
In October of last year Mozilla announced Project Quantum – our initiative to create a next-generation browser engine. We’re well underway on the project now. We actually shipped our first significant piece of Quantum just last month with Firefox 53.
But, we realize that for people who don’t build web browsers (and that’s most people!), it can be hard to see just why some of the changes we’re making to Firefox are so significant. After all, many of the changes that we’re making will be invisible to users.
With this in mind, we’re kicking off a series of blog posts to provide a deeper look at just what it is we’re doing with Project Quantum. We hope that this series of posts will give you a better understanding of how Firefox works, and the ways in which Firefox is building a next-generation browser engine made to take better advantage of modern computer hardware.
To begin this series of posts, we think it’s best to start by explaining the fundamental thing Quantum is changing.
What is a browser engine, and how does one work?
If we’re going to start from somewhere, we should start from the beginning.
A web browser is a piece of software that loads files (usually from a remote server) and displays them locally, allowing for user interaction.
Quantum is the code name for a project we’ve undertaken at Mozilla to massively upgrade the part of Firefox that figures what to display to users based on those remote files. The industry term for that part is “browser engine”, and without one, you would just be reading code instead of actually seeing a website. Firefox’s browser engine is called Gecko.
It’s pretty easy to see the browser engine as a single black box, sort of like a TV- data goes in, and the black box figures out what to display on the screen to represent that data. The question today is: How? What are the steps that turn data into the web pages we see?

The data that makes up a web page is lots of things, but it’s mostly broken down into 3 parts:
- code that represents the structure of a web page
- code that provides style: the visual appearance of the structure
- code that acts as a script of actions for the browser to take: computing, reacting to user actions, and modifying the structure and style beyond what was loaded initially
The browser engine combines structure and style together to draw the web page on your screen, and figure out which bits of it are interactive.
It all starts with structure. When a browser is asked to load a website, it’s given an address. At this address is another computer which, when contacted, will send data back to the browser. The particulars of how that happens are a whole separate article in themselves, but at the end the browser has the data. This data is sent back in a format called HTML, and it describes the structure of the web page. How does a browser understand HTML?
Browser engines contain special pieces of code called parsers that convert data from one format into another that the browser holds in its memory 1. The HTML parser takes the HTML, something like:
<section>
<h1 class="main-title">Hello!</h1>
<img src="http://example.com/image.png">
</section>
And parses it, understanding:
Okay, there’s a section. Inside the section is a heading of level 1, which itself contains the text: “Hello!” Also inside the section is an image. I can find the image data at the location: http://example.com/image.png
The in-memory structure of the web page is called the Document Object Model, or DOM. As opposed to a long piece of text, the DOM represents a tree of elements of the final web page: the properties of the individual elements, and which elements are inside other elements.

In addition to describing the structure of the page, the HTML also includes addresses where styles and scripts can be found. When the browser finds these, it contacts those addresses and loads their data. That data is then fed to other parsers that specialize in those data formats. If scripts are found, they can modify the page structure and style before the file is finished being parsed. The style format, CSS, plays the next role in our browser engine.
With Style
CSS is a programming language that lets developers describe the appearance of particular elements on a page. CSS stands for “Cascading Style Sheets”, so named because it allows for multiple sets of style instructions, where instructions can override earlier or more general instructions (called the cascade). A bit of CSS could look like the following:
section {
font-size: 15px;
color: #333;
border: 1px solid blue;
}
h1 {
font-size: 2em;
}
.main-title {
font-size: 3em;
}
img {
width: 100%;
}
CSS is largely broken up into groupings called rules, which themselves consist of two parts. The first part is selectors. Selectors describe the elements of the DOM (remember those from above?) being styled, and a list of declarations that specify the styles to be applied to elements that match the selector. The browser engine contains a subsystem called a style engine whose job it is to take the CSS code and apply it to the DOM that was created by the HTML parser.

For example, in the above CSS, we have a rule that targets the selector “section”, which will match any element in the DOM with that name. Style annotations are then made for each element in the DOM. Eventually each element in the DOM is finished being styled, and we call this state the computed style for that element. When multiple competing styles are applied to the same element, those which come later or are more specific wins. Think of stylesheets as layers of thin tracing paper- each layer can cover the previous layers, but also let them show through.
Once the browser engine has computed styles, it’s time to put it to use! The DOM and the computed styles are fed into a layout engine that takes into account the size of the window being drawn into. The layout engine uses various algorithms to take each element and draw a box that will hold its content and take into account all the styles applied to it.
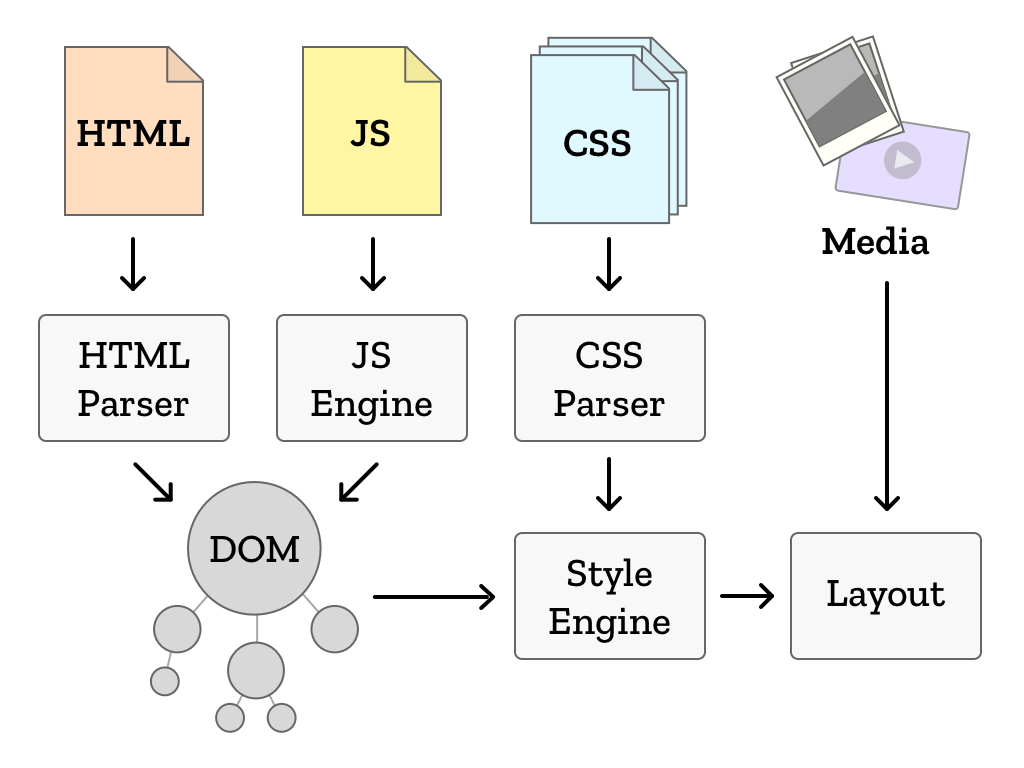
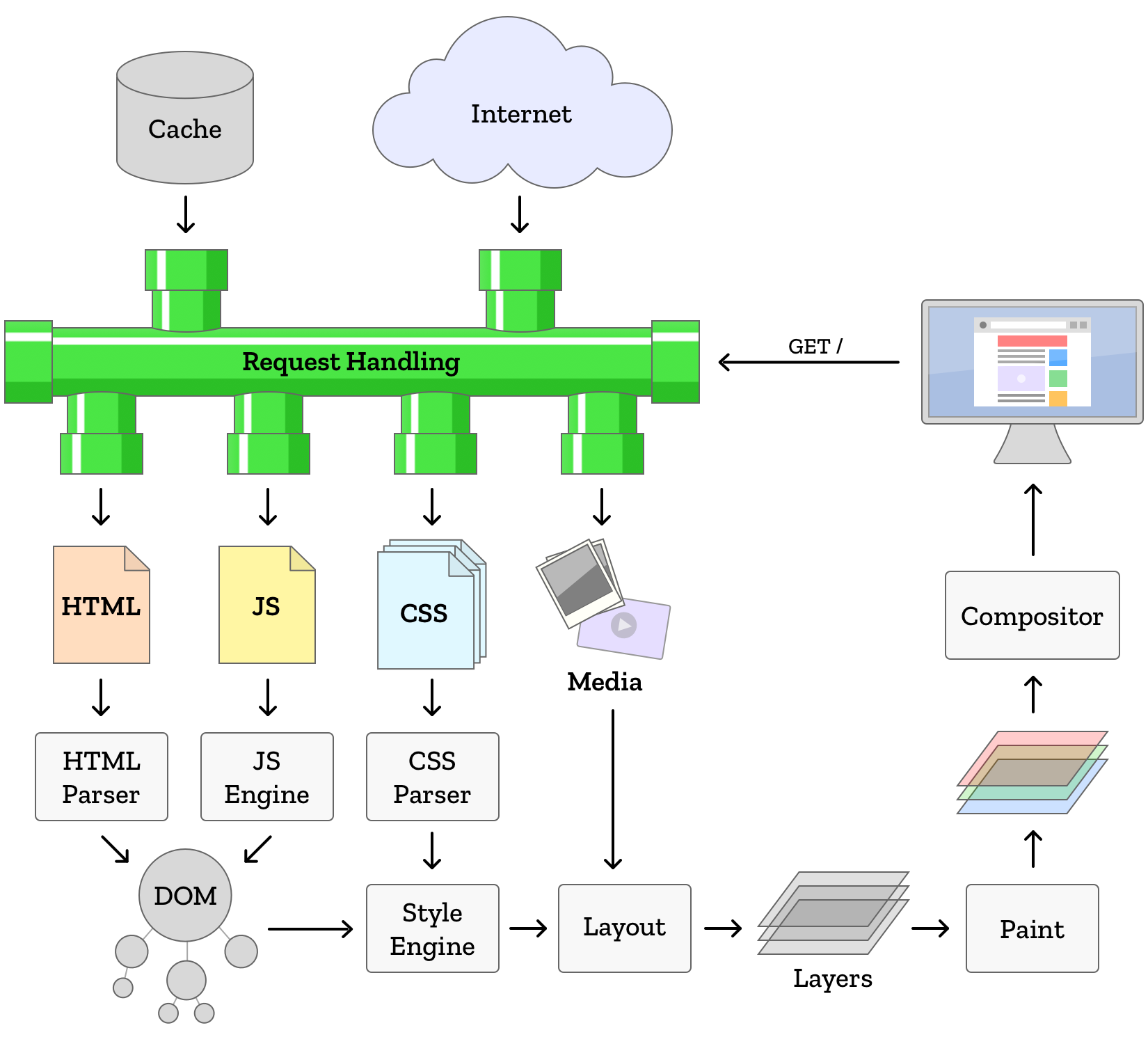
When layout is complete, it’s time to turn the blueprint of the page into the part you see. This process is known as painting, and it is the final combination of all the previous steps. Every box that was defined by layout gets drawn, full of the content from the DOM and with styles from the CSS. The user now sees the page, reconstituted from the code that defines it.
That used to be all that happened!
When the user scrolled the page, we would re-paint, to show the new parts of the page that were previously outside the window. It turns out, however, that users love to scroll! The browser engine can be fairly certain it will be asked to show content outside of the initial window it draws (called the viewport). More modern browsers take advantage of this fact and paint more of the web page than is visible initially. When the user scrolls, the parts of the page they want to see are already drawn and ready. As a result, scrolling can be faster and smoother. This technique is the basis of compositing, which is a term for techniques to reduce the amount of painting required.
Additionally, sometimes we need to redraw parts of the screen. Maybe the user is watching a video that plays at 60 frames per second. Or maybe there’s a slideshow or animated list on the page. Browsers can detect that parts of the page will move or update, and instead of re-painting the whole page, they create a layer to hold that content. A page can be made of many layers that overlap one another. A layer can change position, scroll, transparency, or move behind or in front of other layers without having to re-paint anything! Pretty convenient.
Sometimes a script or an animation changes an element’s style. When this occurs, the style engine need to re-compute the element’s style (and potentially the style of many more elements on the page), recalculate the layout (do a reflow), and re-paint the page. This takes a lot of time as computer-speed things go, but so long as it only happens occasionally, the process won’t negatively affect a user’s experience.
In modern web applications, the structure of the document itself is frequently changed by scripts. This can require the entire rendering process to start more-or-less from scratch, with HTML being parsed into DOM, style calculation, reflow, and paint.
Standards
Not every browser interprets HTML, CSS, and JavaScript the same way. The effect can vary: from small visual differences all the way to the occasional website that works in one browser and not at all in another. These days, on the modern Web, most websites seem to work regardless of which browser you choose. How do browsers achieve this level of consistency?
The formats of website code, as well as the rules that govern how the code is interpreted and turned into an interactive visual page, are defined by mutually-agreed-upon documents called standards. These documents are developed by committees consisting of representatives from browser makers, web developers, designers, and other members of industry. Together they determine the precise behavior a browser engine should exhibit given a specific piece of code. There are standards for HTML, CSS, and JavaScript as well as the data formats of images, video, audio, and more.
Why is this important? It’s possible make a whole new browser engine and, so long as you make sure that your engine follows the standards, the engine will draw web pages in a way that matches all the other browsers, for all the billions of web pages on the Web. This means that the “secret sauce” of making websites work isn’t a secret that belongs to any one browser. Standards allow users to choose the browser that meets their needs.
Moore’s No More
When dinosaurs roamed the earth and people only had desktop computers, it was a relatively safe assumption that computers would only get faster and more powerful. This idea was based on Moore’s Law, an observation that the density of components (and thus miniaturization/efficiency of silicon chips) would double roughly every two years. Incredibly, this observation held true well into the 21st century and, some would argue, still holds true at the cutting edge of research today. So why is it that the speed of the average computer seems to have leveled off in the last 10 years?
Speed is not the only feature customers look for when shopping for a computer. Fast computers can be very power-hungry, very hot, and very expensive. Sometimes, people want a portable computer that has good battery life. Sometimes, they want a tiny touch-screen computer with a camera that fits in their pocket and lasts all day without a charge! Advances in computing have made that possible (which is amazing!), but at the cost of raw speed. Just as it’s not efficient (or safe) to drive your car as fast as possible, it’s not efficient to drive your computer as fast as possible. The solution has been to have multiple “computers” (cores) in one CPU chip. It’s not uncommon to see smartphones with 4 smaller, less powerful cores.
Unfortunately, the historical design of the web browser kind-of assumed this upward trajectory in speed. Also, writing code that’s good at using multiple CPU cores at the same time can be extremely complicated. So, how do we make a fast, efficient browser in the era of lots of small computers?
We have some ideas!
In the upcoming months, we’ll take a closer look at some of changes coming to Firefox and how they will take better advantage of modern hardware to deliver a faster and more stable browser that makes websites shine.
Onward!
[1]: Your brain can do things that are like parsing: the word “eight” is a bunch of letters that spell a word, but you convert them them to the number 8 in your head, not the letters e-i-g-h-t. back
About Potch
Potch is a Web Platform Advocate at Mozilla.
19 comments