
This is episode 5, out of a total 12, in the A Node.JS Holiday Season series from Mozilla’s Identity team. For this post, we bring the discussion back to scaling Node.JS applications.
How can you build a Node.JS application that keeps running, even under impossible load?
This post presents a technique and a library that implements that technique, all which is distilled into the following five lines of code:
var toobusy = require('toobusy');
app.use(function(req, res, next) {
if (toobusy()) res.send(503, "I'm busy right now, sorry.");
else next();
});
Why Bother?
If your application is important to people, then it’s worth spending a moment thinking about disaster scenarios. These are the good kind of disasters where your project becomes the apple of social media’s eye and you go from ten thousand users a day to a million. With a bit of preparation you can build a service that can persevere during traffic bursts that exceed capacity by orders of magnitude. If you forego this preparation, then your service will become completely unusable at precisely the wrong time – when everyone is watching.
Another great reason to think about legitimate bursts traffic, is malicious bursts of traffic: the first step to mitigating DoS attacks is building servers that don’t melt.
Your Server Under Load
To illustrate how applications with no considerations for burst behave, I built an application server with an HTTP API that consumes 5ms of processor time spread over five asynchronous function calls. By design, a single instance of this server is capable of handling 200 requests per second.
This roughly approximates a typical request handler that perhaps does some logging, interacts with the database, renders a template, and streams out the result. What follows is a graph of server latency and TCP errors as we linearly increase connection attempts:

Analysis of the data from this run tells a clear story:
This server is not responsive: At 6x maximum capacity (1200 requests/second) the server is hobbled with 40 seconds of average request latency.
These failures suck: With over 80% TCP failures and high latency, users will see a confusing failure after up to a minute of waiting.
Failing Gracefully
Next, I instrumented the same application with the code from the beginning of this post. This code causes the server to detect when load exceeds capacity and preemptively refuse requests. The following graph depicts the performance of this version of the server as we linearly increase connections attempts:
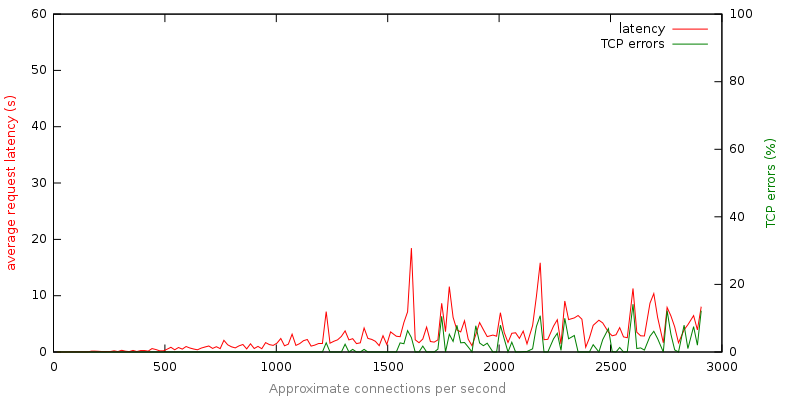
One thing not depicted on the graph is the volume of 503 (server too busy) responses returned during this run which steadily increases proportional to connection attempts. So what do we learn from this graph and the underlying data?
Preemptive limiting adds robustness: Under load that exceeds capacity by an order of magnitude the application continues to behave reasonably.
Success and Failure is fast: Average response time stays for the most part under 10 seconds.
These failures don’t suck: With preemptive limiting we effectively convert slow clumsy failures (TCP timeouts), into fast deliberate failures (immediate 503 responses).
To be clear, building a server that returns HTTP 503 responses (“server is too busy”), requires that your interface render a reasonable message to the user. Typically this is a pretty simple task, and should be familiar as it’s done by many popular sites.
How To Use It
node-toobusy is available on npm and github. After installation (npm install toobusy), simply require it:
var toobusy = require('toobusy');
At the moment the library is included, it will begin actively monitoring the process, and will determine when the process is “too busy”. You can then check if the process is toobusy at key points in your application:
// The absolute first piece of middle-ware we would register, to block requests
// before we spend any time on them.
app.use(function(req, res, next) {
// check if we're toobusy() - note, this call is extremely fast, and returns
// state that is cached at a fixed interval
if (toobusy()) res.send(503, "I'm busy right now, sorry.");
else next();
});
This application of node-toobusy gives you a basic level of robustness at load, which you can tune and customize to fit the design of your application.
How It Works
How do we reliably determine if a Node application is too busy?
This turns out to be more interesting that you might expect, especially when you consider that node-toobusy attempts to work for any node application out of the box. In order to understand the approach taken, let’s review some approaches that don’t work:
Looking at processor usage for the current process: We could use a number like that which you see in top – the percentage of time that the node process has been executing on the processor. Once we had a way of determining this, we could say usage above 90% is “too busy”. This approach fails when you have multiple processes on the machine that are consuming resources and there is not a full single processor available for your node application. In this scenario, your application would never register as “too busy” and would fail terribly – in the way explained above.
Combining system load with current usage: To resolve this issue we could retrieve current system load as well and consider that in our “too busy” determination. We could take the system load and consider the number of available processing cores, and then determine what percentage of a processor is available for our node app! Very quickly this approach becomes complex, requires system specific extensions, and fails to take into account things like process priority.
What we want is a simpler solution that Just Works. This solution should conclude that the node.js process is too busy when it is unable to serve requests in a timely fashion – a criteria that is meaningful regardless of the details of other processes running on the server.
The approach taken by node-toobusy is to measure event loop lag. Recall that Node.JS is at its core an event loop. Work to be done is enqueued, and on each loop iteration is processed. As a node.js process becomes over-loaded, the queue grows and there is more work to be done than can be done. The degree to which a node.js process is overloaded can be understood by determining how long it takes a tiny bit of work to get through the event queue. The node-toobusy library provides libuv with a callback that should be invoked every 500 milliseconds. Subtracting 500ms from the actual time elapsed between invocations gives us a simple measure of event loop lag.
In short, node-toobusy measures event loop lag to determine how busy the host process is, which is a simple and robust technique that works regardless of whatever else is running on the host machine.
Current State
node-toobusy is very new library that makes it easy to build servers that don’t melt by measuring event loop lag: attempting to solve the general problem of determining if a node.js application is too busy. All of the test servers described here as well as the load generation tools used in the post are available on github.
At Mozilla we’re currently evaluating applying this approach to the Persona service, and expect to refine it as we learn. I look forward to your feedback – as a comment on this post, on the identity mailing list, or in github issues.
Previous articles in the series
This was part five in a series with a total of 12 posts about Node.js. The previous ones are:
- Tracking Down Memory Leaks in Node.js
- Fully Loaded Node
- Using secure client-side sessions to build simple and scalable Node.JS applications
- Fantastic front-end performance Part 1 – Concatenate, Compress & Cache
33 comments