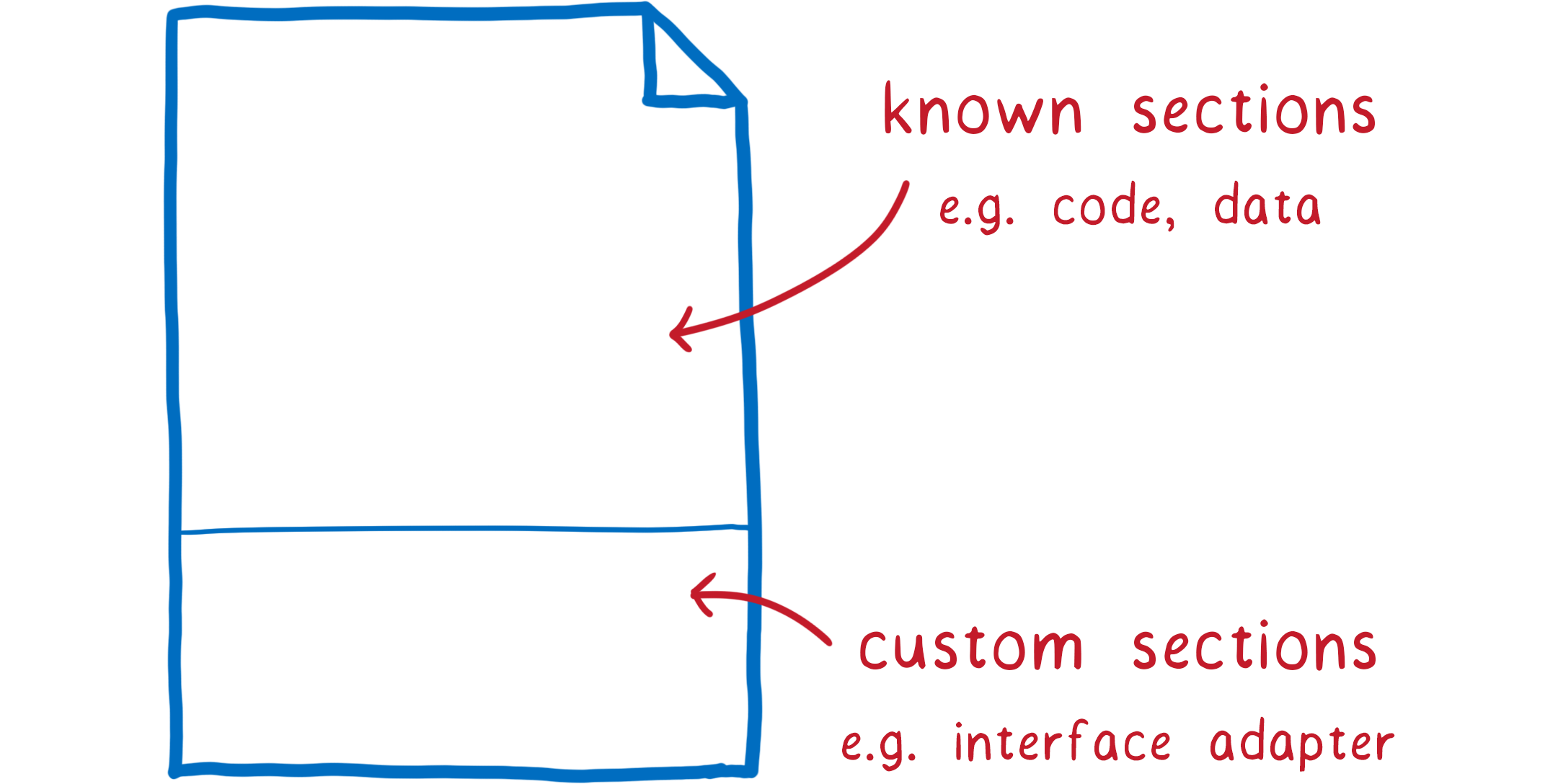
If an engine knows about interface types, it can use the custom section. If not, the engine can just ignore it, and you can use a polyfill which will read the custom section and create glue code.
How is this different than CORBA, Protocol Buffers, etc?
There are other standards that seem like they solve the same problem—for example CORBA, Protocol Buffers, and Cap’n Proto.
How are those different? They are solving a much harder problem.
They are all designed so that you can interact with a system that you don’t share memory with—either because it’s running in a different process or because it’s on a totally different machine across the network.
This means that you have to be able to send the thing in the middle—the “intermediate representation” of the objects—across that boundary.
So these standards need to define a serialization format that can efficiently go across the boundary. That’s a big part of what they are standardizing.
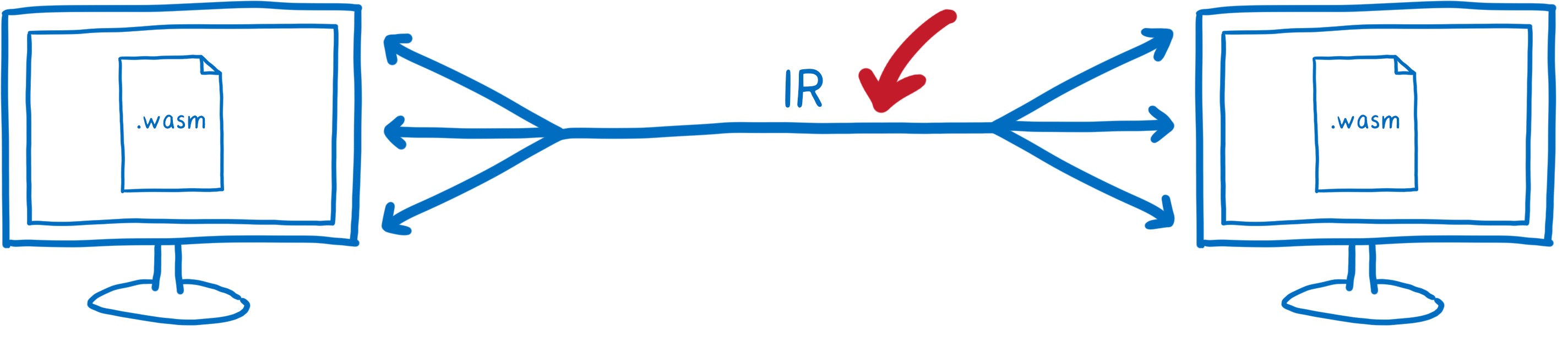
Even though this looks like a similar problem, it’s actually almost the exact inverse.
With interface types, this “IR” never needs to leave the engine. It’s not even visible to the modules themselves.
The modules only see the what the engine spits out for them at the end of the process—what’s been copied to their linear memory or given to them as a reference. So we don’t have to tell the engine what layout to give these types—that doesn’t need to be specified.
What is specified is the way that you talk to the engine. It’s the declarative language for this booklet that you’re sending to the engine.
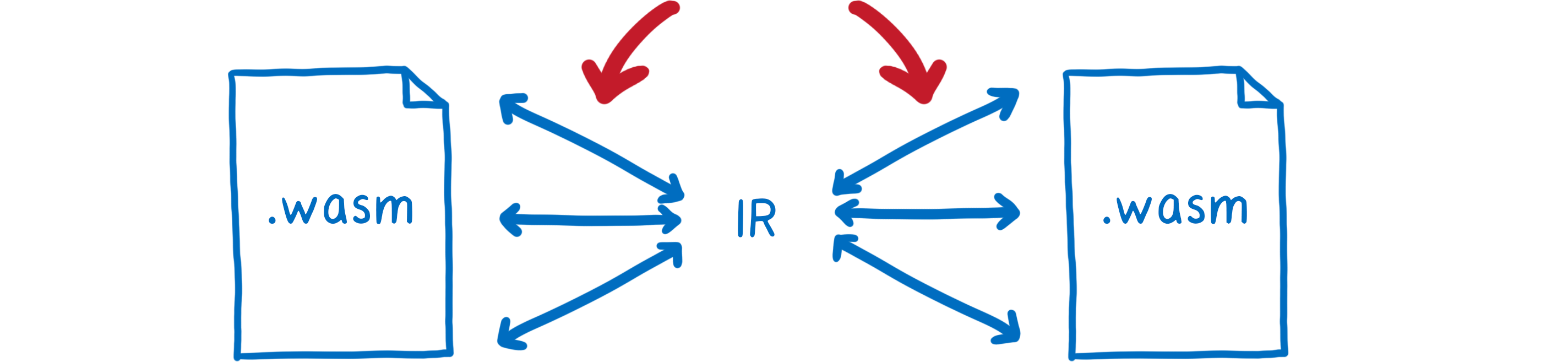
This has a nice side effect: because this is all declarative, the engine can see when a translation is unnecessary—like when the two modules on either side are using the same type—and skip the translation work altogether.

How can you play with this today?
As I mentioned above, this is an early stage proposal. That means things will be changing rapidly, and you don’t want to depend on this in production.
But if you want to start playing with it, we’ve implemented this across the toolchain, from production to consumption:
- the Rust toolchain
- wasm-bindgen
- the Wasmtime WebAssembly runtime
And since we maintain all these tools, and since we’re working on the standard itself, we can keep up with the standard as it develops.
Even though all these parts will continue changing, we’re making sure to synchronize our changes to them. So as long as you use up-to-date versions of all of these, things shouldn’t break too much.
So here are the many ways you can play with this today. For the most up-to-date version, check out this repo of demos.
Thank you
- Thank you to the team who brought all of the pieces together across all of these languages and runtimes: Alex Crichton, Yury Delendik, Nick Fitzgerald, Dan Gohman, and Till Schneidereit
- Thank you to the proposal co-champions and their colleagues for their work on the proposal: Luke Wagner, Francis McCabe, Jacob Gravelle, Alex Crichton, and Nick Fitzgerald
- Thank you to my fantastic collaborators, Luke Wagner and Till Schneidereit, for their invaluable input and feedback on this article
About Lin Clark
Lin works in Advanced Development at Mozilla, with a focus on Rust and WebAssembly.
One comment