
Fluent is a family of localization specifications, implementations and good practices developed by Mozilla. It is currently used in Firefox. With Fluent, translators can create expressive translations that sound great in their language. Today we’re announcing version 1.0 of the Fluent file format specification. We’re inviting translation tool authors to try it out and provide feedback.
The Problem Fluent Solves
With almost 100 supported languages, Firefox faces many localization challenges. Using traditional localization solutions, these are difficult to overcome. Software localization has been dominated by an outdated paradigm: translations that map one-to-one to the source language. The grammar of the source language, which at Mozilla is English, imposes limits on the expressiveness of the translation.
Consider the following message which appears in Firefox when the user tries to close a window with more than one tab.
tabs-close-warning-multiple =
You are about to close {$count} tabs.
Are you sure you want to continue?
The message is only displayed when the tab count is 2 or more. In English, the word tab will always appear as plural tabs. An English-speaking developer may be content with this message. It sounds great for all possible values of $count.
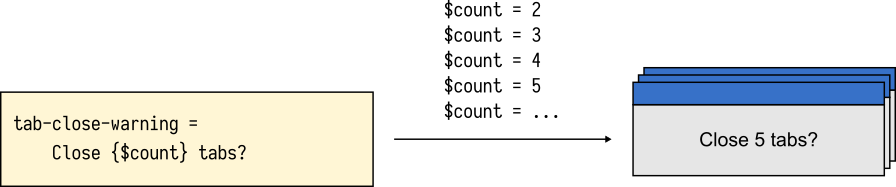
$count.Many translators, however, will quickly point out that the word tab will take different forms depending on the exact value of the $count variable.
In traditional localization solutions, the onus of fixing this message is on developers. They need to account for the fact that other languages distinguish between more than one plural form, even if English doesn’t. As the number of languages supported in the application grows, this problem scales up quickly—and not well.
- In some languages, nouns have genders which require different forms of adjectives and past participles. In French, connecté, connectée, connectés and connectées all mean connected.
- Style guides may require that different terms be used depending on the platform the software runs on. In English Firefox, we use Settings on Windows and Preferences on other systems, to match the wording of the user’s operating system. In Japanese, the difference is starker: some computer-related terms are spelled with a different writing system depending on the user’s OS.
- The context and the target audience of the application may require adjustments to the copy. In English, software used in accounting may format numbers differently than a social media website. Yet in other languages such a distinction may not be necessary.
There are many grammatical and stylistic variations that don’t map one-to-one between languages. Supporting all of them using traditional localization solutions isn’t straightforward. Some language features require trade-offs in order to support them, or aren’t possible at all.
Asymmetric Localization
Fluent turns the localization landscape on its head. Rather than require developers to predict all possible permutations of complexity in all supported languages, Fluent keeps the source language as simple as it can be.
We make it possible to cater to the grammar and style of other languages, independently of the source language. All of this happens in isolation; the fact that one language benefits from more advanced logic doesn’t require any other localization to apply it. Each localization is in control of how complex the translation becomes.
Consider the Czech translation of the “tab close” message discussed above. The word panel (tab) must take one of two plural forms: panely for counts of 2, 3, and 4, and panelů for all other numbers.
tabs-close-warning-multiple = {$count ->
[few] Chystáte se zavřít {$count} panely. Opravdu chcete pokračovat?
*[other] Chystáte se zavřít {$count} panelů. Opravdu chcete pokračovat?
}
Fluent empowers translators to create grammatically correct translations and leverage the expressive power of their language. With Fluent, the Czech translation can now benefit from correct plural forms for all possible values of the $count variable.
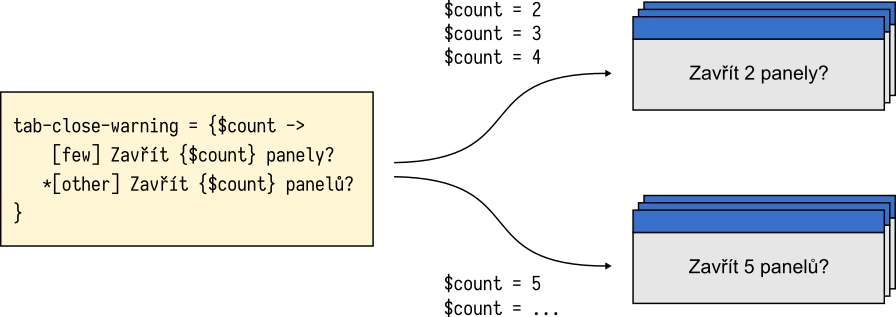
$count values of 2, 3, and 4 require a special plural form of the noun.At the same time, no changes are required to the source code nor the source copy. In fact, the logic added by the Czech translator to the Czech translation doesn’t affect any other language. The same message in French is a simple sentence, similar to the English one:
tabs-close-warning-multiple =
Vous êtes sur le point de fermer {$count} onglets.
Voulez-vous vraiment continuer ?
The concept of asymmetric localization is the key innovation of Fluent, built upon 20 years of Mozilla’s history of successfully shipping localized software. Many key ideas in Fluent have also been inspired by XLIFF and ICU’s MessageFormat.
At first glance, Fluent looks similar to other localization solutions that allow translations to use plurals and grammatical genders. What sets Fluent apart is the holistic approach to localization. Fluent takes these ideas further by defining the syntax for the entire text file in which multiple translations can be stored, and by allowing messages to reference other messages.
Terms and References
A Fluent file may consist of many messages, each translated into the translator’s language. Messages can refer to other messages in the same file, or even to messages from other files. In the runtime, Fluent combines files into bundles, and references are resolved in the scope of the current bundle.
Referencing messages is a powerful tool for ensuring consistency. Once defined, a translation can be reused in other translations. Fluent even has a special kind of message, called a term, which is best suited for reuse. Term identifiers always start with a dash.
-sync-brand-name = Firefox Account
Once defined, the -sync-brand-name term can be referenced from other messages, and it will always resolve to the same value. Terms help enforce style guidelines; they can also be swapped in and out to modify the branding in unofficial builds and on beta release channels.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: The best way to bring
your data always with you
sync-signedout-account-title =
Connect with your {-sync-brand-name}
Using terms verbatim in the middle of a sentence may cause trouble for inflected languages or for languages with different capitalization rules than English. Terms can define multiple facets of their value, suitable for use in different contexts. Consider the following definition of the -sync-brand-name term in Italian.
-sync-brand-name = {$capitalization ->
*[uppercase] Account Firefox
[lowercase] account Firefox
}
Thanks to the asymmetric nature of Fluent, the Italian translator is free to define two facets of the brand name. The default one (uppercase) is suitable for standalone appearances as well as for use at the beginning of sentences. The lowercase version can be explicitly requested by passing the capitalization parameter, when the brand name is used inside a larger sentence.
sync-dialog-title = {-sync-brand-name}
sync-headline-title =
{-sync-brand-name}: il modo migliore
per avere i tuoi dati sempre con te
# Explicitly request the lowercase variant of the brand name.
sync-signedout-account-title =
Connetti il tuo {-sync-brand-name(capitalization: "lowercase")}
Defining multiple term variants is a versatile technique which allows the localization to cater to the grammatical needs of many languages. In the following example, the Polish translation can use declensions to construct a grammatically correct sentence in the sync-signedout-account-title message.
-sync-brand-name = {$case ->
*[nominative] Konto Firefox
[genitive] Konta Firefox
[accusative] Kontem Firefox
}
sync-signedout-account-title =
Zaloguj do {-sync-brand-name(case: "genitive")}
Fluent makes it possible to express linguistic complexities when necessary. At the same time, simple translations remain simple. Fluent doesn’t impose complexity unless it’s required to create a correct translation.
sync-signedout-caption = Take Your Web With You
sync-signedout-caption = Il tuo Web, sempre con te
sync-signedout-caption = Zabierz swoją sieć ze sobą
sync-signedout-caption = So haben Sie das Web überall dabei.
Fluent Syntax
Today, we’re announcing the first stable release of the Fluent Syntax. It’s a formal specification of the file format for storing translations, accompanied by beta releases of parser implementations in JavaScript, Python, and Rust.
You’ve already seen a taste of Fluent Syntax in the examples above. It has been designed with non-technical people in mind, and to make the task of reviewing and editing translations easy and error-proof. Error recovery is a strong focus: it’s impossible for a single broken translation to break the entire file, or even the translations adjacent to it. Comments may be used to communicate contextual information about the purpose of a message or a group of messages. Translations can span multiple lines, which helps when working with longer text or markup.
Fluent files can be opened and edited in any text editor, lowering the barrier to entry for developers and localizers alike. The file format is also well supported by Pontoon, Mozilla’s open-source translation management system.
You can learn more about the syntax by reading the Fluent Syntax Guide. The formal definition can be found in the Fluent Syntax specification. And if you just want to quickly see it in action, try the Fluent Playground—an online editor with shareable Fluent snippets.
Request for Feedback
Firefox has been the main driver behind the development of Fluent so far. Today, there are over 3000 Fluent messages in Firefox. The migration from legacy localization formats started early last year and is now in full swing. Fluent has proven to be a stable and flexible solution for building complex interfaces, such as the UI of Firefox Preferences. It is also used in a number of Mozilla websites, such as Firefox Send and Common Voice.
We think Fluent is a great choice for applications that value simplicity and a lean runtime, and at the same time require that elements of the interface depend on multiple variables. In particular, Fluent can help create natural-sounding translations in size-constrained UIs of mobile apps; in information-rich layouts of social media platforms; and in games, to communicate gameplay statistics and mechanics to the player.
We’d love to hear from projects and localization vendors outside of Mozilla. Because we’re developing Fluent with a future standard in mind, we invite you to try it out and let us know if it addresses your challenges. With your help, we can iterate and improve Fluent to address the needs of many platforms, use cases, and industries.
We’re open to your constructive feedback. Learn more about Fluent on the project’s website and please get in touch on Fluent’s Discourse.
About Staś Małolepszy
As a Localization Engineer at Mozilla, I create solutions which help make Firefox available globally and relevant locally.
5 comments