
Author’s note: Since this post was written, the API of postMessage has changed slightly. When sending a SharedArrayBuffer with postMessage, the buffer should no longer be in the transfer list argument of the postMessage call. Thus, if sab is a SharedArrayBuffer object and w is a worker, w.postMessage(sab) sends the buffer to the worker.
You can visit MDN’s SharedArrayBuffer documentation for more detail.
TL;DR – We’re extending JavaScript with a primitive API that lets programmers use multiple workers and shared memory to implement true parallel algorithms in JavaScript.
Multicore computation
JavaScript (JS) has grown up, and it works so well that virtually every modern web page contains large amounts of JS code that we don’t ever worry about — it just runs as a matter of course. JS is also being used for more demanding tasks: Client-side image processing (in Facebook and Lightroom) is written in JS; in-browser office packages such as Google Docs are written in JS; and components of Firefox, such as the built-in PDF viewer, pdf.js, and the language classifier, are written in JS. In fact, some of these applications are in the form of asm.js, a simple JS subset, that is a popular target language for C++ compilers; game engines originally written in C++ are being recompiled to JS to run on the web as asm.js programs.
The routine use of JS for these and many other tasks has been made possible by the spectacular performance improvements resulting from the use of Just-in-Time (JIT) compilers in JS engines, and by ever faster CPUs.
But JS JITs are now improving more slowly, and CPU performance improvement has mostly stalled. Instead of faster CPUs, all consumer devices — from desktop systems to smartphones — now have multiple CPUs (really CPU cores), and except at the low end they usually have more than two. A programmer who wants better performance for her program has to start using multiple cores in parallel. That is not a problem for “native” applications, which are all written in multi-threaded programming languages (Java, Swift, C#, and C++), but it is a problem for JS, which has very limited facilities for running on multiple CPUs (web workers, slow message passing, and few ways to avoid data copying).
Hence JS has a problem: if we want JS applications on the web to continue to be viable alternatives to native applications on each platform, we have to give JS the ability to run well on multiple CPUs.
Building Blocks: Shared Memory, Atomics, and Web Workers
Over the last year or so, Mozilla’s JS team has been leading a standards initiative to add building blocks for multicore computation to JS. Other browser vendors have been collaborating with us on this work, and our proposal is going through the stages of the JS standardization process. Our prototype implementation in Mozilla’s JS engine has helped inform the design, and is available in some versions of Firefox as explained below.
In the spirit of the Extensible Web we have chosen to facilitate multicore computation by exposing low-level building blocks that restrict programs as little as possible. The building blocks are a new shared-memory type, atomic operations on shared-memory objects, and a way of distributing shared-memory objects to standard web workers. These ideas are not new; for the high-level background and some history, see Dave Herman’s blog post on the subject.
The new shared memory type, called SharedArrayBuffer, is very similar to the existing ArrayBuffer type; the main difference is that the memory represented by a SharedArrayBuffer can be referenced from multiple agents at the same time. (An agent is either the web page’s main program or one of its web workers.) The sharing is created by transferring the SharedArrayBuffer from one agent to another using postMessage:
let sab = new SharedArrayBuffer(1024)
let w = new Worker("...")
w.postMessage(sab, [sab]) // Transfer the buffer
The worker receives the SharedArrayBuffer in a message:
let mem;
onmessage = function (ev) { mem = ev.data; }
This leads to the following situation where the main program and the worker both reference the same memory, which doesn’t belong to either of them:
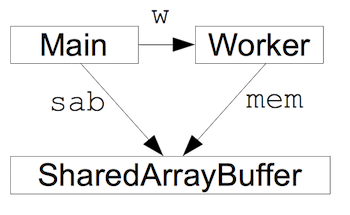
Once a SharedArrayBuffer is shared, every agent that shares it can read and write its memory by creating TypedArray views on the buffer and using standard array access operations on the view. Suppose the worker does this:
let ia = new Int32Array(mem);
ia[0] = 37;
Then the main program can read the cell that was written by the worker, and if it waits until after the worker has written it, it will see the value “37”.
It’s actually tricky for the main program to “wait until after the worker has written the data”. If multiple agents read and write the same locations without coordinating access, then the result will be garbage. New atomic operations, which guarantee that program operations happen in a predictable order and without interruption, make such coordination possible. The atomic operations are present as static methods on a new top-level Atomics object.
Speed and responsiveness
The two performance aspects we can address with multicore computation on the web are speed, i.e., how much work we can get done per unit of time, and responsiveness, i.e., the extent to which the user can interact with the browser while it’s computing.
We improve speed by distributing work onto multiple workers that can run in parallel: If we can divide a computation into four and run it on four workers that each get a dedicated core, we can sometimes quadruple the speed of the computation. We improve responsiveness by moving work out of the main program and into a worker, so that the main program is responsive to UI events even if a computation is ongoing.
Shared memory turns out to be an important building block for two reasons. First, it removes the cost of copying data. For example, if we render a scene on many workers but have to display it from the main program, the rendered scene must be copied to the main program, adding to rendering time and reducing the responsiveness of the main program. Second, shared memory makes coordination among the agents very cheap, much cheaper than postMessage, and that reduces the time that agents sit idle while they are waiting for communication.
No free lunch
It is not always easy to make use of multiple CPU cores. Programs written for a single core must often be significantly restructured and it is often hard to establish the correctness of the restructured program. It can also be hard to get a speedup from multiple cores if the workers need to coordinate their actions frequently. Not all programs will benefit from parallelism.
In addition, there are entirely new types of bugs to deal with in parallel programs. If two workers end up waiting for each other by mistake the program will no longer make progress: the program deadlocks. If workers read and write to the same memory cells without coordinating access, the result is sometimes (and unpredictably, and silently) garbage: the program has data races. Programs with data races are almost always incorrect and unreliable.
An example
NOTE: To run the demos in this post you’ll need Firefox 46 or later. You must also set the preference javascript.options.shared_memory to true in about:config unless you are running Firefox Nightly.
Let’s look at how a program can be parallelized across multiple cores to get a nice speedup. We’ll look at a simple Mandelbrot set animation that computes pixel values into a grid and displays that grid in a canvas, at increasing zoom levels. (Mandelbrot computation is what’s known as “embarrassingly parallel”: it is very easy to get a speedup. Things are usually not this easy.) We’re not going to do a technical deep dive here; see the end for pointers to deeper material.
The reason the shared memory feature is not enabled in Firefox by default is that it is still being considered by the JS standards body. The standardization process must run its course, and the feature may change along the way; we don’t want code on the web to depend on the API yet.
Serial Mandelbrot
Let’s first look briefly at the Mandelbrot program without any kind of parallelism: the computation is part of the main program of the document and renders directly into a canvas. (When you run the demo below you can stop it early, but later frames are slower to render so you only get a reliable frame rate if you let it run to the end.)
If you’re curious, here’s the source code:
Parallel Mandelbrot
Parallel versions of the Mandelbrot program will compute the pixels in parallel into a shared memory grid using multiple workers. The adaptation from the original program is conceptually simple: the mandelbrot function is moved into a web worker program, and we run multiple web workers, each of which computes a horizontal strip of the output. The main program will still be responsible for displaying the grid in the canvas.
We can plot the frame rate (Frames per Second, FPS) for this program against the number of cores used, to get the plot below. The computer used in the measurements is a late-2013 MacBook Pro, with four hyperthreaded cores; I tested with Firefox 46.0.

The program speeds up almost linearly as we go from one to four cores, increasing from 6.9 FPS to 25.4 FPS. After that, the increases are more modest as the program starts running not on new cores but on the hyperthreads on the cores that are already in use. (The hyperthreads on the same core share some of the resources on the core, and there will be some contention for those resources.) But even so the program speeds up by three to four FPS for each hyperthread we add, and with 8 workers the program computes 39.3 FPS, a speedup of 5.7 over running on a single core.
This kind of speedup is very nice, obviously. However, the parallel version is significantly more complicated than the serial version. The complexity has several sources:
- For the parallel version to work properly it needs to synchronize the workers and the main program: the main program must tell the workers when (and what) to compute, and the workers must tell the main program when to display the result. Data can be passed both ways using
postMessage, but it is often better (i.e., faster) to pass data through shared memory, and doing that correctly and efficiently is quite complicated. - Good performance requires a strategy for how to divide the computation among the workers, to make the best use of the workers through load balancing. In the example program, the output image is therefore divided into many more strips than there are workers.
- Finally, there is clutter that stems from shared memory being a flat array of integer values; more complicated data structures in shared memory must be managed manually.
Consider synchronization: The new Atomics object has two methods, wait and wake, which can be used to send a signal from one worker to another: one worker waits for a signal by calling Atomics.wait, and the other worker sends that signal using Atomics.wake. However, these are flexible low-level building blocks; to implement synchronization, the program will additionally have to use atomic operations such as Atomics.load,Atomics.store, and Atomics.compareExchange to read and write state values in shared memory.
Adding further to that complexity, the main thread of a web page is not allowed to call Atomics.wait because it is not good for the main thread to block. So while workers can communicate among themselves using Atomics.wait and Atomics.wake, the main thread must instead listen for an event when it is waiting, and a worker that wants to wake the main thread must post that event with postMessage.
(Those rushing out to test that should know that wait and wake are called futexWait and futexWake in Firefox 46 and Firefox 47. See the MDN page for Atomics for more information.)
It is possible to build good libraries to hide much of the complexity, and if a program — or usually, an important part of a program — can perform significantly better when running on multiple cores rather than on one, then the complexity can really be worth it. However, parallelizing a program is not a quick fix for poor performance.
With the disclaimers above, here is the code for the parallel version:
Further information
For reference material on the available APIs, read the proposed specification, which is largely stable now. The Github repository for the proposal also has some discussion documents that might be helpful.
Additionally, the Mozilla Developer Network (MDN) has documentation for SharedArrayBuffer and Atomics.
About Lars T Hansen
I'm a JavaScript compiler engineer at Mozilla. Previously I worked on ActionScript3 at Adobe and on JavaScript and other browser things at Opera.
26 comments