
This post was written by David Mandelin who works on Mozilla’s JavaScript team.
Firefox 3.5 has a new JavaScript engine, TraceMonkey, that runs many JavaScript programs 3-4x faster than Firefox 3, speeding up existing web apps and enabling new ones. This article gives a peek under the hood at the major parts of TraceMonkey and how they speed up JS. This will also explain what kinds of programs get the best speedup from TraceMonkey and what kinds of things you can do to get your program to run faster.
Why it’s hard to run JS fast: dynamic typing
High-level dynamic languages such as JavaScript and Python make programming more productive, but they have always been slow compared to statically typed languages like Java or C. A typical rule of thumb was that a JS program might be 10x slower than an equivalent Java program.
There are two main reasons JS and other dynamic scripting languages usually run slower than Java or C. The first reason is that in dynamic languages it is generally not possible to determine the types of values ahead of time. Because of this, the language must store all values in a generic format and process values using generic operations.
In Java, by contrast, the programmer declares types for variables and methods, so the compiler can determine the types of values ahead of time. The compiler can then generate code that uses specialized formats and operations that run much faster than generic operations. I will call these type-specialized operations.
The second main reason that dynamic languages run slower is that scripting languages are usually implemented with interpreters, while statically typed languages are compiled to native code. Interpreters are easier to create, but they incur extra runtime overhead for tracking their internal state. Languages like Java compile to machine language, which requires almost no state tracking overhead.
Let’s make this concrete with a picture. Here are the slowdowns in picture form for a simple numeric add operation: a + b, where a and b are integers. For now, ignore the rightmost bar and focus on the comparison of the Firefox 3 JavaScript interpreter vs. a Java JIT. Each column shows the steps that have to be done to complete the add operation in each programming language. Time goes downward, and the height of each box is proportional to the time it takes to finish the steps in the box.
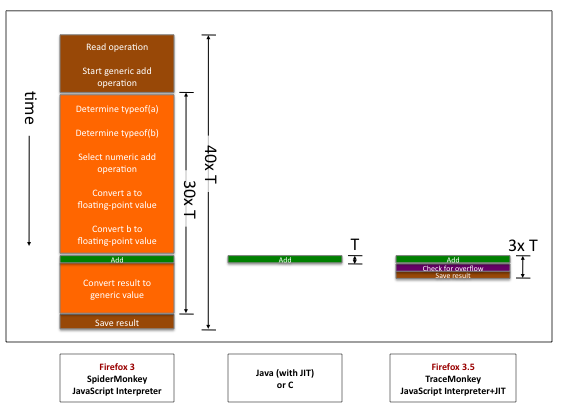
In the middle, Java simply runs one machine language add instruction, which runs in time T (one processor cycle). Because the Java compiler knows that the operands are standard machine integers, it can use a standard integer add machine language instruction. That’s it.
On the left, SpiderMonkey (the JS interpreter in FF3) takes about 40 times as long. The brown boxes are interpreter overhead: the interpreter must read the add operation and jump to the interpreter’s code for a generic add. The orange boxes represent extra work that has to be done because the interpreter doesn’t know the operand types. The interpreter has to unpack the generic representations of a and i, figure out their types, select the specific addition operation, convert the values to the right types, and at the end, convert the result back to a generic format.
The diagram shows that using an interpreter instead of a compiler is slowing things down a little bit, but not having type information is slowing things down a lot. If we want JS to run more than a little faster than in FF3, by Amdahl’s law, we need to do something about types.
Getting types by tracing
Our goal in TraceMonkey is to compile type-specialized code. To do that, TraceMonkey needs to know the types of variables. But JavaScript doesn’t have type declarations, and we also said that it’s practically impossible for a JS engine to figure out the types ahead of time. So if we want to just compile everything ahead of time, we’re stuck.
So let’s turn the problem around. If we let the program run for a bit in an interpreter, the engine can directly observe the types of values. Then, the engine can use those types to compile fast type-specialized code. Finally, the engine can start running the type-specialized code, and it will run much faster.
There are a few key details about this idea. First, when the program runs, even if there are many if statements and other branches, the program always goes only one way. So the engine doesn’t get to observe types for a whole method — the engine observes types through the paths, which we call traces, that the program actually takes. Thus, while standard compilers compile methods, TraceMonkey compiles traces. One side benefit of trace-at-a-time compilation is that function calls that happen on a trace are inlined, making traced function calls very fast.
Second, compiling type-specialized code takes time. If a piece of code is going to run only one or a few times, which is common with web code, it can easily take more time to compile and run the code than it would take to simply run the code in an interpreter. So it only pays to compile hot code (code that is executed many times). In TraceMonkey, we arrange this by tracing only loops. TraceMonkey initially runs everything in the interpreter, and starts recording traces through a loop once it gets hot (runs more than a few times).
Tracing only hot loops has an important consequence: code that runs only a few times won’t speed up in TraceMonkey. Note that this usually doesn’t matter in practice, because code that runs only a few times usually runs too fast to be noticeable. Another consequence is that paths through a loop that are not taken at all never need to be compiled, saving compile time.
Finally, above we said that TraceMonkey figures out the types of values by observing execution, but as we all know, past performance does not guarantee future results: the types might be different the next time the code is run, or the 500th next time. And if we try to run code that was compiled for numbers when the values are actually strings, very bad things will happen. So TraceMonkey must insert type checks into the compiled code. If a check doesn’t pass, TraceMonkey must leave the current trace and compile a new trace for the new types. This means that code with many branches or type changes tends to run a little slower in TraceMonkey, because it takes time to compile the extra traces and jump from one to another.
TraceMonkey in action
Now, we’ll show tracing in action by example on this sample program, which adds the first N whole numbers to a starting value:
function addTo(a, n) {
for (var i = 0; i < n; ++i)
a = a + i;
return a;
}
var t0 = new Date();
var n = addTo(0, 10000000);
print(n);
print(new Date() - t0);
TraceMonkey always starts running the program in the interpreter. Every time the program starts a loop iteration, TraceMonkey briefly enters monitoring mode to increment a counter for that loop. In FF3.5, when the counter reaches 2, the loop is considered hot and it's time to trace.
Now TraceMonkey continues running in the interpreter but starts recording a trace as the code runs. The trace is simply the code that runs up to the end of the loop, along with the types used. The types are determined by looking at the actual values. In our example, the loop executes this sequence of JavaScript statements, which becomes our trace:
a = a + i; // a is an integer number (0 before, 1 after)
++i; // i is an integer number (1 before, 2 after)
if (!(i < n)) // n is an integer number (10000000)
break;
That's what the trace looks like in a JavaScript-like notation. But TraceMonkey needs more information in order to compile the trace. The real trace looks more like this:
trace_1_start:
++i; // i is an integer number (0 before, 1 after)
temp = a + i; // a is an integer number (1 before, 2 after)
if (lastOperationOverflowed())
exit_trace(OVERFLOWED);
a = temp;
if (!(i < n)) // n is an integer number (10000000)
exit_trace(BRANCHED);
goto trace_1_start;
This trace represents a loop, and it should be compiled as a loop, so we express that directly using a goto. Also, integer addition can overflow, which requires special handling (for example, redoing with floating-point addition), which in turn requires exiting the trace. So the trace must include an overflow check. Finally, the trace exits in the same way if the loop condition is false. The exit codes tell TraceMonkey why the trace was exited, so that TraceMonkey can decide what to do next (such as whether to redo the add or exit the loop). Note that traces are recorded in a special internal format that is never exposed to the programmer — the notation used above is just for expository purposes.
After recording, the trace is ready to be compiled to type-specialized machine code. This compilation is performed by a tiny JIT compiler (named, appropriately enough, nanojit) and the results are stored in memory, ready to be executed by the CPU.
The next time the interpreter passes the loop header, TraceMonkey will start executing the compiled trace. The program now runs very fast.
On iteration 65537, the integer addition will overflow. (2147450880 + 65537 = 2147516417, which is greater than 2^31-1 = 2147483647, the largest signed 32-bit integer.) At this point, the trace exits with an OVERFLOWED code. Seeing this, TraceMonkey will return to interpreter mode and redo the addition. Because the interpreter does everything generically, the addition overflow is handled and everything works as normal. TraceMonkey will also start monitoring this exit point, and if the overflow exit point ever becomes hot, a new trace will be started from that point.
But in this particular program, what happens instead is that the program passes the loop header again. TraceMonkey knows it has a trace for this point, but TraceMonkey also knows it can't use that trace because that trace was for integer values, but a is now in a floating-point format. So TraceMonkey records a new trace:
trace_2_start:
++i; // i is an integer number
a = a + i; // a is a floating-point number
if (!(i < n)) // n is an integer number (10000000)
exit_trace(BRANCHED);
goto trace_2_start;
TraceMonkey then compiles the new trace, and on the next loop iteration, starts executing it. In this way, TraceMonkey keeps the JavaScript running as machine code, even when types change. Eventually the trace will exit with a BRANCHED code. At this point, TraceMonkey will return to the interpreter, which takes over and finishes running the program.
Here are the run times for this program on my laptop (2.2GHz MacBook Pro):
| System | Run Time (ms) |
| SpiderMonkey (FF3) | 990 |
| TraceMonkey (FF3.5) | 45 |
| Java (using int) | 25 |
| Java (using double) | 74 |
| C (using int) | 5 |
| C (using double) | 15 |
This program gets a huge 22x speedup from tracing and runs about as fast as Java! Functions that do simple arithmetic inside loops usually get big speedups from tracing. Many of the bit operation and math SunSpider benchmarks, such bitops-3bit-bits-in-byte, ctrypto-sha1, and math-spectral-norm get 6x-22x speedups.
Functions that use more complex operations, such as object manipulation, get a smaller speedup, usually 2-5x. This follows mathematically from Amdahl's law and the fact that complex operations take longer. Looking back at the time diagram, consider a more complex operation that takes time 30T for the green part. The orange and brown parts will still be about 30T together, so eliminating them gives a 2x speedup. The SunSpider benchmark string-fasta is an example of this kind of program: most of the time is taken by string operations that have a relatively long time for the green box.
Here is a version of our example program you can try in the browser:
Numerical result:
Run time:
Average run time:
Understanding and fixing performance problems
Our goal is to make TraceMonkey reliably fast enough that you can write your code in the way that best expresses your ideas, without worrying about performance. If TraceMonkey isn't speeding up your program, we hope you'll report it as a bug so we can improve the engine. That said, of course, you may need your program to run faster in today's FF3.5. In this section, we'll explain some tools and techniques for fixing performance of a program that doesn't get a good (2x or more) speedup with the tracing JIT enabled. (You can disable the jit by going to about:config and setting the pref javascript.options.jit.content to false.)
The first step is understanding the cause of the problem. The most common cause is a trace abort, which simply means that TraceMonkey was unable to finish recording a trace, and gave up. The usual result is that the loop containing the abort will run in the interpreter, so you won't get a speedup on that loop. Sometimes, one path through the loop is traced, but there is an abort on another path, which will cause TraceMonkey to switch back and forth between interpreting and running native code. This can leave you with a reduced speedup, no speedup, or even a slowdown: switching modes takes time, so rapid switching can lead to poor performance.
With a debug build of the browser or a JS shell (which I build myself - we don't publish these builds) you can tell TraceMonkey to print information about aborts by setting the TMFLAGS environment variable. I usually do it like this:
TMFLAGS=minimal,abort dist/MinefieldDebug.app/Contents/MacOS/firefox
The minimal option prints out all the points where recording starts and where recording successfully finishes. This gives a basic idea of what the tracer is trying to do. The abort option prints out all the points where recording was aborted due to an unsupported construct. (Setting TMFLAGS=help will print the list of other TMFLAGS options and then exit.)
(Note also that TMFLAGS is the new way to print the debug information. If you are using a debug build of the FF3.5 release, the environment variable setting is TRACEMONKEY=abort.)
Here's an example program that doesn't get much of a speedup in TraceMonkey.
function runExample2() {
var t0 = new Date;
var sum = 0;
for (var i = 0; i < 100000; ++i) {
sum += i;
}
var prod = 1;
for (var i = 1; i < 100000; ++i) {
eval("prod *= i");
}
var dt = new Date - t0;
document.getElementById(example2_time').innerHTML = dt + ' ms';
}
Run time:
If we set TMFLAGS=minimal,abort, we'll get this:
Recording starting from ab.js:5@23
recording completed at ab.js:5@23 via closeLoop
Recording starting from ab.js:5@23
recording completed at ab.js:5@23 via closeLoop
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
Recording starting from ab.js:10@63
Abort recording of tree ab.js:10@63 at ab.js:11@70: eval.
The first two pairs of lines show that the first loop, starting at line 5, traced fine. The following lines showed that TraceMonkey started tracing the loop on line 10, but failed each time because of an eval.
An important note about this debug output is that you will typically see some messages referring to inner trees growing, stabilizing, and so on. These really aren't problems: they usually just indicate a delay in finishing tracing a loop because of the way TraceMonkey links inner and outer loops. And in fact, if you look further down the output after such aborts, you will usually see that the loops eventually do trace.
Otherwise, aborts are mainly caused by JavaScript constructs that are not yet supported by tracing. The trace recording process is easier to implement for a basic operation like + than it is for an advanced feature like arguments. We didn't have time to do robust, secure tracing of every last JavaScript feature in time for the FF3.5 release, so some of the more advanced ones, like arguments, aren't traced in FF3.5.0. Other advanced features that are not traced include getters and setters, with, and eval. There is partial support for closures, depending on exactly how they are used. Refactoring to avoid these constructs can help performance.
Two particularly important JavaScript features that are not traced are:
- Recursion. TraceMonkey doesn't see repetition that occurs through recursion as a loop, so it doesn't try to trace it. Refactoring to use explicit
fororwhileloops will generally give better performance. - Getting or setting a DOM property. (DOM method calls are fine.) Avoiding these constructs is generally impossible, but refactoring the code to move DOM property access out of hot loops and performance-critical segments should help.
We are actively working on tracing all the features named above. For example, support for tracing arguments is already available in nightly builds.
Here is the slow example program refactored to avoid eval. Of course, I could have simply done the multiplication inline. Instead, I used a function created by eval because that's a more general way of refactoring an eval. Note that the eval still can't be traced, but it only runs once so it doesn't matter.
function runExample3() {
var t0 = new Date;
var sum = 0;
for (var i = 0; i < 100000; ++i) {
sum += i;
}
var prod = 1;
var mul = eval("(function(i) { return prod * i; })");
for (var i = 1; i < 100000; ++i) {
prod = mul(i);
}
var dt = new Date - t0;
document.getElementById('example3_time').innerHTML = dt + ' ms';
}
Run time:
There are a few more esoteric situations that can also hurt tracing performance. One of them is trace explosion, which happens when a loop has many paths through it. Consider a loop with 10 if statements in a row: the loop has 1024 paths, potentially causing 1024 traces to be recorded. That would use up too much memory, so TraceMonkey caps each loop at 32 traces. If the loop has fewer than 32 hot traces, it will perform well. But if each path occurs with equal frequency, then only 3% of the paths are traced, and performance will suffer.
This kind of problem is best analyzed with TraceVis, which creates visualizations of TraceMonkey performance. Currently, the build system only supports enabling TraceVis for shell builds, but the basic system can also run in the browser, and there is ongoing work to enable TraceVis in a convenient form in the browser.
The blog post on TraceVis is currently the most detailed explanation of what the diagrams mean and how to use them to diagnose performance problems. The post also contains a detailed analysis of a diagram that is helpful in understanding how TraceMonkey works in general.
Comparative JITerature
Here I will give a few comparisons to other JavaScript JIT designs. I'll focus more on hypothetical designs than competing engines, because I don't know details about them — I've read the release information and skimmed a few bits of code. Another big caveat is that real-world performance depends at least as much on engineering details as it does on engine architecture.
One design option could be a called a per-method non-specializing JIT. By this, I mean a JIT compiler that compiles a method at a time and generates generic code, just like what the interpreter does. Thus, the brown boxes from our diagrams are cut out. This kind of JIT doesn't need to take time to record and compile traces, but it also does not type-specialize, so the orange boxes remain. Such an engine can still be made pretty fast by carefully designing and optimizing the orange box code. But the orange box can't be completely eliminated in this design, so the maximum performance on numeric programs won't be as good as a type-specializing engine.
As far as I can tell, as of this writing Nitro and V8 are both lightweight non-specializing JITs. (I'm told that V8 does try to guess a few types by looking at the source code (such as guessing that a is an integer in a >> 2) in order to do a bit of type specialization.) It seem that TraceMonkey is generally faster on numeric benchmarks, as predicted above. But TraceMonkey suffers a bit on benchmarks that use more objects, because our object operations and memory management haven't been optimized as heavily.
A further development of the basic JIT is the per-method type-specializing JIT. This kind of a JIT tries to type-specialize a method based on the argument types the method is called with. Like TraceMonkey, this requires some runtime observation: the basic design checks the argument types each time a method is called, and if those types have not been seen before, compiles a new version of the method. Also like TraceMonkey, this design can heavily specialize code and remove both the brown and orange boxes.
I'm not aware that anyone has deployed a per-method type-specializing JIT for JavaScript, but I wouldn't be surprised if people are working on it.
The main disadvantage of a per-method type-specializing JIT compared to a tracing JIT is that the basic per-method JIT only directly observes the input types to a method. It must try to infer types for variables inside the method algorithmically, which is difficult for JavaScript, especially if the method reads object properties. Thus, I would expect that a per-method type-specializing JIT would have to use generic operations for some parts of the method. The main advantage of the per-method design is that the method needs to be compiled exactly once per set of input types, so it's not vulnerable to trace explosion. In turn, I think a per-method JIT would tend to be faster on methods that have many paths, and a tracing JIT would tend to be faster on highly type-specializable methods, especially if the method also reads a lot of values from properties.
Conclusion
By now, hopefully you have a good idea of what makes JavaScript engines fast, how TraceMonkey works, and how to analyze and fix some performance issues that may occur running JavaScript under TraceMonkey. Please report bugs if you run into any significant performance problems. Bug reports are also a good place for us to give additional tuning advice. Finally, we're trying to improve constantly, so check out nightly TraceMonkey builds if you're into the bleeding edge.
68 comments