
Building a browser is hard; building a good browser inevitably requires gathering a lot of data to make sure that things that work in the lab work in the field. But as soon as you gather data, you have to make sure you protect user privacy. We’re always looking at ways to improve the security of our data collection, and lately we’ve been experimenting with a really cool technique called Prio.
Currently, all the major browsers do more or less the same thing for data reporting: the browser collects a bunch of statistics and sends it back to the browser maker for analysis; in Firefox, we call this system Telemetry. The challenge with building a Telemetry system is that data is sensitive. In order to ensure that we are safeguarding our users’ privacy, Mozilla has built a set of transparent data practices which determine what we can collect and under what conditions. For particularly sensitive categories of data, we ask users to opt-in to the collection and ensure that the data is handled securely.
We understand that this requires users to trust Mozilla — that we won’t misuse their data, that the data won’t be exposed in a breach, and that Mozilla won’t be compelled to provide access to the data by another party. In the future, we would prefer users to not have to just trust Mozilla, especially when we’re collecting data that is sufficiently sensitive to require an opt-in. This is why we’re exploring new ways to preserve your data privacy and security without compromising access to the information we need to build the best products and services.
Obviously, not collecting any data at all is best for privacy, but it also blinds us to real issues in the field, which makes it hard for us to build features — including privacy features — which we know our users want. This is a common problem and there has been quite a bit of work on what’s called “privacy-preserving data collection”, including systems developed by Google (RAPPOR, PROCHLO) and Apple. Each of these systems has advantages and disadvantages that are beyond the scope of this post, but suffice to say that this is an area of very active work.
In recent months, we’ve been experimenting with one such system: Prio, developed by Professor Dan Boneh and PhD student Henry Corrigan-Gibbs of Stanford University’s Computer Science department. The basic insight behind Prio is that for most purposes we don’t need to collect individual data, but rather only aggregates. Prio, which is in the public domain, lets Mozilla collect aggregate data without collecting anyone’s individual data. It does this by having the browser break the data up into two “shares”, each of which is sent to a different server. Individually the shares don’t tell you anything about the data being reported, but together they do. Each server collects the shares from all the clients and adds them up. If the servers then take their sum values and put them together, the result is the sum of all the users’ values. As long as one server is honest, then there’s no way to recover the individual values.
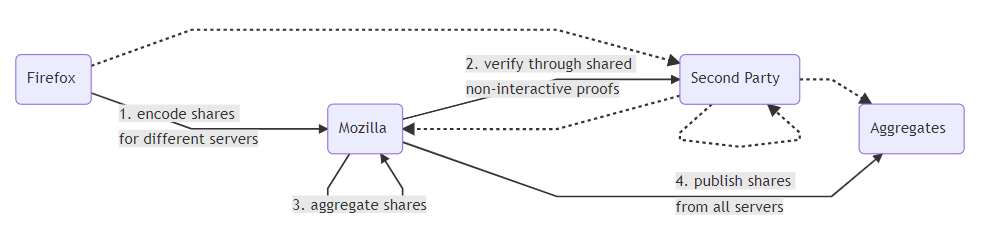
We’ve been working with the Stanford team to test Prio in Firefox. In the first stage of the experiment we want to make sure that it works efficiently at scale and produces the expected results. This is something that should just work, but as we mentioned before, building systems is a lot harder in practice than theory. In order to test our integration, we’re doing a simple deployment where we take nonsensitive data that we already collect using Telemetry and collect it via Prio as well. This lets us prove out the technology without interfering with our existing, careful handling of sensitive data. This part is in Nightly now and reporting back already. In order to process the data, we’ve integrated support for Prio into our Spark-based telemetry analysis system, so it automatically talks to the Prio servers to compute the aggregates.
Our initial results are promising: we’ve been running Prio in Nightly for 6 weeks, gathered over 3 million data values, and after fixing a small glitch where we were getting bogus results, our Prio results match our Telemetry results perfectly. Processing time and bandwidth also look good. Over the next few months we’ll be doing further testing to verify that Prio continues to produce the right answers and works well with our existing data pipeline.
Most importantly, in a production deployment we need to make sure that user privacy doesn’t depend on trusting a single party. This means distributing trust by selecting a third party (or parties) that users can have confidence in. This third party would never see any individual user data, but they would be responsible for keeping us honest by ensuring that we never see any individual user data either. To that end, it’s important to select a third party that users can trust; we’ll have more to say about this as we firm up our plans.
We don’t yet have concrete plans for what data we’ll protect with Prio and when. Once we’ve validated that it’s working as expected and provides the privacy guarantees we require, we can move forward in applying it where it is needed most. Expect to hear more from us in future, but for now it’s exciting to be able to take the first step towards privacy preserving data collection.
About Robert Helmer
More articles by Robert Helmer…
About Anthony Miyaguchi
Anthony is a Data Engineer at Mozilla.
More articles by Anthony Miyaguchi…
About Eric Rescorla
Eric is CTO of the Firefox team at Mozilla.